
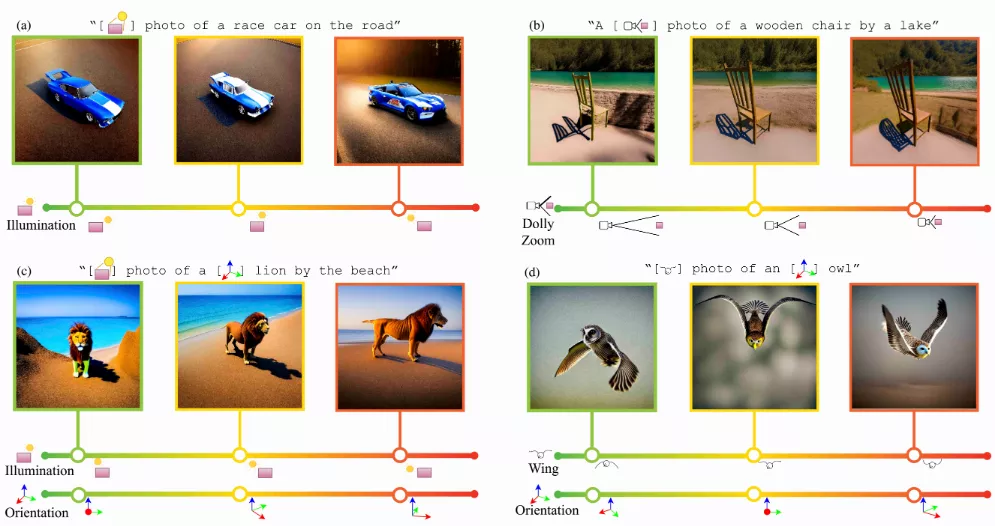
来自牛津大学、Adobe Research的研究人员提出了一种“连续3D词(Continuous 3D Words)”的新方法,使得用户能够通过文本提示来精细控制图像生成过程中的多个属性,比如照明方向、非刚性形状变化、方向和相机参数等。
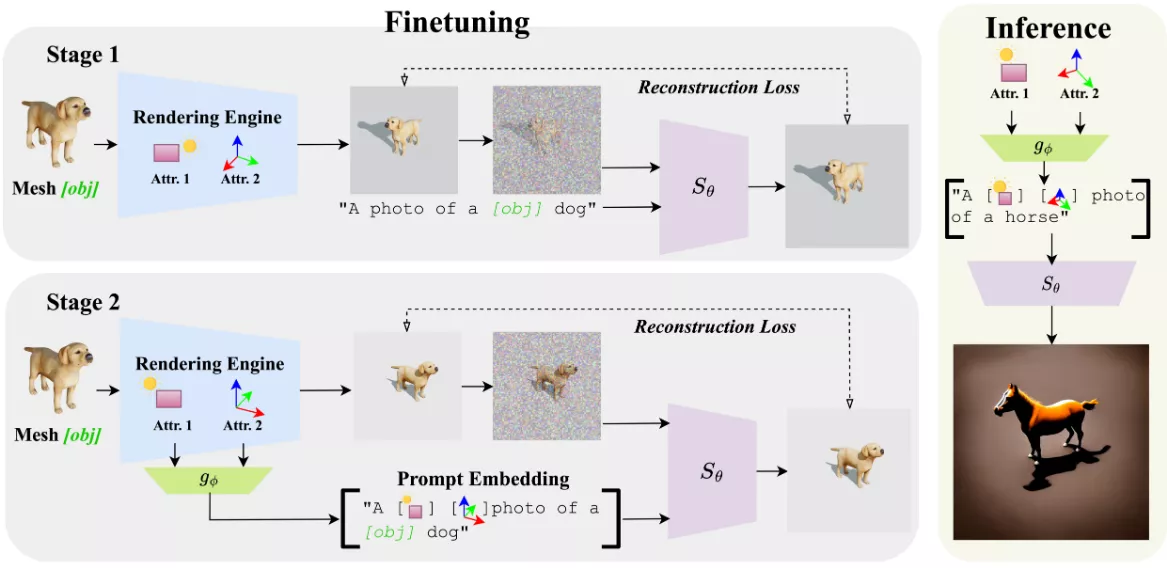
在训练阶段,该方法首先使用渲染引擎生成具有不同属性值(例如光照和姿态)的图像系列,然后将这些图像输入到文本到图像的扩散模型中,以学习表示单个网格的标记嵌入。在第二阶段,将表示单个属性的标记添加到提示嵌入中。这种两阶段的训练方式可以更好地从对象身份中解耦各个属性。在推理阶段,用户可以通过在文本提示中添加连续3D词来控制生成图像中的属性。
主要功能:
- 用户可以通过特殊的输入标记(称为Continuous 3D Words)来精细控制图像生成的多个连续属性。
- 这些属性可以表示为滑块,并与文本提示一起使用,以实现对图像生成的精细控制。
主要特点:
- 连续控制:通过学习一个连续的函数,用户可以在一个连续的范围内调整属性,而不是使用离散的标记。
- 训练策略:采用两阶段训练策略,首先学习对象的身份,然后学习与对象身份分离的各种属性值。
- 泛化能力:即使只使用一个3D网格和渲染引擎进行训练,方法也能很好地泛化到新的物体和场景。
- 轻量级设计:使用低秩适应(LoRA)技术,使得训练过程快速且占用资源少。
工作原理:
- 使用一个简单的多层感知器(MLP)来学习将连续的属性值映射到标记嵌入空间,这些标记嵌入被称为Continuous 3D Words。
- 在训练过程中,首先使用Dreambooth方法学习底层网格的对象身份,然后顺序学习与对象身份分离的各种属性值。
- 在推理阶段,通过在文本提示中添加Continuous 3D Words,可以对不同对象应用这些属性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











