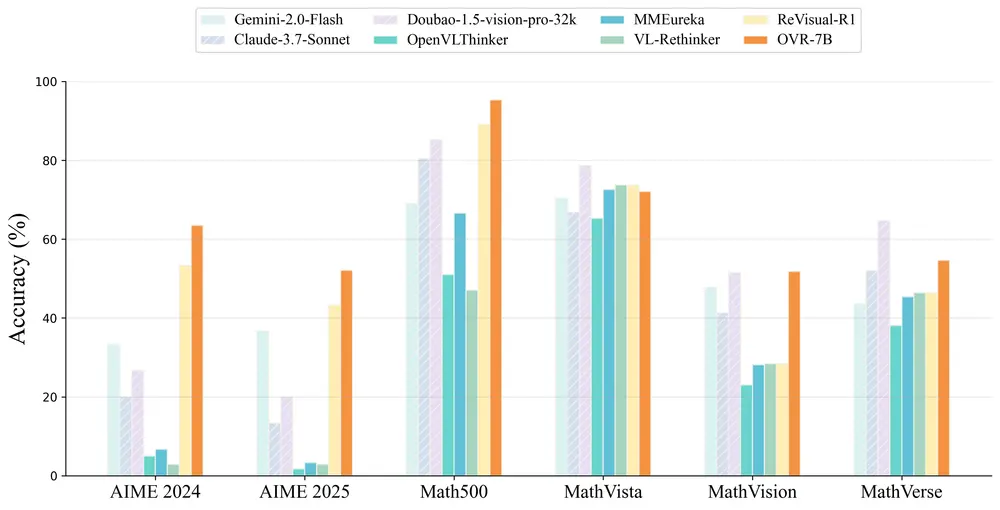
Open-Vision-Reasoner(OVR):基于语言认知迁移的多模态视觉推理新范式大语言模型(LLMs)之所以具备强大的推理能力,关键在于其通过可验证奖励机制的强化学习所涌现的认知行为。那么,是否可以将这一原则迁移至多模态大语言模型(MLLMs),从而解锁其高级视觉推理能力? 本研...多模态模型# Open-Vision-Reasoner# 多模态大语言模型7个月前02750
像素空间推理视觉语言模型Pixel Reasoner:引入像素空间推理的概念,显著提升了视觉语言模型在视觉密集型任务中的表现中国科学技术大学、香港科技大学和滑铁卢大学的研究人员推出基于 Qwen2 的开源视觉语言模型Pixel Reasoner,它通过引入像素空间推理(pixel-space reasoning)的概念,显...多模态模型# Pixel Reasoner# 视觉语言模型8个月前02750
新型多模态大语言模型Sa2VA:将 SAM2 与 LLaVA相结合,实现对图像和视频的深入理解加州大学默塞德分校、字节跳动、武汉大学和北京大学的研究人员推出新型多模态大语言模型Sa2VA,它将SAM-2视频分割模型与LLaVA视觉-语言模型相结合,实现了对图像和视频的密集、基于语义的理解。Sa...多模态模型# Sa2VA# 多模态大语言模型12个月前02740
多模态大语言模型ChatRex:提升对人类姿态的感知和理解能力IDEA的研究人员推出多模态大语言模型ChatRex,它旨在提升对人类姿态的感知和理解能力。ChatRex通过结合视觉和语言模型,能够执行多种与人体姿态相关任务,包括姿态理解、生成和编辑。这个模型特别...多模态模型# ChatRex# 多模态大语言模型12个月前02730
谷歌推出"功能强大的图像安全检查器"ShieldGemma2去年,谷歌发布了 ShieldGemma,这是一套基于 Gemma 2 构建的安全内容分类器模型,旨在检测 AI 模型文本输入和输出中的有害内容。今天,随着 Gemma 3 的亮相,谷歌宣布推出Shi...多模态模型# Gemma 2# Gemma 3# ShieldGemma 211个月前02720
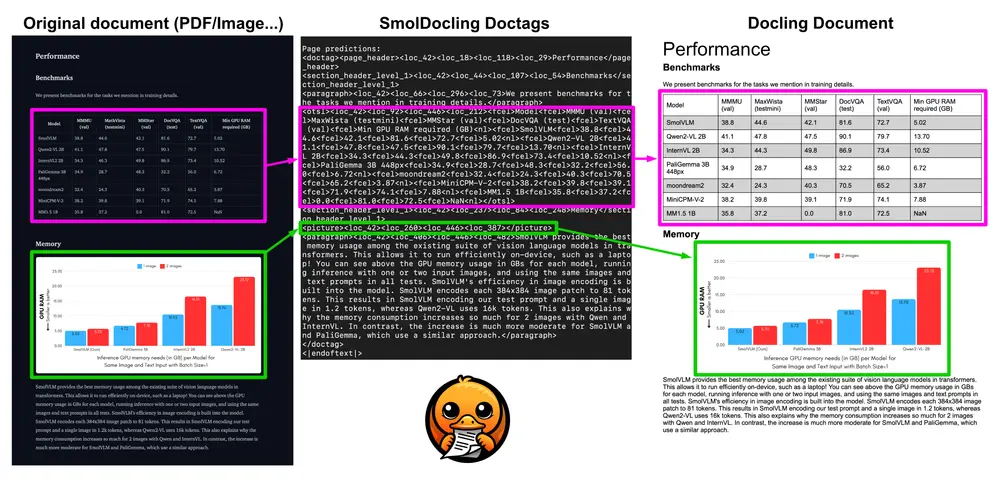
Hugging Face发布号称同类最小的多模态模型SmolVLM系列Hugging Face团队最近发布了两款名为SmolVLM-256M和SmolVLM-500M的新模型,它们被宣称为能够分析图像、短视频以及文本的最小AI模型。这两款模型特别设计用于在资源受限的设备...多模态模型# Hugging Face# SmolVLM12个月前02720
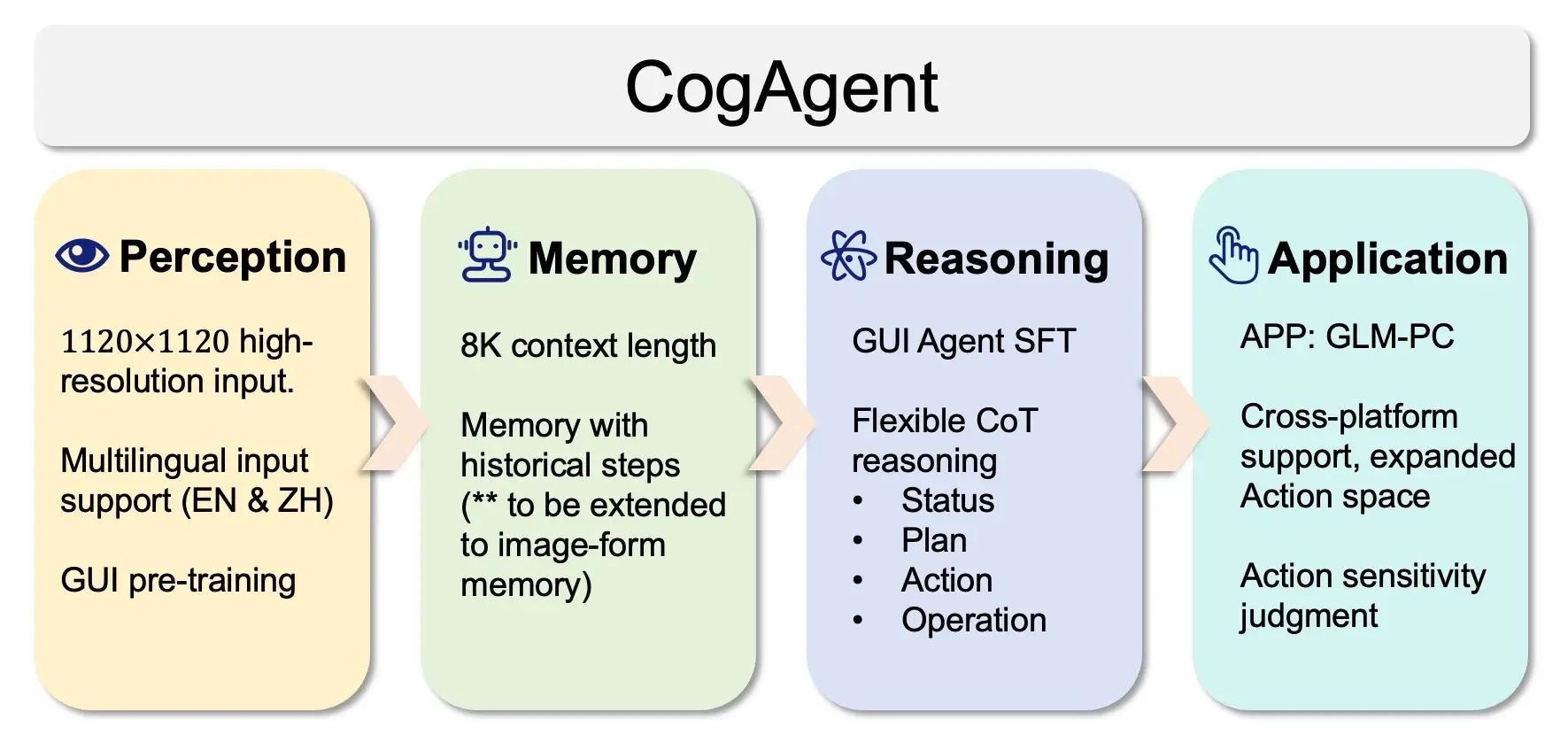
CogAgent-9B-20241220:基于视觉语言模型的开源 GUI agent 模型图形用户界面(GUI)是用户与软件交互的核心。然而,构建能够有效导航GUI的智能代理一直是一个持续的挑战。传统方法在适应性方面存在不足,尤其是在处理复杂布局或GUI频繁变化时,这些问题限制了自动化GU...多模态模型# CogAgent-9B-2024122012个月前02720
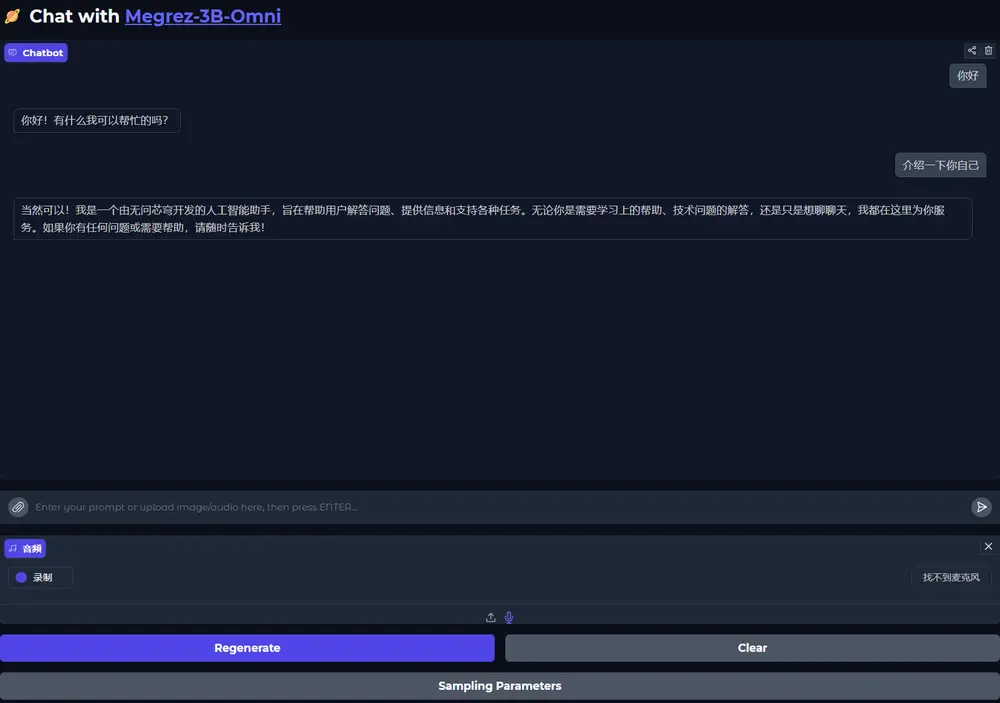
无问芯穹推出全球首个端侧全模态理解开源模型Megrez-3B-Omni12月16日,无问芯穹宣布正式开源其“端模型+端软件+端IP”端上智能一体化解决方案中的小模型——Megrez-3B-Omni,以及纯语言版本模型 Megrez-3B-Instruct。这一举措标志着...多模态模型# Megrez-3B-Omni# 无问芯穹12个月前02690
浙大 × 通义实验室提出 UI-S1:用“半在线”训练让 MLLM 更懂图形界面在手机上完成一连串操作——比如从微信复制一段文字,粘贴到备忘录,再分享给钉钉好友——对人类来说是日常小事。但对 AI 来说,这是一次复杂的多步决策挑战。 近年来,基于多模态大语言模型(MLLM)的 G...多模态模型# UI-S1# 多模态大语言模型5个月前02650
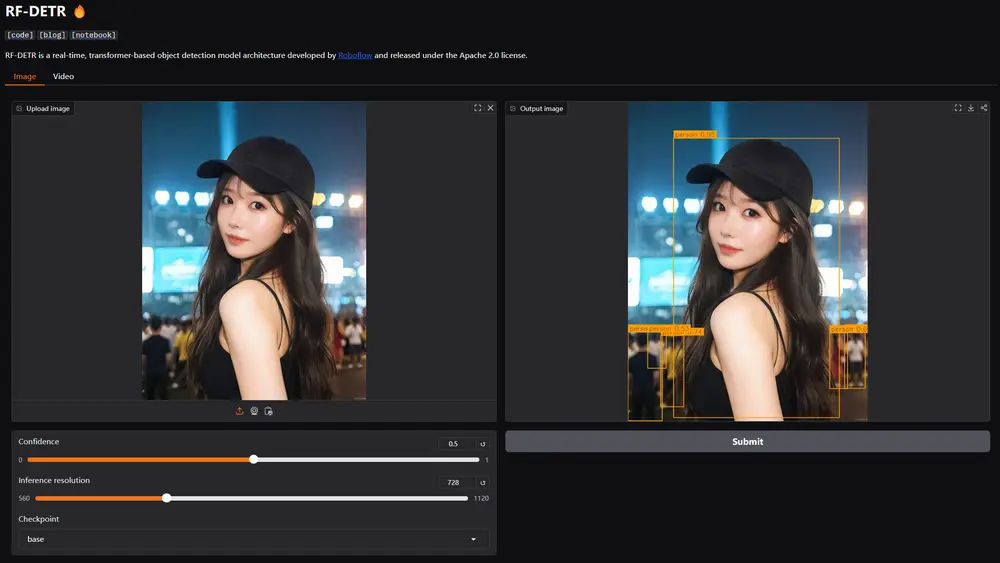
Roboflow开源基于Transformer的实时目标检测模型 RF-DETRRoboflow 近日正式发布了 RF-DETR,一种基于Transformer的实时目标检测模型。RF-DETR 在多个现实世界数据集上的表现超越了所有现有的目标检测模型,并且是首个在 COCO 数...多模态模型# RF-DETR# Roboflow# 实时目标检测模型10个月前02650
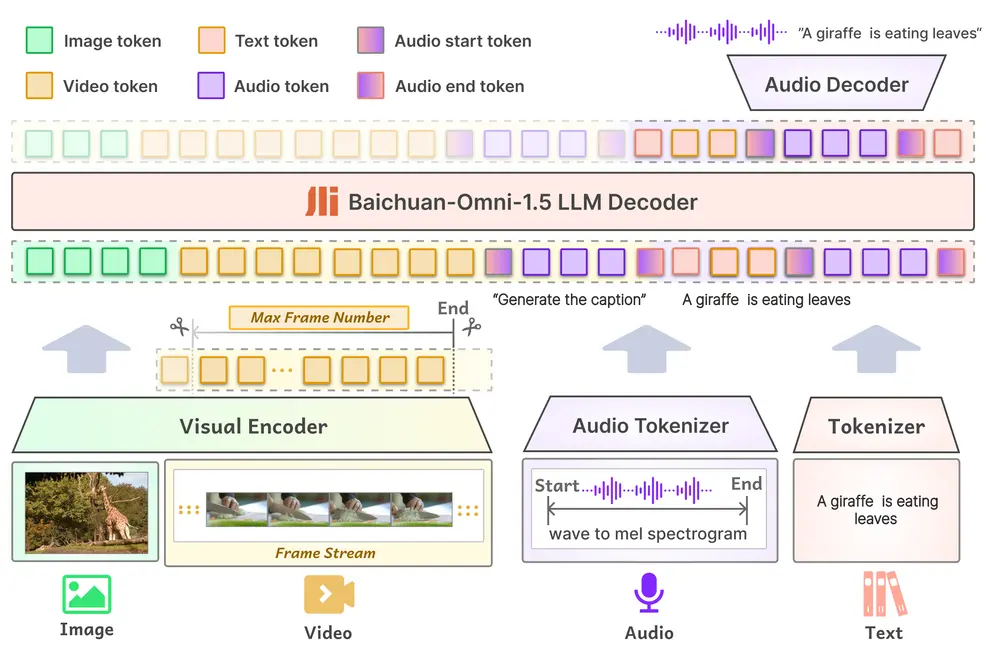
百川智能发布全模态开源模型Baichuan-Omni-1.5百川智能宣布其最新研发的Baichuan-Omni-1.5开源全模态模型正式上线。这款模型支持文本、图像、音频和视频等多种格式的数据处理,并具备文本与音频的双模态生成能力。Baichuan-Omni...多模态模型# Baichuan-Omni-1.5# 百川智能12个月前02650
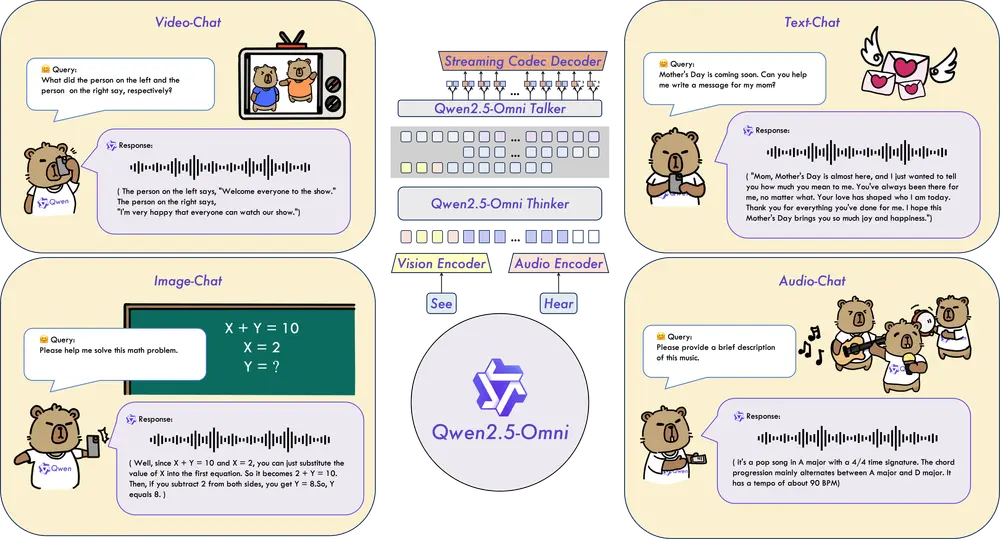
阿里通义实验室发布新一代端到端多模态旗舰模型Qwen2.5-Omni阿里通义实验室发布了 Qwen2.5-Omni,这是 Qwen 模型家族中的新一代端到端多模态旗舰模型。Qwen2.5-Omni 专为全方位多模态感知设计,能够无缝处理文本、图像、音频和视频等多种输入...多模态模型# Qwen2.5-Omni# 多模态模型10个月前02630