
香港中文大学MMLab、北京大学和上海人工智能实验室的研究人员推出一种多功能的图像到图像视觉助手 PixWizard,它可以根据自由形式的语言指令执行图像生成、编辑和转换。简单来说,PixWizard就像一个高级的图像编辑器,能够理解我们给出的自然语言指令,并据此对图像进行各种处理。
研究团队将多种视觉任务整合进一个统一的图像-文本-图像生成框架,并创建了一个全方位的像素到像素指令调优数据集。通过构建详细的自然语言指令模板,研究团队全面涵盖了大量多样化的视觉任务,例如文本到图像生成、图像修复、图像定位、密集图像预测、图像编辑、可控生成、修补/外绘等。此外,研究团队采用 DiT架构作为基础模型,并通过灵活的任意分辨率机制扩展其功能,使模型能够根据输入的长宽比动态处理图像,与人类感知过程紧密契合。模型还结合了结构感知和语义感知指导,以促进输入图像信息的有效融合。实验表明,PixWizard 不仅在具有不同分辨率的图像上展示了出色生成和理解能力,而且在未知任务和人类指令上也表现出有前景的泛化能力。

例如,你是一名摄影师,你拍了一张风景照,但天空部分被云遮住了。你可以给PixWizard一个指令,比如“让天空变晴朗”,它会根据这个指令生成一个新的图像版本,其中天空是晴朗的。或者,如果你是一名设计师,需要将草图转换成详细的图像,你可以上传草图并给出指令,PixWizard会帮你完成这个设计任务。
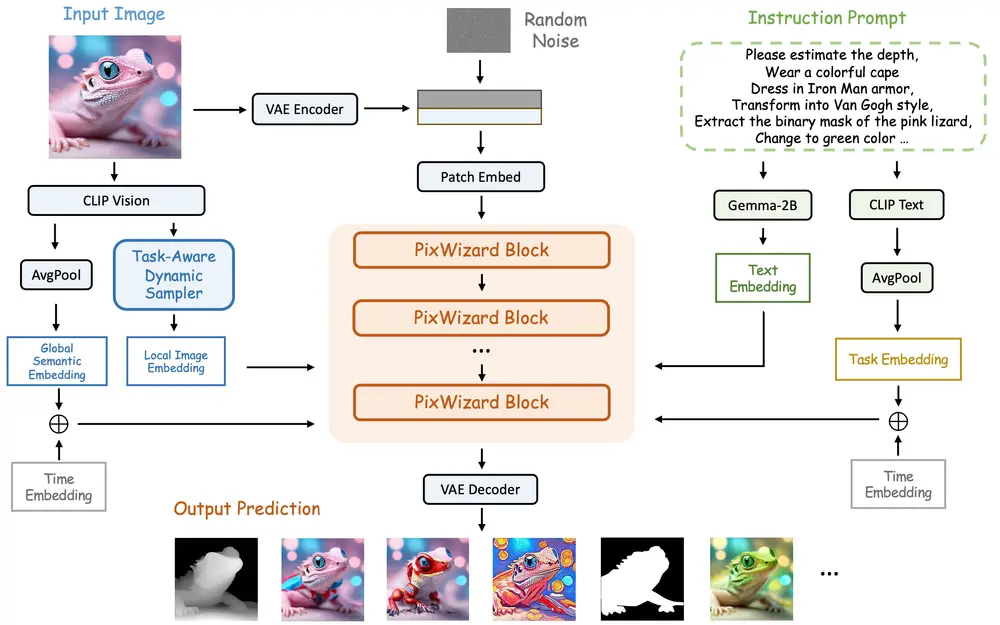
主要功能:
- 图像生成:根据文本描述创建新图像。
- 图像编辑:对现有图像进行修改,如添加、删除或替换图像中的元素。
- 图像恢复:修复受损的图像,如去除噪声、去模糊。
- 图像定位:根据文本提示在图像中定位对象。
- 密集图像预测:进行深度估计、表面法线估计、姿态估计和语义分割等。
主要特点:
- 任务统一化:PixWizard能够将多种视觉任务统一为图像到图像的翻译问题。
- 数据构建:研究者们构建了一个包含3000万个数据点的综合性训练集,涵盖了多种视觉任务。
- 架构设计:PixWizard基于扩散变换器(Diffusion Transformers,DiT)构建,具有很好的可扩展性,并能够处理任意分辨率的图像。
工作原理:
- 文本编码器:使用文本编码器(如Gemma-2B和CLIP文本编码器)来理解语言指令。
- 结构感知和语义感知指导:结合输入图像的结构特征和语义信息来生成符合指令的图像。
- 动态分区和填充方案:允许模型处理任意分辨率的图像,更好地模拟人类的视觉处理过程。
具体应用场景:
- 艺术创作:根据文本描述生成艺术作品。
- 照片编辑:使用自然语言指令来编辑照片,如“去除图片中的行人”或“给这个人加上墨镜”。
- 图像恢复:修复老照片或因技术原因损坏的图像,如去除照片中的雨滴或模糊。
- 辅助视觉障碍人士:帮助视觉障碍人士理解图像内容,例如通过语言描述图像。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











