
加州理工学院的研究人员推出FIND3D模型,它能够在开放世界环境中对3D对象的任何部分进行语义分割。这意味着FIND3D可以基于任何文本查询,对任何对象的任何部分进行分割。这项技术在机器人技术、虚拟现实(VR)和增强现实(AR)应用中具有重要意义,因为这些领域需要对3D空间中的对象及其部分进行精确的操作和空间感知。
- 项目主页:https://ziqi-ma.github.io/find3dsite
- GitHub:https://github.com/ziqi-ma/Find3D
- Demo:https://huggingface.co/spaces/ziqima/Find3D
例如,如果给定一个3D模型的点云数据,FIND3D能够根据文本提示“汽车的轮子”来识别并分割出汽车的轮子部分。无论这个汽车模型是来自一个标准的数据库还是一个随机的、在野外捕获的图像,FIND3D都能够处理。

主要功能:
- 开放世界3D部分分割:FIND3D可以在没有任何先验类别限制的情况下,对任何对象的任何部分进行分割。
- 零样本学习:模型能够在没有看到特定类别对象的情况下,对这些对象进行分割。
- 多数据集泛化:FIND3D在多个数据集上都有良好的性能,包括在训练时未见过的数据集。
主要特点:
- 无需人工标注:FIND3D的训练依赖于一个数据引擎,该引擎使用2D基础模型自动从互联网上的3D资产中生成标注。
- 对比训练方法:通过对比学习目标,FIND3D能够处理标签的歧义和层次结构。
- 高效性能:FIND3D在推理时比现有的基线方法快6倍至300倍以上。
工作原理:
FIND3D的工作流程包括两个主要部分:
- 数据引擎:利用2D视觉和语言基础模型(如SAM和Gemini)自动标注3D对象。这些标注数据用于训练一个基于Transformer的3D点云模型。
- 对比训练:使用对比学习目标来训练模型,使得模型能够将点云中的特征与文本查询的嵌入空间相匹配,从而实现对任何文本查询的分割。
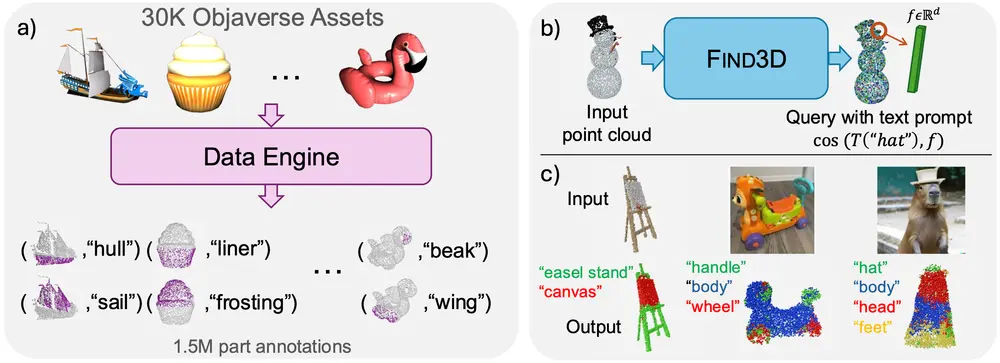
具体应用场景:
- 机器人技术:在机器人抓取和操作任务中,FIND3D可以帮助机器人识别和定位对象的特定部分。
- VR/AR:在虚拟或增强现实环境中,FIND3D可以用于理解和交互3D对象,提供更加自然和直观的用户体验。
- 3D建模和设计:在3D建模和设计领域,FIND3D可以帮助设计师快速定位和修改模型的特定部分。
- 野外3D重建:FIND3D能够处理从野外捕获的图像(如iPhone照片)重建的3D模型,为现实世界中的3D数据提供语义分割。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











