
韩国研究人员提出了一种高效的潜在扩散模型KOALA,该模型可以用于文本到图像的生成,研究人员构建了T2I模型KOALA-1B和KOALA-700M,减小了模型大小,降低了模型对硬件的需求,提高了模型运行速度,同时保证良好的图像生成质量。KOALA模型可以作为资源受限环境中SDXL模型的成本效益替代品。
KOALA模型通过知识蒸馏(Knowledge Distillation, KD)技术,从Stable Diffusion XL(SDXL)模型中提取知识,以创建一个更高效的模型,同时保持生成图像的质量。
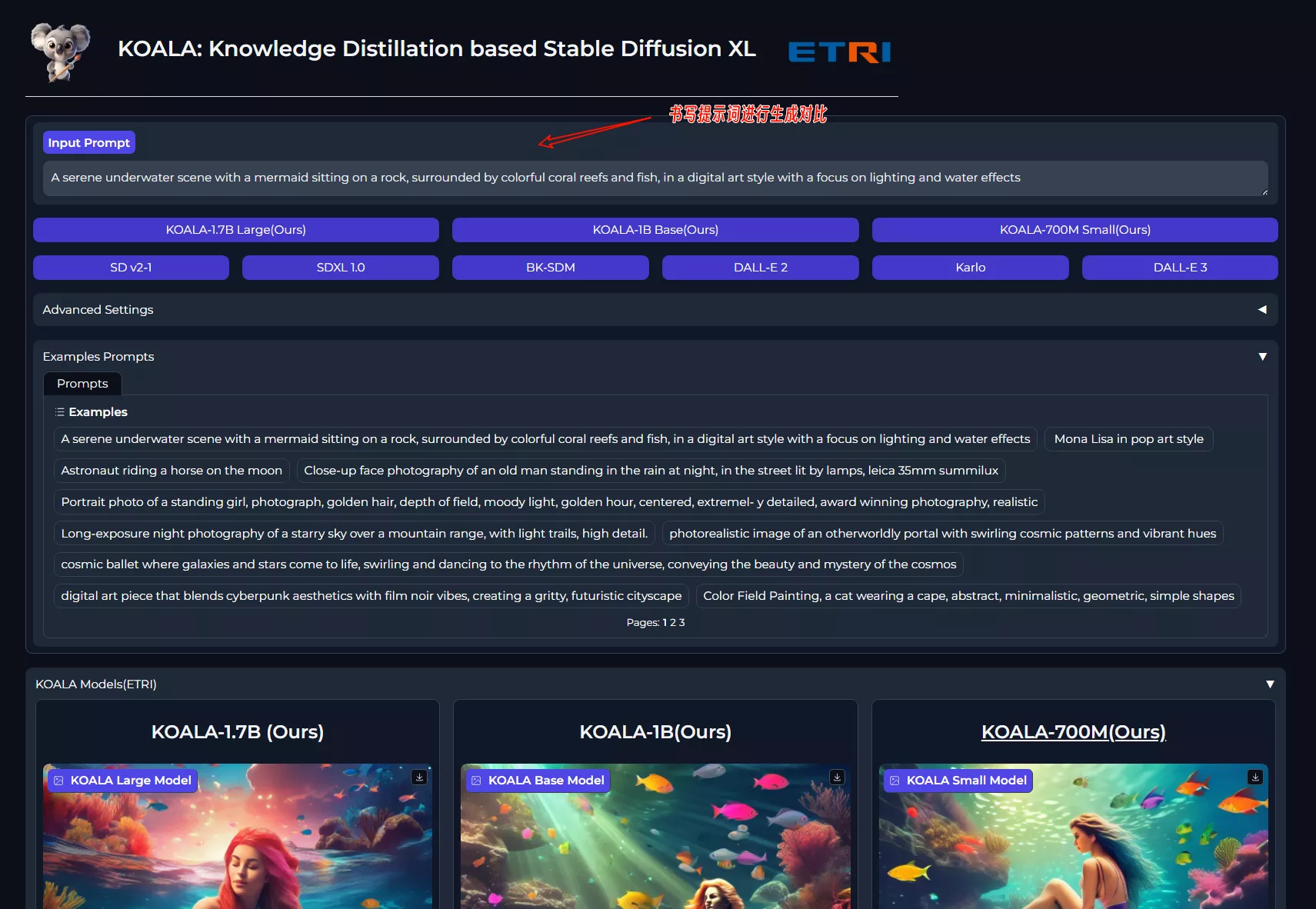
KOALA模型提供了一个在资源受限环境中生成高质量图像的有效解决方案,它通过知识蒸馏技术,使得小型模型也能够达到大型模型的图像生成效果。

主要功能:
- 高效的图像合成:KOALA模型能够在保持图像质量的同时,显著减少模型大小和推理时间。
- 知识蒸馏:通过从大型模型(如SDXL)中提取关键知识,KOALA能够在较小的模型中复现高质量的图像生成能力。
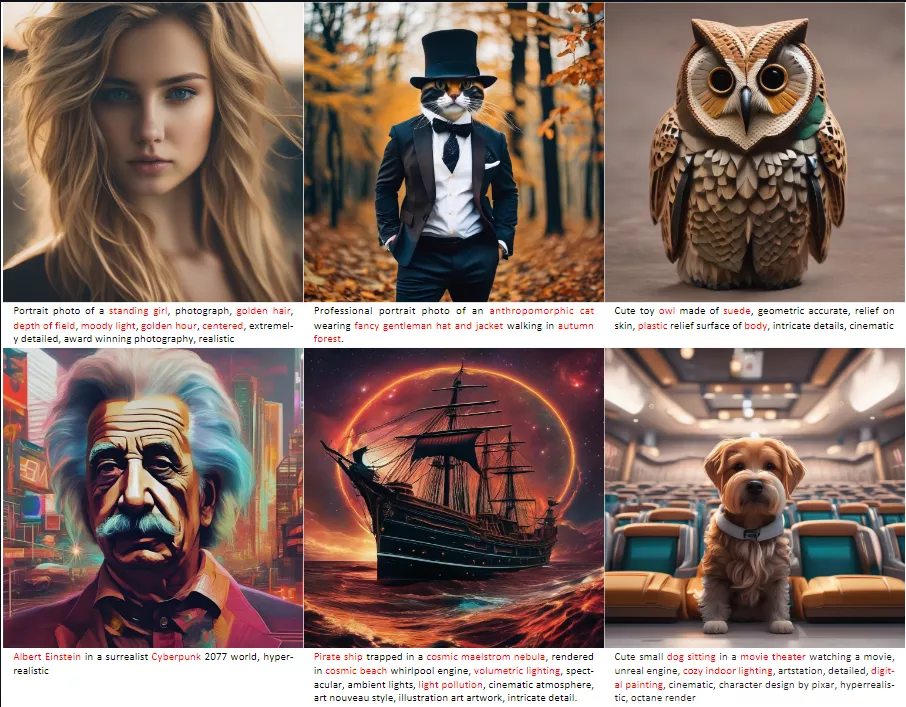
主要特点:
- 模型大小和速度的优化:KOALA模型的大小比原始的SDXL模型小了54%到69%,同时推理速度提高了两倍。
- 自注意力(Self-Attention)的重要性:研究发现,在知识蒸馏过程中,自注意力特征是最关键的部分,因为它们能帮助模型更好地区分和理解图像中的对象和属性。
工作原理:
KOALA模型首先对SDXL中的去噪U-Net进行了深入分析,然后设计了一个更高效的U-Net。接着,研究者们探索了如何有效地将SDXL的生成能力蒸馏到这个高效的U-Net中。这个过程包括了对特征级别的知识蒸馏,特别是自注意力特征,因为它们对于捕捉图像的语义信息至关重要。
KOALA模型与其他现有的文生图模型相比,具有以下优势和不足:
优势:
- 资源效率:KOALA模型显著减少了模型大小,使得它能够在资源受限的环境中运行,如具有较小内存的GPU或移动设备。这使得KOALA在硬件要求上更加灵活,易于部署。
- 快速推理时间:KOALA模型的推理速度比SDXL快两倍,这意味着用户可以更快地获得生成的图像,提高了用户体验。
- 自注意力的重要性:KOALA模型强调了自注意力特征在知识蒸馏过程中的关键作用,这有助于模型更好地理解和区分图像中的对象和属性,从而提高生成图像的质量。
- 成本效益:由于KOALA模型的高效性,它在运行成本上更低,这对于需要大量图像生成的应用场景(如游戏开发、虚拟现实等)尤其有吸引力。
不足:
- 特定场景的挑战:尽管KOALA在大多数情况下能够生成高质量的图像,但在处理复杂场景(如包含多个属性的复杂文本提示、可读文本的渲染、精细结构细节的捕捉以及人手的准确描绘)时可能会遇到困难。
- 数据集依赖性:KOALA模型的性能在一定程度上依赖于训练数据集的质量和多样性。如果训练数据集不够丰富或存在偏差,可能会影响模型在某些类型的图像生成任务上的表现。
- 知识蒸馏的限制:虽然知识蒸馏是一种有效的技术,但它可能无法完全复制大型模型的所有能力。在某些情况下,KOALA可能无法达到与原始大型模型相同的图像生成质量。
- 创新性:KOALA模型在很大程度上依赖于现有的技术(如SDXL和知识蒸馏),在模型架构和训练方法上的创新可能不如其他一些最新的T2I模型。
KOALA模型在资源效率和推理速度方面具有明显优势,但在处理特定复杂场景和数据集依赖性方面可能存在一些局限性。尽管如此,KOALA仍然是一个在资源受限环境中生成高质量图像的有力工具。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











