
浙江大学、腾讯人工智能实验室和腾讯 PCG ARC 实验室的研究人员推出新型视频生成框架CustomCrafter,它可以根据文本提示和主题参考图像生成高质量视频。这项技术的目标是让用户能够自定义视频内容,包括主题身份和动作模式,同时保持视频的流畅运动和概念组合能力。例如,你想要生成一段视频,内容是“一只泰迪熊在乡村道路上奔跑”。使用CustomCrafter,你只需要提供泰迪熊的图片和相应的文本描述,它就能生成你想要的视频,而且视频中的泰迪熊动作流畅,看起来非常自然。
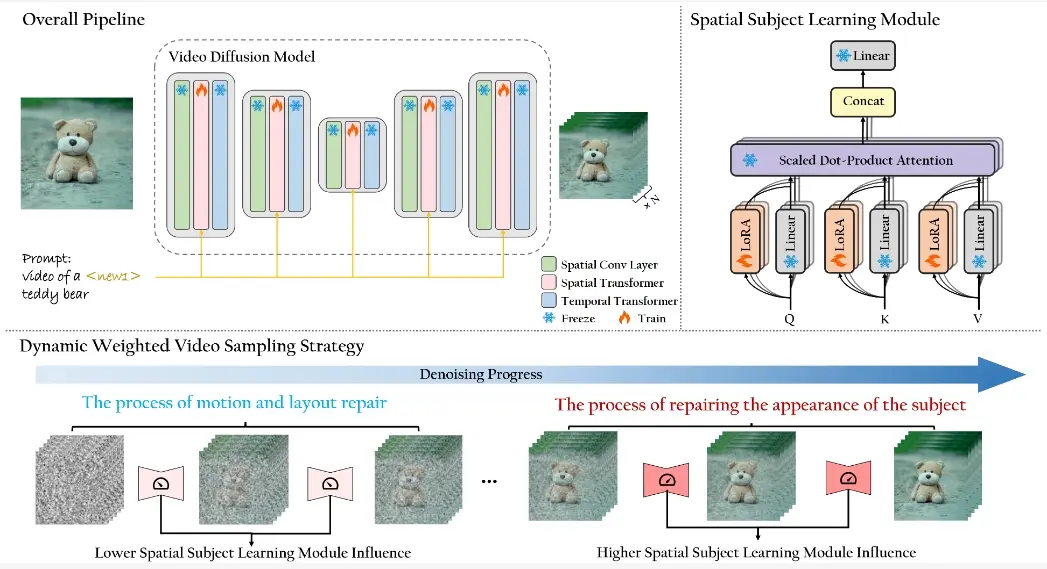
CustomCrafter在不需要额外视频和微调的情况下保留了模型的运动生成和概念组合能力。为了保持概念组合能力,研究团队设计了一个即插即用模块来更新 VDMs 中的少量参数,从而增强模型捕捉新主题外观细节以及概念组合的能力。对于运动生成,研究团队观察到 VDMs 在去噪过程的早期倾向于恢复视频中的运动,而在后期则专注于恢复主题的细节。因此,研究团队提出了动态加权视频采样策略。利用CustomCrafter主题学习模块的即插即用特性,研究团队在去噪过程的早期阶段减少了该模块对运动生成的影响,从而保留了 VDMs 生成运动的能力。在去噪过程的后期阶段,研究团队恢复该模块以修复指定主题的外观细节,从而确保主题外观的保真度。

主要功能:
- 根据文本提示生成视频,同时自定义主题身份(如泰迪熊)和动作模式(如奔跑)。
- 保持视频生成过程中的运动连贯性和概念组合能力。
主要特点:
- 无需额外视频指导:与以往需要额外视频来指导模型生成特定动作的方法不同,CustomCrafter不需要这些额外的视频资料。
- 保持概念组合能力:框架设计了一个即插即用模块,可以更新视频扩散模型(VDMs)中的少量参数,增强模型捕捉新主题外观细节的能力。
- 动态加权视频采样策略:在视频生成的早期阶段,重点恢复视频的运动,而在后期阶段重点恢复主题细节。
工作原理:
- 空间主题学习模块:通过微调视频扩散模型中的空间变换模块,使模型能够学习新主题的外观,同时保持与其他概念的组合能力。
- 动态加权视频采样策略:在视频生成的去噪过程中,早期阶段减少主题学习模块对运动生成的影响,后期阶段恢复这一模块以修复指定主题的外观细节。
具体应用场景:
- 个性化视频制作:用户可以根据自己的需求生成具有特定主题和动作的视频。
- 故事讲述:通过文本提示生成视频,讲述一个故事或展示一个场景。
- 虚拟角色生成:为动画、游戏或其他媒体内容创建动态的虚拟角色。
CustomCrafter通过创新的方法解决了以往技术在生成视频时可能出现的动作僵硬和概念组合能力下降的问题,提供了一种更为自然和灵活的视频生成解决方案。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











