近日,Nanonets 宣布推出一款全新的 OCR 模型 Nanonets-OCR-s ——这是一款专为大语言模型(LLMs)设计的图像转 Markdown 工具,具备强大的文档理解与结构化输出能力。
- 模型:https://huggingface.co/nanonets/Nanonets-OCR-s
- Demo:https://huggingface.co/spaces/Souvik3333/Nanonets-ocr-s
不同于传统仅提取纯文本的 OCR 系统,Nanonets-OCR-s 能识别并结构化处理数学公式、图表、签名、复选框、水印以及复杂表格等元素,将非结构化文档转化为 LLM 可直接使用的 Markdown 格式。

这一突破性模型为法律、学术、医疗、金融等多个行业的文档自动化流程提供了强大支持。
核心功能亮点
1. LaTeX 方程识别
自动识别图像中的数学表达式,并将其转换为标准的 LaTeX 语法。可区分:
- 内联方程 →
$...$ - 展示方程 →
$$...$$
这对科研论文和教学材料的数字化尤为重要。
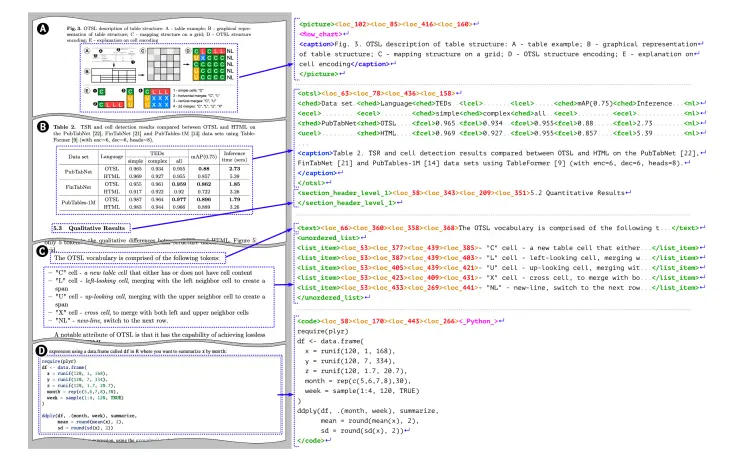
2. 智能图像描述
使用 <img> 标签对图像内容进行语义级描述,包括图像类型(如图表、LOGO、QR码)、风格与上下文信息,便于 LLM 进一步分析。
3. 签名检测与隔离
从文档中识别出签名区域,并单独标记为 <signature>,特别适用于合同、授权书等法律文书的结构化提取。
4. 水印提取
识别并提取页面中的水印内容,标记为 <watermark>,确保文档来源与版权信息不被遗漏。
5. 智能复选框处理
将表单中的复选框与单选按钮统一转换为标准化 Unicode 符号(☐、☑、☒),提升数据一致性与机器处理可靠性。
6. 复杂表格提取
准确识别多列、跨页、合并单元格等复杂表格,并输出为 Markdown 或 HTML 表格格式,极大简化结构化数据提取流程。
为何选择 Nanonets-OCR-s?
大多数现有 OCR 工具只能提取纯文本,无法有效区分图像、签名、页码或复选框等元素,导致输出内容难以用于下游 AI 处理。
而 Nanonets-OCR-s 的目标是:
“不仅提取文字,更要理解文档结构。”
通过智能语义标签系统,它将原始图像文档转化为富含结构信息的 Markdown 文件,非常适合后续由 LLM 进行进一步理解和推理。
训练背景与技术细节
该模型基于一个包含 超过 25 万页文档 的多样化训练集构建,涵盖:
- 学术论文
- 财务报表
- 法律合同
- 医疗表单
- 税务发票
- 收据等
训练分为两个阶段:
- 合成数据预训练
- 人工标注数据微调
模型以 Qwen2.5-VL-3B 作为基础视觉-语言模型(VLM),在特定任务上进行了深度优化,显著提升了文档识别精度。
当前局限性
尽管 Nanonets-OCR-s 功能强大,但仍存在以下限制:
- 未针对手写文本训练,对手写体识别效果有限;
- 可能出现幻觉现象,即生成不符合原图内容的标签,需结合人工校验使用。
典型应用场景
Nanonets-OCR-s 在多个行业具有广泛的应用潜力:
- 学术研究:快速提取论文中的公式、图表与表格,助力知识检索;
- 法律与金融:结构化处理合同、财务报告、贷款申请表等关键文档;
- 医疗健康:从病历、处方中提取结构化信息,辅助电子病历系统;
- 企业办公:将纸质报告扫描后直接转为可搜索、可编辑的知识库。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











