
- 项目主页:https://ytaek-oh.github.io/fsc-clip
- GitHub:https://github.com/ytaek-oh/fsc-clip
- 模型:https://huggingface.co/ytaek-oh/fsc-clip
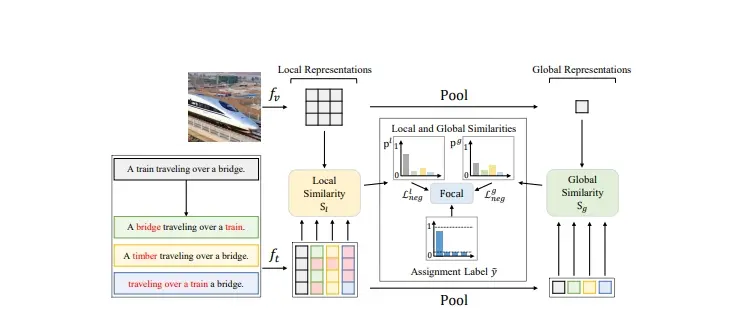
FSC-CLIP集成了局部硬负样本损失和选择性校准正则化。这些创新提供了细粒度的负样本监督,同时保持了模型的表示完整性。研究团队在多样化的基准测试中对组合性和多模态任务进行了广泛的评估,结果显示FSC-CLIP不仅在组合性方面达到了与最先进模型相媲美的水平,而且还保持了强大的多模态能力。
例如,你有一张图片,上面是一只猫站在桌子上。现在,你想知道计算机能否理解这张图片的内容,并用语言描述出来。或者反过来,如果你有一句话“一只猫站在桌子上”,计算机能否从一堆图片中找出正确的那张。这就是视觉和语言模型需要解决的问题。
主要功能:
- 提升组合理解能力:让模型能够理解由多个元素组成的复杂场景,比如理解“一只戴着帽子的猫坐在沙发上”这样的描述。
- 保持多模态任务性能:在提升组合理解能力的同时,确保模型在其他视觉和语言任务上的表现不会下降,比如图片分类或者图文匹配。
主要特点:
- 局部硬负例损失(Local Hard Negative Loss):这是一种新的损失函数,它关注图像和文本之间的局部对应关系,而不是全局的相似度。
- 选择性校准正则化(Selective Calibrated Regularization):这是一种正则化技术,它可以减少硬负例损失对模型性能的负面影响。
工作原理:
这个模型通过在训练过程中引入局部硬负例损失来提升组合理解能力。这意味着模型会学习区分正确和错误的图文匹配,即使是那些非常相似的错误匹配。同时,选择性校准正则化帮助模型在面对这些挑战性的负例时,不会损害其在其他任务上的性能。
具体应用场景:
- 图像搜索:用户可以上传一张图片,模型会从数据库中找出与之最匹配的图片描述。
- 自动标签生成:为社交媒体上的图片自动生成描述性的标签或标题。
- 辅助视障人士:帮助视障人士理解图片内容,通过文字描述来“看到”图像。
- 智能助理:在智能助理中,模型可以帮助理解用户的图文查询,提供更准确的回答和建议。
总的来说,这篇论文提出的方法是让计算机在理解图像和文字的组合信息时更加聪明,这对于提高人工智能系统的交互性和实用性是非常重要的。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











