
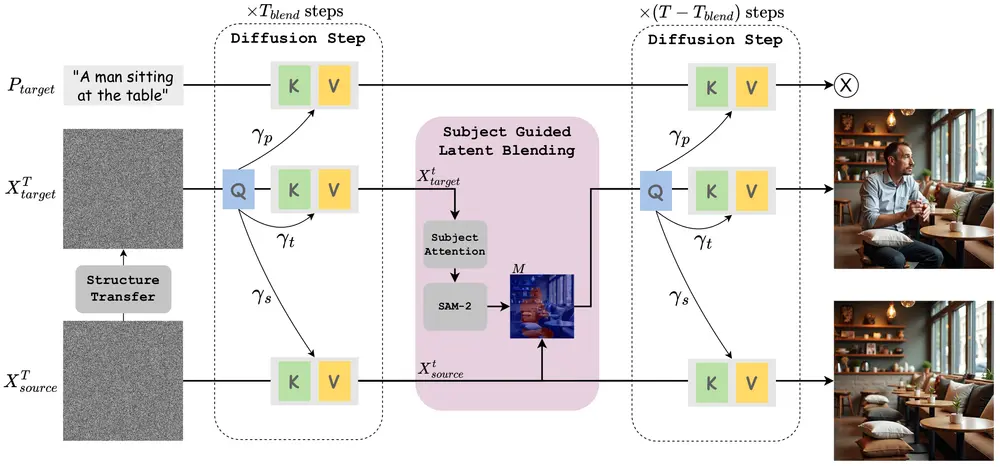
一个名为Add-it的系统,它是一种无需训练的方法,可以在图像中根据文本提示添加对象。这种方法扩展了预训练扩散模型的注意力机制,以整合来自三个关键来源的信息:场景图像、文本提示和生成图像本身。
例如,一个用户想要在一张空客厅的图片中添加一幅画。他们只需提供一个简单的文本提示,比如“在墙上挂一幅画”,Add-it就能在图像中自然地添加这幅画,同时保持客厅的原始结构和细节。这个过程不需要任何额外的训练或优化步骤,用户可以直接看到最终的编辑结果。

主要功能:
Add-it的主要功能是将文本描述的对象无缝地添加到给定的图像中,同时保持原始场景的结构和细节,并确保对象的放置看起来自然。这个过程不需要额外的训练或优化。

主要特点:
- 无需训练: Add-it不依赖于任务特定的微调,可以利用预训练的扩散模型来执行图像编辑任务。
- 扩展注意力机制: 通过扩展多模态注意力机制,Add-it考虑了源图像、目标图像和文本提示的令牌。
- 结构一致性和细节保留: 通过控制不同注意力组件的影响,Add-it在添加新对象时保持了源图像的结构和细节。
- 自然对象放置: Add-it通过平衡源图像和目标提示的信息,确保对象被放置在合理的位置上。
工作原理: Add-it的工作原理基于以下几个关键组件:
- 加权扩展自注意力机制: 通过为源图像、文本提示和目标图像分配不同的权重,Add-it在生成过程中平衡了这三者的信息。
- 结构转移: 通过在高噪声水平下对源潜在表示进行噪声化,Add-it将源图像的结构注入到目标图像中。
- 主题引导的潜在混合: 为了保留源图像中的精细细节,Add-it使用粗略的掩码和SAM-2模型来生成精细的掩码,并在潜在空间中混合源和目标图像的噪声表示。
实验结果
1. 基准测试
Add-it在多个基准测试中均达到了最先进的结果,包括:
真实图像插入基准:Add-it在真实图像中添加对象的性能显著优于现有方法。 生成图像插入基准:在生成图像中添加对象的任务中,Add-it同样表现出色。 添加功能性基准:这是一个新构建的基准,用于评估对象放置的合理性。Add-it在这个基准上超越了监督方法,展示了其在复杂场景中的强大能力。
2. 人类评估
除了自动化指标外,Add-it还进行了人类评估。结果显示,Add-it在超过80%的情况下更受欢迎,用户认为其生成的图像在对象放置和整体效果上更自然、更合理。
3. 自动化指标
在各种自动化指标上,Add-it也显示出显著的改进,包括:
结构相似性指数(SSIM):衡量生成图像与原始图像的结构相似度。 峰值信噪比(PSNR):衡量生成图像与原始图像的像素差异。 特征匹配分数:衡量生成图像与原始图像在高级特征上的匹配度。
应用前景
Add-it在基于文本指令的图像编辑任务中展现了巨大的潜力,可以应用于多种场景,包括但不限于:
创意设计:艺术家和设计师可以使用Add-it在图像中添加特定对象,以增强创意作品。 虚拟现实和增强现实:在虚拟环境中添加对象,增强用户的沉浸感。 广告和营销:在广告图片中添加产品或元素,提高营销效果。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











