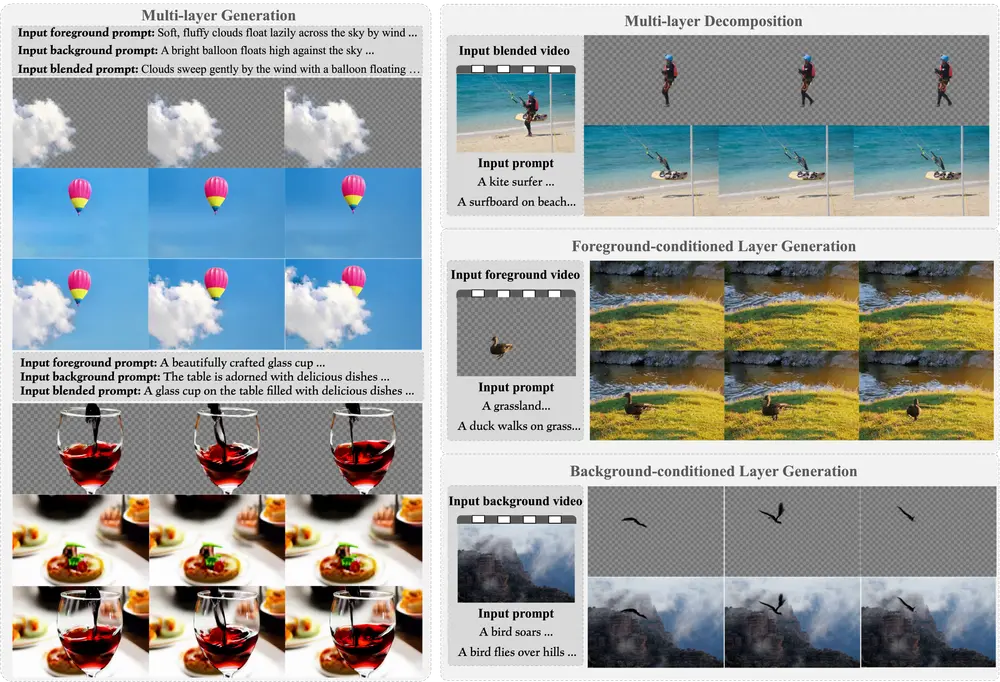
浙江大学计算机科学与技术学院的研究团队推出一个名为CAMI2V(Camera-Controlled Image-to-Video Diffusion Model)的模型,它是一个基于扩散模型的图像到视频生成系统,能够根据文本提示生成视频,并且特别强调了对相机姿态的控制能力。这个模型通过整合显式的物理约束来增强模型对物理世界的理解,从而实现更精确的相机控制和更好的3D一致性。
例如,你是一名视频制作人,需要根据一段描述某个场景的文本来生成视频。使用CAMI2V,你只需提供文本描述和参考图像,模型就能生成一个视频,其中相机的运动和视角会根据文本中的指示进行调整,就像有一个真实的摄影师在按照脚本拍摄一样。

主要功能和特点
- 相机控制:CAMI2V能够根据文本提示和用户提供的相机姿态信息生成视频,实现精确的相机运动控制。
- 3D一致性:通过使用Plücker坐标和极线约束,模型确保了视频中的3D一致性,即使在高噪声条件下也能保持特征跟踪的稳定性。
- 显式物理约束:模型整合了几何先验,提出了一种新颖的框架来注入相机姿态,提高了对物理世界知识的理解和控制能力。
- 多尺度引导:为了支持图像到视频的转换,模型提出了多尺度引导,允许分别对图像、文本和相机进行精确控制。
- 鲁棒性评估:建立了一个更鲁棒、准确和可复现的评估流程,解决了现有相机控制测量中的不准确和不稳定问题。
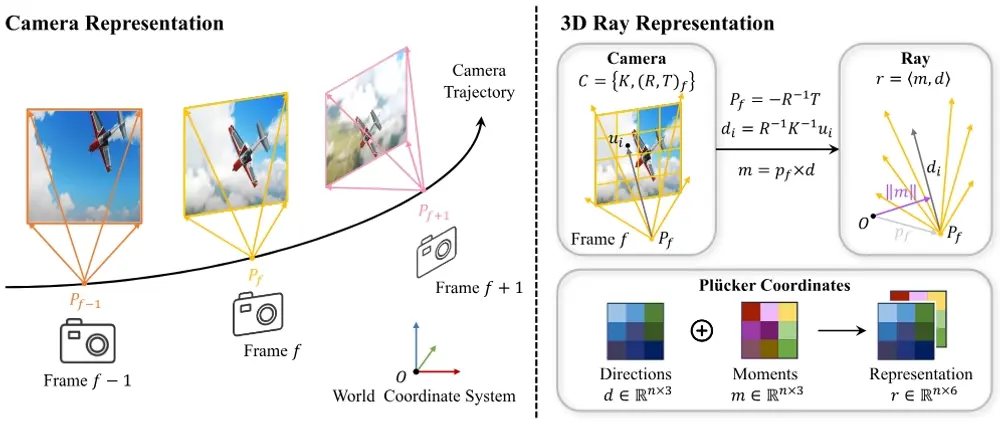
工作原理
CAMI2V的工作原理包括以下几个关键步骤:
- 3D射线嵌入:使用Plücker坐标将相机姿态嵌入到模型中,为隐式学习3D空间提供绝对3D射线嵌入。
- 极线约束的注意力机制:提出了一种新颖的极线注意力机制,通过极线约束来聚合特征,确保即使在高噪声条件下也能有效地跟踪跨帧的特征。
- 注册令牌:为了处理由于快速相机移动、动态对象或遮挡导致帧间没有交集的情况,模型引入了注册令牌。
- 多尺度引导:通过多个引导尺度来平衡视觉质量和相机姿态一致性,允许用户根据需要调整图像、文本和相机的控制强度。
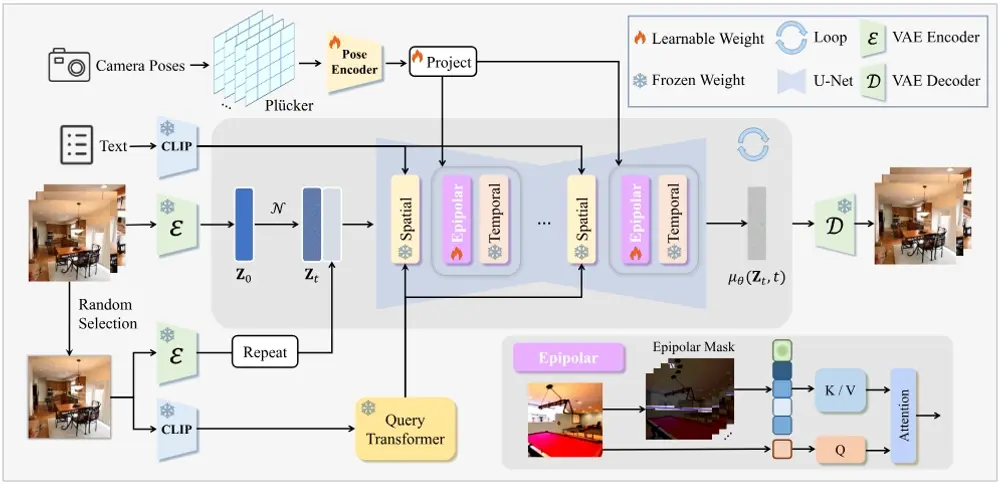
具体应用场景
- 电影制作:在电影制作中,可以根据剧本生成特定视角和相机运动的视频片段。
- 虚拟现实:在虚拟现实应用中,可以根据用户的指令生成相应的3D视频内容。
- 新闻报道:在新闻报道中,可以根据记者的描述快速生成现场报道视频。
- 游戏开发:在游戏中,可以根据玩家的行动和选择动态生成游戏过场动画。
- 教育和培训:在教育和培训领域,可以根据教学内容生成教学视频,提供更直观的学习体验。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...