最近的研究表明,尽管视觉信息被高度压缩,视觉-语言模型(VLMs)依然能在多种任务中保持出色的性能。本研究聚焦于一种流行的加速方法——早期修剪视觉标记,并揭示了其成功背后的关键原因。研究人员发现,许多任务中的高性能并不是因为这种方法能够高效地压缩视觉信息,而是由于当前基准测试在评估细粒度视觉能力时的局限性。例如,在图像顶部的大量标记被修剪掉后,仅对定位等少数任务产生了负面影响。对于其他任务,即使存在这种缺陷,模型仍然表现良好。
重新审视现有方法
为了解释为什么某些任务不受影响,而像定位这样的任务却显著下降,研究人员进行了深入分析。结果表明,当在浅层语言模型(LLM)层之后修剪视觉标记时,大部分选择的标记集中在图像底部,这导致了定位任务的性能急剧下降。然而,对于其他任务来说,这些位于底部的标记就足够提供所需的信息,因此性能没有明显变化。这一发现突显了当前基准测试的一个核心问题:它们并不总是需要精细的视觉理解来完成任务。这意味着,尽管加速方法存在不足,但在多数情况下仍能维持良好的性能。
改进加速方法:FEATHER
针对上述问题,斯坦福大学的研究团队提出了一种新的加速方案——FEATHER(Fast and Effective Acceleration wiTH Ensemble Criteria)。FEATHER旨在通过以下方式改善视觉标记的修剪过程:
- 解决识别问题:修正早期层修剪导致的选择偏差。
- 均匀采样:确保所有图像区域得到覆盖,而不是集中在某一特定部分。
- 分阶段修剪:先进行初步修剪,再在后期更广泛地应用,以提升效率和效果。
FEATHER在计算资源消耗相近的情况下,相较于传统加速方法,在视觉为中心的任务如定位上实现了超过5倍的性能提升。即使只保留了后期LLM层3.3%的视觉标记,FEATHER也能显著提升模型的表现。
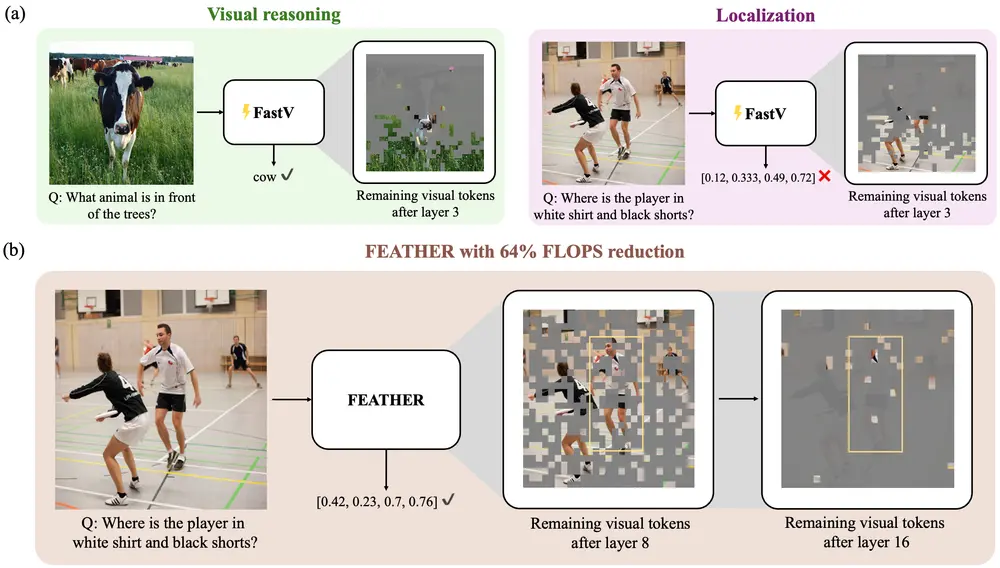
FEATHER的工作原理
FEATHER采用了两种修剪标准的组合:φ-R + φuniform。其中,φ-R是从最后一个文本标记接收到的注意力分数,不考虑RoPE(旋转位置嵌入),从而避免长期衰减效应;φuniform则确保了视觉标记的均匀分布。这种结合不仅提高了早期层修剪的效果,也增强了后期层的修剪效率。
FEATHER的设计灵感来源于赛车手的操作策略:在转弯开始时缓慢加速以保持控制,随后在直线段迅速提速。同样,FEATHER在早期层谨慎修剪,而在后期层则更加激进,从而实现了最佳的性能与效率平衡。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











