来自伊利诺伊大学香槟分校和微软公司的研究人员公开了多LoRA组合来生成图像的项目。简单来说,LoRA是一种可以让文本生成图像模型更准确地呈现特定元素(如独特的字符、风格或服装)的技术。论文探讨了如何更有效地结合多个LoRA,以创建更复杂的图像。
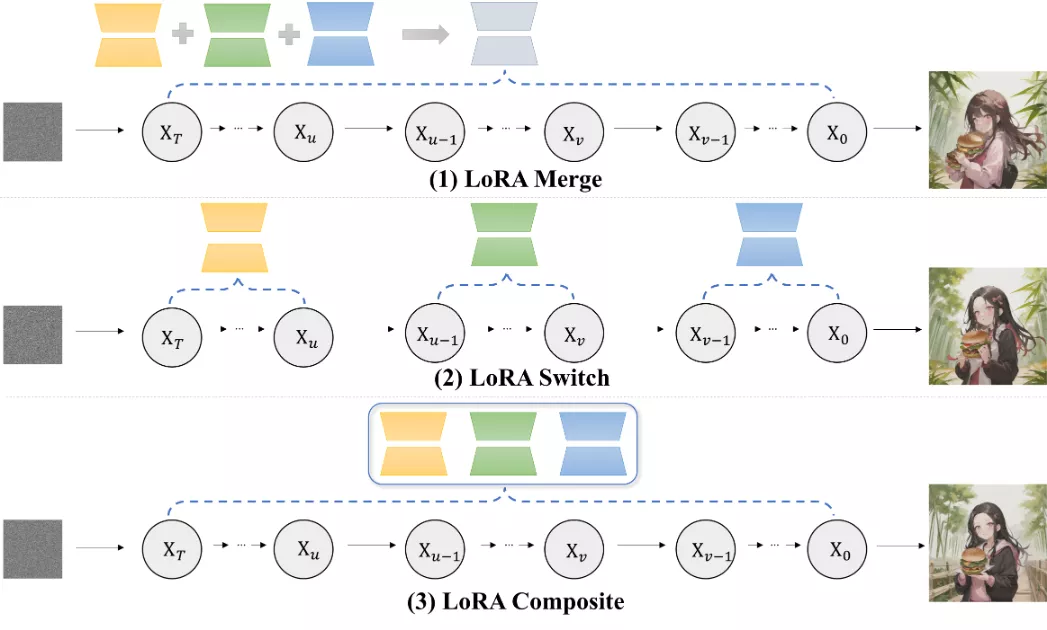
他们提出了两种无需训练的方法来解决这个问题。第一种叫做LORA SWITCH,它在每个去噪步骤中交替使用不同的LoRA。第二种叫做LORA COMPOSITE,它同时结合所有LoRA来指导更连贯的图像合成。
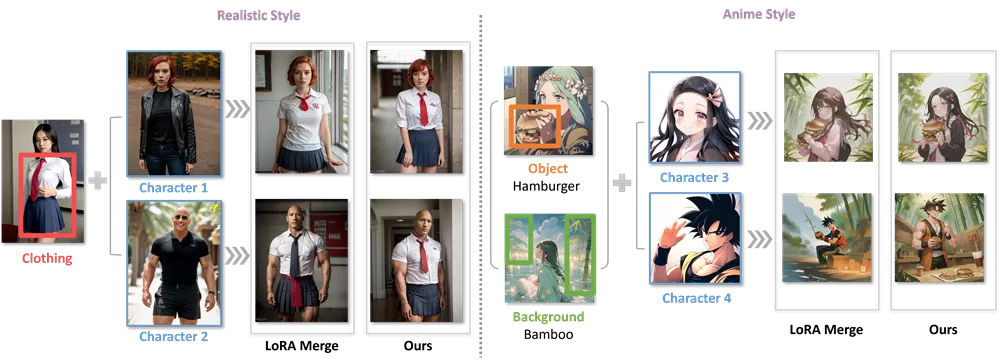
通过建立一个新的测试平台ComposLoRA,并使用GPT-4V作为评估工具,展示了这两种方法在性能上的显著提升,尤其是在组合更多LoRA时。
主要特点:
- 这两种方法都不需要训练,可以直接应用于现有的LoRA模型。
- 它们能够处理任意数量的LoRA,克服了以往研究中通常只能合并两个LoRA的限制。
- 通过直接影响扩散过程,而不是操纵权重矩阵,这两种方法能够更好地保持生成图像的质量和细节。
工作原理:
LoRA工作的基本原理是通过调整模型中的低秩矩阵来适应特定的图像生成需求。这些低秩矩阵可以被视为模型中的“插件”,可以根据需要添加或删除,以改变模型的行为。在这篇论文中,研究者通过探索不同的LoRA组合方式,实现了更加灵活和高效的图像生成。
- LORA SWITCH:在图像生成的每个去噪步骤中,选择一个LoRA来激活,然后在生成过程中循环切换不同的LoRA。
- LORA COMPOSITE:在每个去噪步骤中,计算每个LoRA的无条件和条件分数估计,然后将这些分数平均,以平衡地指导图像生成。
具体应用场景:
- 虚拟试穿:用户可以与服装在真实感的方式中合并,例如在电子商务网站上预览服装效果。
- 城市景观设计:用户可以与精心设计的城市规划元素互动,例如在城市规划软件中预览建筑和街道布局。
- 个性化数字内容创作:用户可以定制自己的LoRA模型来生成各种个性化和真实的图像,例如创建个性化的头像或者艺术作品。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...