阿里巴巴 Qwen 推出紧凑型多模态模型 Qwen3-VL 4B/8B,支持 FP8 低显存部署阿里巴巴通义千问(Qwen)团队于 2025 年 10 月 15 日正式发布 Qwen3-VL 4B 与 8B 两款稠密视觉语言模型,每款均提供 指令版(Instruction) 与 思维版(Reas...多模态模型# Qwen3-VL 4B# Qwen3-VL 8B# 多模态模型4个月前02620
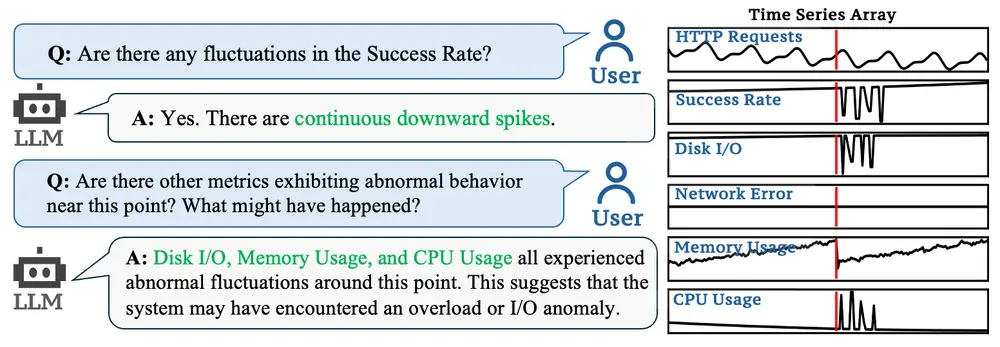
字节跳动推出多模态大语言模型ChatTS:专门用于时间序列分析清华大学和字节跳动的研究人员推出多模态大语言模型ChatTS ,专门用于时间序列分析。它通过自然语言命令帮助用户快速理解时间序列数据,执行日常任务,并处理复杂的推理问题。ChatTS 的核心优势在于其...多模态模型# ChatTS# 多模态大语言模型# 字节跳动10个月前02620
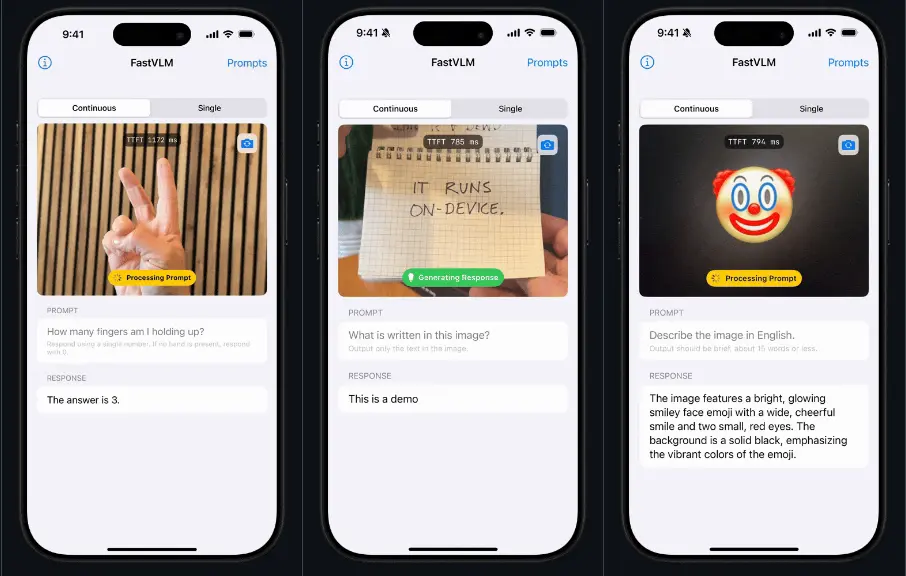
苹果推出高效视觉语言模型FastVLM:通过优化视觉编码器来提高模型在处理高分辨率图像任务时的效率和性能苹果推出一种高效视觉语言模型FastVLM,旨在通过优化视觉编码器(Vision Encoder)来提高模型在处理高分辨率图像任务时的效率和性能。FastVLM的核心是其创新的视觉编码器 FastVi...多模态模型# FastVLM# 苹果# 视觉语言模型9个月前02600
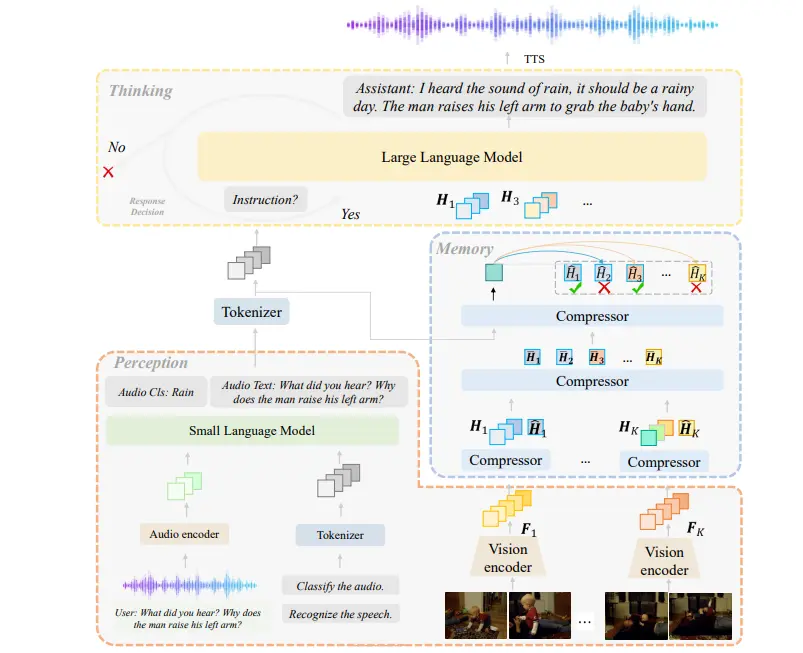
字节跳动推出具备长期记忆的多模态智能体 M3-Agent字节跳动 Seed 团队推出新型多模态智能体框架M3-Agent ,首次实现了以实体为中心、支持长期记忆积累的自主推理能力。 项目主页:https://m3-agent.github.io GitHu...多模态模型# M3-Agent# 多模态智能体# 字节跳动6个月前02580
用于 GUI 自动化的视觉代理模型ShowUI:结合了视觉、语言和行动能力,提高人机交互的效率和生产力新加坡国立大学和微软的研究人员推出用于 GUI(图形用户界面) 自动化的视觉代理模型ShowUI ,它是一个结合了视觉、语言和行动能力的大模型,旨在提高人机交互的效率和生产力。ShowUI通过理解和执...多模态模型# ShowUI# 视觉代理模型12个月前02580
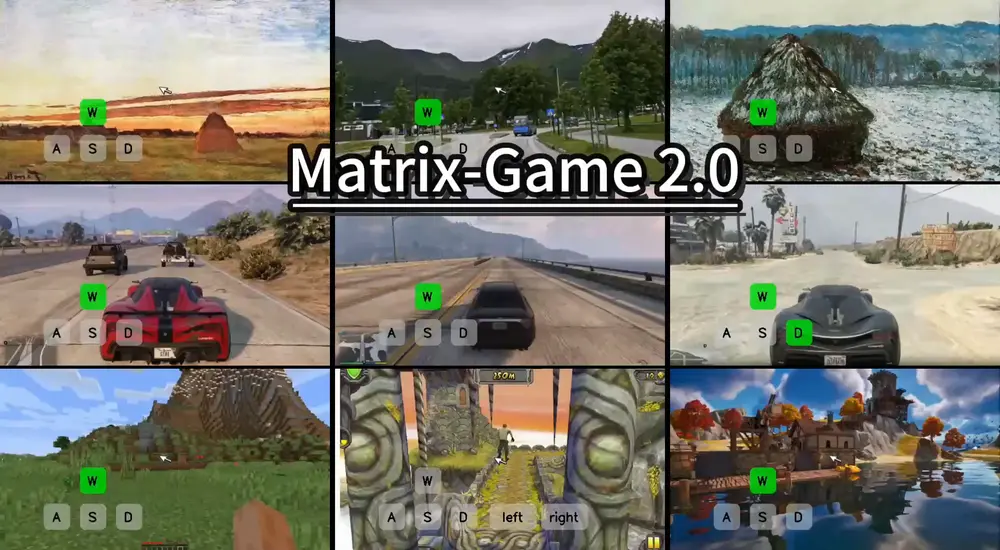
昆仑万维发布 Matrix-Game 2.0:首个开源通用交互式世界模型,把“虚拟世界”推向生产线DeepMind 最近发布的 Genie 3 让世界再次看到了“交互式世界模型”的潜力:一个模型,即可生成可玩、可控、长序列的虚拟环境。用户只需按下方向键,就能在一个由 AI 实时渲染的世界中自由探索...多模态模型# Matrix-Game 2.0# 交互式世界模型# 昆仑万维6个月前02570
综合多模态系统InternLM-XComposer2.5-OmniLive (浦语·灵笔 2.5 OmniLive):实现实时视频和音频交互创建能够像人类认知一样长时间与环境互动的AI系统一直是人工智能领域的长期研究目标。尽管多模态大语言模型(MLLMs)在开放世界理解方面取得了显著进展,但在连续和同时的流式感知、记忆和推理方面仍然面临巨...多模态模型# InternLM-XComposer2.5-OmniLive# 浦语·灵笔 2.5 OmniLive12个月前02550
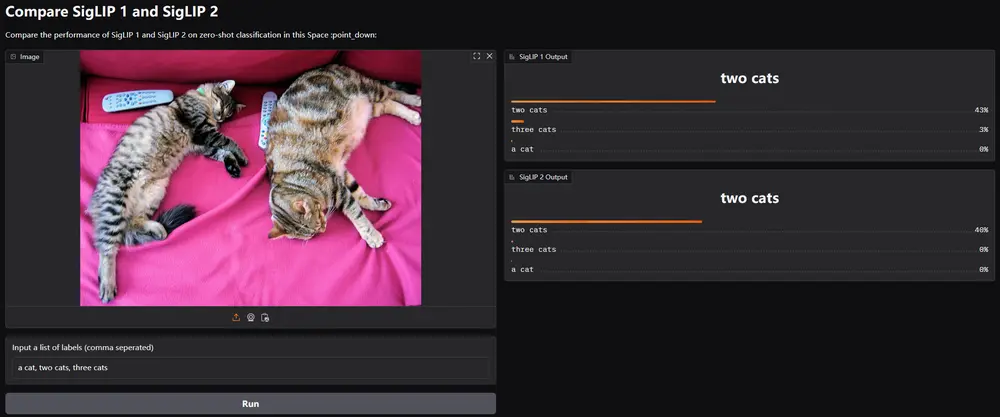
谷歌发布多语言视觉语言编码器SigLIP 2今天,谷歌正式发布了 SigLIP 2——一个全新的多语言视觉语言编码器系列。SigLIP 2 在语义理解、定位和密集特征方面进行了显著改进,进一步提升了视觉语言模型的性能。 官方说明:https...多模态模型# PaliGemma 2# SigLIP 2# 视觉编码器11个月前02540
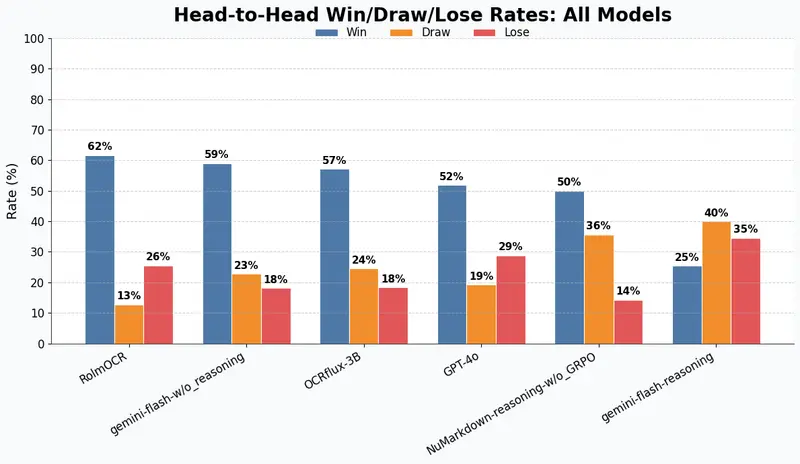
NuMarkdown-8B-Thinking 发布:首个具备推理能力的 OCR 视觉语言模型NuMind 正式推出 NuMarkdown-8B-Thinking —— 据称是首个专为文档理解设计、具备显式推理能力的视觉语言模型(VLM)。该模型专注于将扫描文档或图像中的复杂版式内容,精准转换...多模态模型# NuMarkdown-8B-Thinking# OCR 视觉语言模型6个月前02520
阿里通义实验室发布了Qwen 模型家族的旗舰视觉语言模型Qwen2.5-VL阿里通义实验室发布了Qwen 模型家族的旗舰视觉语言模型Qwen2.5-VL,对比此前发布的 Qwen2-VL 实现了巨大的飞跃。欢迎访问 Qwen Chat 并选择 Qwen2.5-VL-72B-I...多模态模型# Qwen2.5-VL# 视觉语言模型11个月前02500
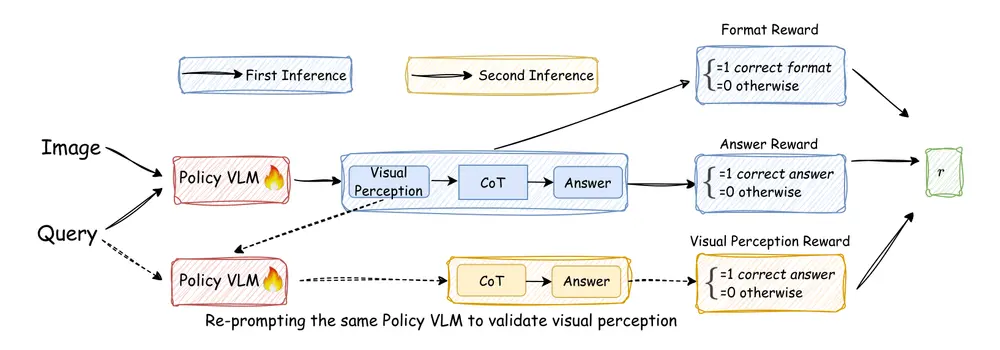
腾讯AI实验室联合两校发布Vision-SR1:自我奖励+推理分解,破解VLM视觉推理难题腾讯AI实验室联合马里兰大学帕克分校、华盛顿大学圣路易斯分校的研究团队,共同发布了新型视觉-语言模型(VLM)——Vision-SR1。该模型聚焦于解决传统VLM的核心痛点,通过创新的“自我奖励机制...多模态模型# Vision-SR1# 视觉-语言模型5个月前02440
快手 Keye 团队发布 Kwai Keye-VL :专注短视频理解的多模态大模型快手 Keye 团队近日推出了一款全新的多模态大型语言模型(MLLM)——Kwai Keye-VL。该模型拥有 80 亿参数,专注于提升对短视频的理解能力,同时保持强大的通用视觉-语言能力。 GitH...多模态模型# Kwai Keye-VL# 多模态大模型# 快手7个月前02420