
来自浙江大学、西湖大学和同济大学的研究团队推出controllable text-to-3D generation,它能够根据文本提示和条件图像生成高质量、可控制的3D模型。这种方法的核心在于使用一种新颖的神经网络架构——Multi-view ControlNet(MVControl),它能够增强现有的预训练多视图扩散模型,并通过整合额外的输入条件(例如边缘、深度、法线和涂鸦图)来实现对生成内容的精细控制。
想象你想要创建一个3D模型的猫,这只猫穿着一件特定的衣服,并且从不同角度看起来都保持一致。你可以给这个系统输入一个描述性的文本提示,比如“穿着红色毛衣的橘色猫”,并且提供一张猫的参考图片。系统将会根据这些信息生成一系列多视图的2D图像,并最终形成一个3D模型,这个模型不仅外观上符合文本描述,而且从各个角度观察都保持一致性。

主要功能和特点:
- 高质量3D生成:能够生成具有丰富细节和清晰纹理的3D模型。
- 可控性:通过额外的输入条件(如边缘图、深度图等)精确控制生成内容。
- 多阶段生成流程:结合了大型重建模型和得分蒸馏算法的优势,提高了生成效率。
- 使用SuGaR表示法:结合了网格和3D高斯的混合表示,提高了几何建模的性能。
工作原理:这个过程分为几个主要步骤:
- 多视图图像生成:使用MVControl生成与条件图像一致的多视图2D图像。
- 粗略3D高斯初始化:利用大型高斯重建模型(LGM)从多视图图像生成一组粗略的3D高斯。
- 高斯优化:通过结合MVControl和2D扩散模型的混合扩散指导来优化粗略的3D高斯。
- SuGaR细化:将优化后的高斯转换为SuGaR表示,进一步细化纹理和几何形状,最终提取出高质量的纹理网格。
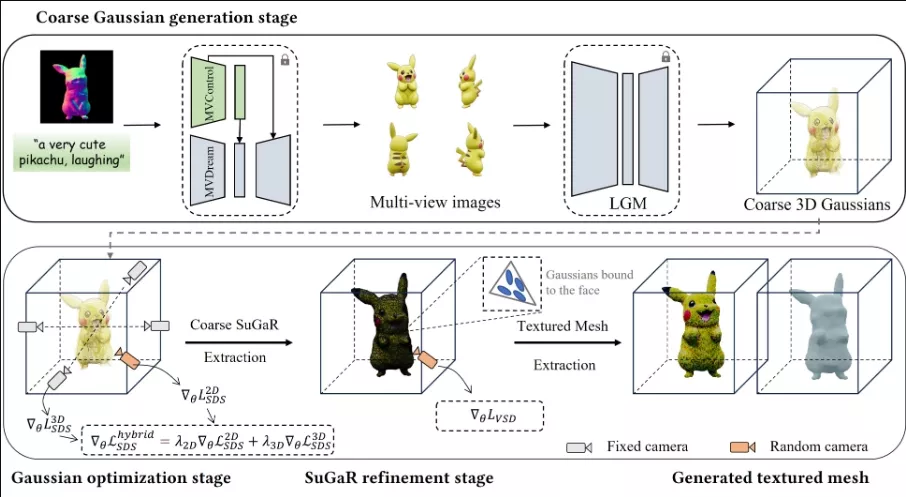
这种方法为3D内容的生成提供了一种新的、高效且可控的方式,使得用户能够根据具体的文本提示和条件图像生成符合预期的3D模型。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











