360 AI研究中心和中山大学的研究人员推出新型视频生成模型FancyVideo,它能够根据文本提示生成动态丰富且时间上连贯的视频。FancyVideo通过精心设计的跨帧文本引导模块(CTGM)改进了现有的文本控制机制。具体来说,CTGM在交叉注意力的开始、中间和结尾分别集成了时间信息注入器(TII)、时间亲和力精炼器(TAR)和时间特征增强器(TFB),以实现特定于帧的文本指导。首先,TII将来自潜在特征的帧特异性信息注入到文本条件中,从而获得跨帧文本条件。然后,TAR沿时间维度细化跨帧文本条件与潜在特征之间的相关性矩阵。最后,TFB增强了潜在特征的时间一致性。
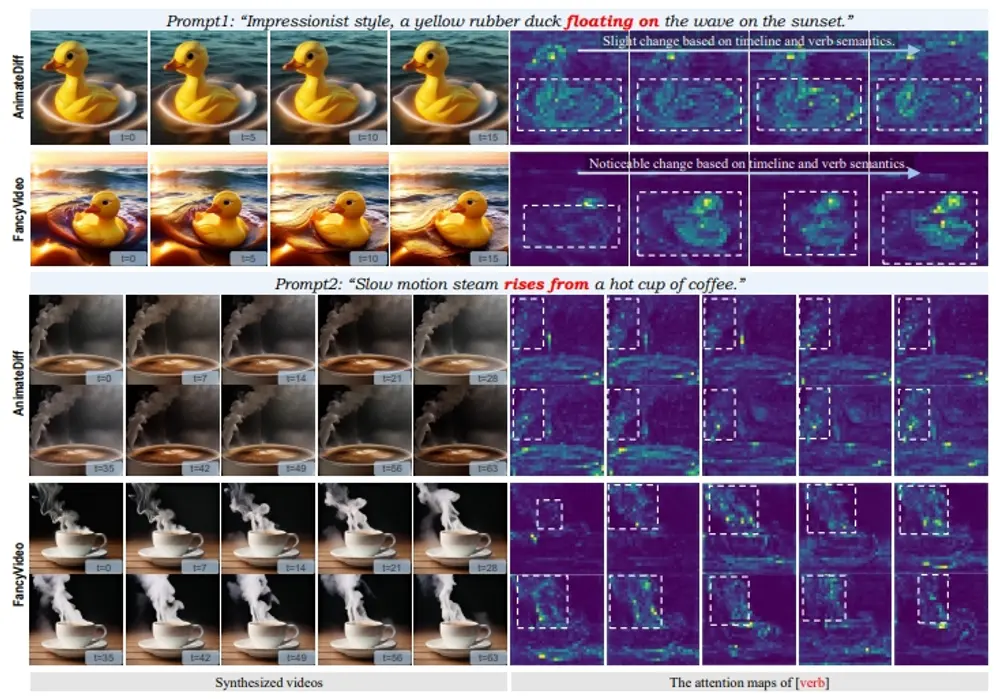
例如,你给FancyVideo一个描述,比如“夕阳下,海浪上漂浮着一只黄色的橡皮鸭”,它就能创造出一个符合这个描述的动态视频,而且视频中的橡皮鸭会随着海浪起伏,展现出逼真的动态效果。
主要功能和特点:
- 跨帧文本引导(Cross-frame Textual Guidance):FancyVideo使用一种新颖的文本控制机制,能够根据文本提示在不同帧之间生成连贯的动作。
- 动态和连贯的视频生成:与现有技术相比,FancyVideo能够生成更具动态性和时间连贯性的视频。
- 高效率和高质量:FancyVideo在保持视频质量的同时,提高了视频生成的效率。
工作原理:
- FancyVideo通过Temporal Information Injector (TII)将时间信息注入到文本条件中,从而获得特定帧的文本条件。
- Temporal Affinity Refiner (TAR)用于优化跨帧文本条件和潜在特征之间的时间相关性,调整文本引导的时间逻辑。
- Temporal Feature Booster (TFB)进一步提升潜在特征的时间一致性,确保视频在连续帧之间的连贯性。

具体应用场景:
- 个性化视频生成:用户可以根据自己的想象或需求,输入文本描述,生成独特的视频内容。
- 视频内容扩展:对现有视频进行扩展,比如增加背景故事或延续视频情节。
- 艺术创作和娱乐:在电影、游戏或动画制作中,FancyVideo可以用来创造复杂的动态场景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...