来自Meta Reality Labs的研究人员推出了多模态问答系统Lumos,这是一个结合了场景文本识别(Scene Text Recognition, STR)和多模态大语言模型(Multimodal Large Language Model, MM-LLM)的问答系统。
Lumos的核心功能是理解和回答与场景中文本相关的问题,这在现实世界的应用中非常有用,比如当你看到一张图片并想知道图片上的某个产品信息或者某个指示牌的内容时。
主要功能:
Lumos的主要功能是识别图像中的文本,并将这些文本信息用于增强大型语言模型的性能。它能够从第一人称视角的图像中提取出有用的文本信息,如路标、物品标签或屏幕上的文字等,然后将这些信息整合到多模态语言模型中,以提供更准确、更全面的答案。
主要特点:
- 端到端的问答能力:Lumos能够直接从用户拍摄的图片中提取文本信息,并结合语言模型来回答相关问题。
- 低延迟:系统设计注重减少用户等待时间,确保了快速响应。
- 设备兼容性:Lumos能够在设备上运行,这意味着它可以在智能手机或其他移动设备上使用,而不需要依赖云端服务器。
- 高准确性:通过优化的STR组件和MM-LLM,Lumos在文本识别和问答任务上表现出色。
工作原理:
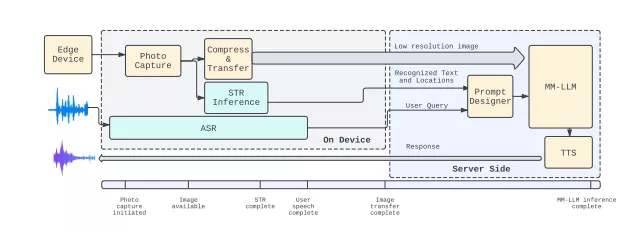
Lumos的工作原理可以分为两个主要步骤。首先,它使用场景文本识别技术从图像中提取出文本信息。这个过程涉及到图像预处理、文字定位和文字识别等多个环节。然后,提取出的文本信息被整合到多模态大型语言模型中,用于生成最终的答案。这个模型能够同时处理文本和图像信息,从而提供更全面、更准确的答案。
- 用户通过设备拍摄图片。
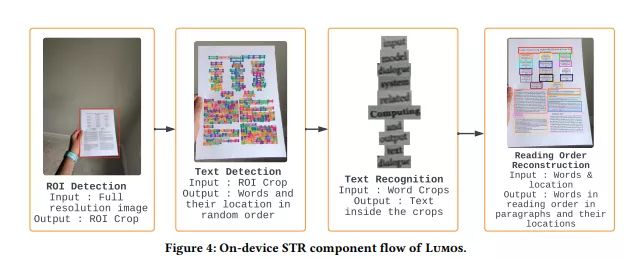
- Lumos的STR组件在设备上识别图片中的文本,这个过程包括识别文本区域(ROI检测)、定位文本(文本检测)、识别文字(文本识别)以及确定文字的阅读顺序(阅读顺序重建)。
- 识别出的文本和图片一起发送到云端的MM-LLM,由它生成回答。
- MM-LLM结合了文本和图片信息,生成对用户问题的准确回答。
应用场景:
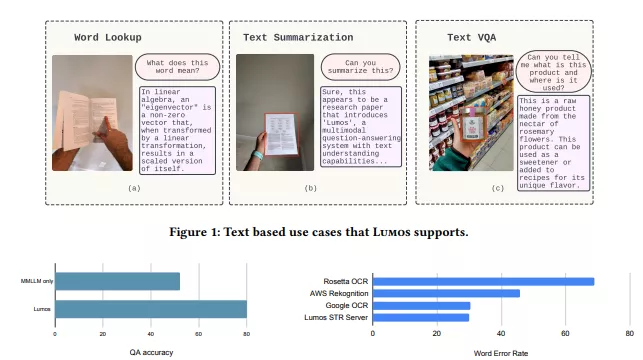
- 产品信息查询:用户拍摄产品包装,Lumos可以识别并解释包装上的文本,如成分、用途等。
- 导航和指示牌解读:在户外,用户可以拍摄路标或指示牌,Lumos帮助解读上面的信息。
- 文档内容总结:用户拍摄文档或书籍的一部分,Lumos能够提取并总结关键信息。
- 实时翻译:在旅行或国际交流中,Lumos可以帮助用户理解外语文本。
Lumos通过这些功能,使得智能助手能够更好地理解和回应用户在现实世界中遇到的场景文本问题。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











