
随着大型视觉语言模型(VLMs)的出现,多模态任务的发展取得了显著进展。这些模型在图像和视频字幕、视觉问答以及跨模态检索等应用中展现了强大的推理能力。然而,尽管VLMs具有卓越的表现,它们在细粒度图像区域组合信息感知方面仍面临挑战,特别是在将分割掩码与相应的语义对齐并精确描述所指区域的组合方面。
为了解决这一问题,罗切斯特大学和Adobe研究中心的研究人员提出了FINECAPTION——一种新型的VLM,能够将任意掩码识别为参考输入,并处理高分辨率图像以在不同粒度级别上进行组合图像字幕生成。此外,研究人员还引入了COMPOSITIONCAP,一个新的多粒度区域组合图像字幕数据集,旨在支持组合属性感知区域图像字幕任务。
- 项目主页:https://hanghuacs.github.io/FineCaption
- GitHub:https://github.com/hanghuacs/FineCaption
- 数据:https://huggingface.co/hhua2/finecaption
例如,我们有一张海滩日落的照片,照片中有一个木桌,上面放着一个带有棕色和白色图案的绿色玻璃花瓶,花瓶里插着橙色和粉色的花朵,以及绿叶。FINECAPTION模型能够识别出这个场景中的特定区域(例如,花瓶),并生成关于这个区域的详细描述,比如花瓶的颜色、材质、形状以及它与其他物体(如桌子、酒杯等)的相对位置和交互。
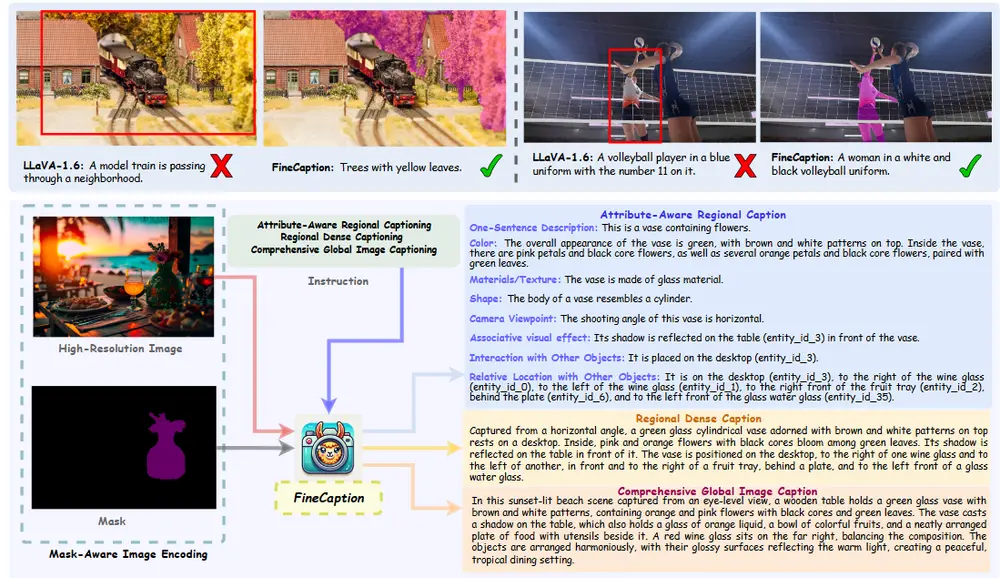
FINECAPTION的关键创新
FINECAPTION通过以下几方面的创新,提升了VLMs在组合性理解和生成方面的能力:
- 任意掩码识别:FINECAPTION能够接受任意形状和大小的分割掩码作为参考输入,从而灵活地处理各种复杂的图像区域组合。
- 高分辨率图像处理:该模型可以处理高分辨率图像,确保在不同粒度级别上准确捕捉图像细节,这对于组合性理解至关重要。
- 多粒度组合字幕生成:FINECAPTION能够在不同的粒度级别上生成组合图像字幕,从全局场景描述到局部区域的精细特征描述,提供了更加丰富和准确的文本表达。
- 组合属性感知:通过引入COMPOSITIONCAP数据集,FINECAPTION能够学习和理解图像中不同组件之间的组合关系,从而更好地生成连贯且有意义的字幕。
COMPOSITIONCAP数据集
COMPOSITIONCAP是一个专门为组合属性感知区域图像字幕任务设计的新数据集。它包含大量标注了多个粒度级别的图像区域及其对应的组合性描述。这个数据集的引入不仅为FINECAPTION的训练提供了丰富的资源,还为研究社区提供了一个评估和改进VLM组合性理解的标准平台。
- 多粒度标注:每个图像区域都标注了从全局到局部的不同粒度级别的信息,帮助模型学习如何在不同层次上理解图像内容。
- 组合性描述:数据集中包含了详细的组合性描述,强调了图像中各个组件之间的关系,使得模型能够更好地理解复杂的视觉场景。
主要功能:
FINECAPTION的主要功能是进行多粒度的区域组合图像描述。它能够:
- 识别任意掩码作为参考输入。
- 处理高分辨率图像。
- 生成具有不同细节层次的图像描述。
主要特点:
- 多粒度描述能力:FINECAPTION能够根据不同的粒度级别生成图像描述,包括属性感知区域描述、区域密集描述和全面全局图像描述。
- 掩码识别:模型能够识别掩码指定的区域,提供更精确的区域参考。
- 高分辨率处理:FINECAPTION支持高分辨率图像编码,能够捕捉更精细的视觉信息。
工作原理:
FINECAPTION模型结合了掩码感知编码器和多个高分辨率编码器,通过多分辨率图像编码框架实现。它首先将低分辨率图像和掩码输入到编码器中,通过额外的alpha通道将掩码作为参考。然后,使用两个高分辨率编码器(例如ConvNeXT和SAM)提取细粒度特征。最后,通过通道级联和适配器模块将特征融合并映射到大型语言模型的词嵌入空间,以生成描述。
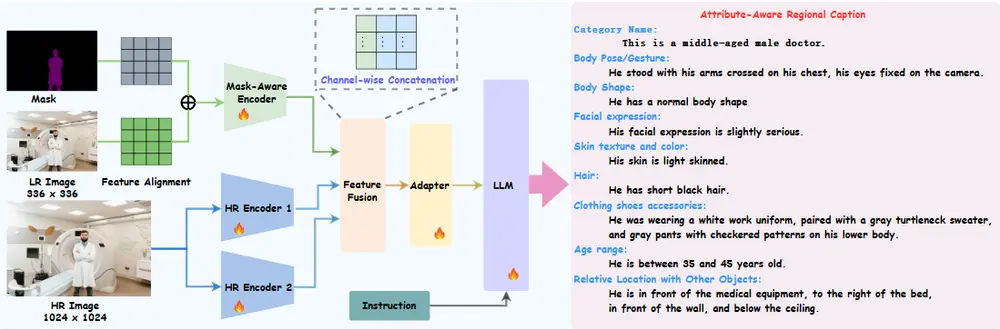
实验结果与分析
实证结果显示,FINECAPTION在效果上显著优于其他最先进的VLM。具体来说:
- 组合性理解:FINECAPTION在识别和描述图像中的组合区域方面表现出色,能够准确捕捉不同组件之间的关系。
- 细粒度描述:模型在生成细粒度图像区域的描述时,展示了更高的准确性和一致性,尤其在复杂场景下表现尤为突出。
此外,研究人员还分析了当前VLM在识别组合区域图像字幕的各种视觉提示方面的能力,指出了一些需要改进的领域。例如,VLMs在处理非典型组合或少见的视觉模式时仍然存在困难,这表明在VLM设计和训练中需要进一步优化和增强。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











