
石溪大学和Adobe 研究中心的研究人员推出长视频生成新方法PA-VDM,它能够生成高质量的长视频。在解释这个主题时,我们可以把它想象成一个能够将静态图片或简短视频变成长篇电影的魔法盒子。
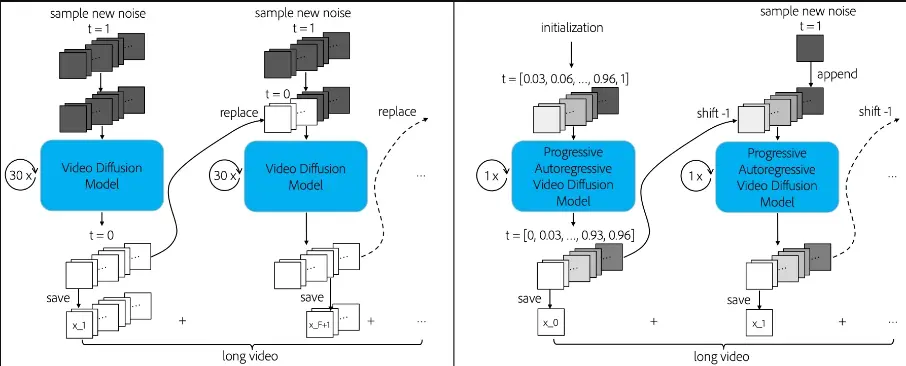
在这项工作中,研究团队展示了现有的模型可以自然地扩展为自回归视频扩散模型,而无需改变架构。PA-VDM的关键思想是为潜在帧分配逐渐增加的噪声水平,而不是单一的噪声水平,这允许潜在帧之间的细粒度条件和注意力窗口之间的大重叠。这种渐进式视频去噪使我们的模型能够自回归地生成视频帧,而不会出现质量下降或突然的场景变化。PA-VDM在1分钟(1440帧,24 FPS)的长视频生成方面展示了最先进的结果。
主要功能:
PA-VDM的主要功能是生成长时间视频。通常,现有的视频生成模型只能制作大约10秒(或240帧)的短视频。但PA-VDM能够突破这个限制,生成长达1分钟(1440帧)的连续视频,而且视频质量不会随着时间的延长而下降。
主要特点:
- 渐进式噪声水平:PA-VDM通过为视频的每一帧分配逐渐增加的噪声水平,而不是传统的单一噪声水平,这允许在帧之间建立更精细的条件关系,并在注意力窗口之间实现更大的重叠。
- 自回归视频去噪:这种方法可以逐步建立连续帧之间的关联,使得后续帧能够跟随早期帧的模式,从而实现更平滑的时间过渡和更好的运动保持。
- 无需额外计算成本:与之前需要生成重叠视频片段的方法相比,PA-VDM在实现更大重叠的同时,不需要额外的计算成本。
工作原理:
PA-VDM的工作原理可以分为以下几个步骤:
- 训练阶段:在训练阶段,模型被调整为适应每帧不同的噪声水平,这与传统的视频生成模型不同,后者通常对所有帧使用相同的噪声水平。
- 采样阶段:在生成视频时,从噪声水平最高的帧开始,逐步减少噪声,生成连续的视频帧。
- 自回归生成:每生成一帧,就将其移至帧序列的前端,并在序列末尾添加一个新的噪声帧,然后继续去噪过程,直到生成整个视频。
具体应用场景:
- 电影制作:在电影制作中,PA-VDM可以用来生成长篇特效场景,减少人工制作的成本和时间。
- 视频游戏:在视频游戏中,PA-VDM可以用于生成动态背景视频,提供更加丰富和连续的游戏世界体验。
- 虚拟现实:在虚拟现实应用中,PA-VDM可以生成长时间的虚拟环境视频,为用户提供沉浸式体验。
- 社交媒体:用户可以利用PA-VDM将短暂的生活瞬间扩展成长视频,用于社交媒体分享。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











