在AI领域,开源模型的发展一直是推动技术进步和创新的重要力量。AMD宣布推出 Instella,这是一系列完全开源的语言模型,基于 AMD Instinct™ MI300X GPU 从头训练,参数量达 30 亿。
- GitHub:https://github.com/AMD-AIG-AIMA/Instella
- 模型:https://huggingface.co/collections/amd/instella-67c8a2c56e9198c85a97dd08
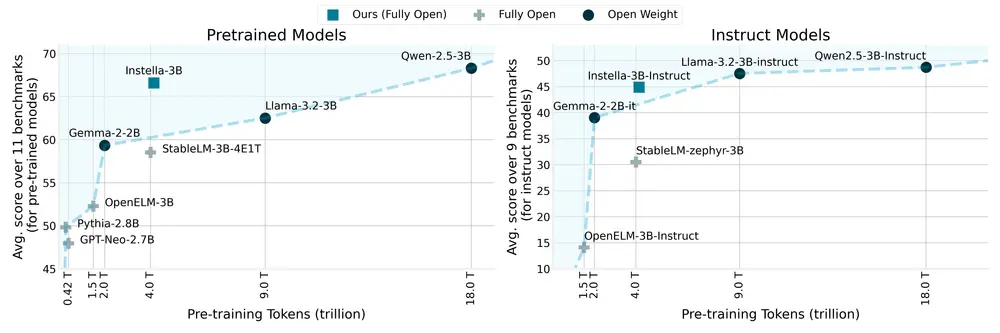
Instella 不仅在性能上超越了现有相似规模的开源模型,还与当前最先进的开源权重模型(如 Llama-3.2-3B、Gemma-2-2B 和 Qwen-2.5-3B)及其指令调优版本相媲美。这一成果不仅展示了 AMD 硬件在处理大规模 AI 训练工作负载方面的能力,也体现了 AMD 对开源社区的持续承诺。
核心亮点
- 性能卓越:Instella 模型在性能上显著优于现有相似规模的完全开源语言模型,并接近最先进的开源权重模型及其指令调优版本。
- 完全开源:AMD 开源了模型权重、训练超参数、数据集和代码,推动 AI 社区内的创新与协作。
- 高效训练技术:依托 AMD ROCm 软件栈,Instella 采用了 FlashAttention-2、Torch Compile 和混合分片的完全分片数据并行(FSDP)等技术,实现了大规模集群上的高效训练。
- 硬件优势:Instella 在 128 块 Instinct MI300X GPU 上从头训练,展示了 AMD 硬件在处理大规模 AI 训练工作负载方面的能力和可扩展性。
Instella 模型架构与训练
模型架构
Instella 是基于自回归 Transformer 的纯文本语言模型,具有以下特点:
- 参数量:30 亿参数。
- 层数:36 个解码器层。
- 注意力头数:每层 32 个注意力头。
- 上下文长度:支持最长 4096 个 token 的序列长度。
- 分词器:使用 OLMo 分词器,词汇量约为 50,000 个 token。
- 训练技术:采用 FlashAttention-2、Torch Compile 和 bfloat16 混合精度训练,优化内存占用和计算速度。
训练阶段
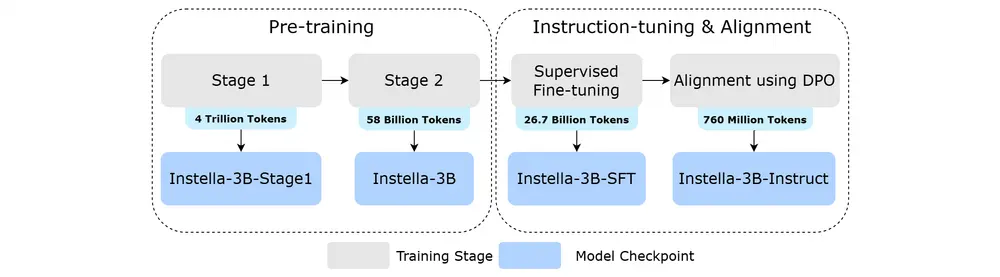
Instella 的训练分为四个阶段,逐步增强模型的能力:
- 预训练(第一阶段):Instella-3B-Stage1,使用 4.065 万亿个 token 进行训练,专注于自然语言理解能力。
- 预训练(第二阶段):Instella-3B,使用 575.75 亿个 token 进行训练,进一步增强问题解决能力。
- 监督微调(SFT):Instella-3B-SFT,使用 89.02 亿个 token(3 轮)进行训练,赋予模型指令跟随能力。
- DPO 对齐:Instella-3B-Instruct,使用 7.6 亿个 token 进行训练,通过直接偏好优化(DPO)对齐人类偏好,增强对话能力。
训练硬件
- GPU 配置:使用 128 块 Instinct MI300X GPU,分布在 16 个节点上,每个节点配备 8 块 GPU。
- 并行技术:采用混合分片的完全分片数据并行(FSDP),在节点内分片模型参数、梯度和优化器状态,在节点间复制,平衡内存效率和通信开销。
模型性能与评估
性能表现
Instella 在多个基准测试中表现出色,显著优于现有相似规模的开源模型,并接近最先进的开源权重模型及其指令调优版本。具体表现如下:
- 自然语言理解:在预训练阶段,Instella 展示了强大的语言生成和理解能力。
- 指令跟随:通过监督微调(SFT),Instella 能够准确理解和执行复杂的指令。
- 对话能力:通过 DPO 对齐,Instella 在对话场景中表现出色,能够生成自然流畅的对话内容。
评估基准
- OLMES:用于评估模型的语言理解和生成能力。
- FastChat MT-Bench:用于评估模型的对话能力和指令跟随能力。
- Alpaca:用于评估模型的任务执行能力。
开源资源
AMD 开源了与 Instella 模型相关的所有资源,包括:
- 模型权重:提供完整的模型权重,方便用户直接使用。
- 训练超参数:提供详细的训练配置,帮助用户复现和优化训练过程。
- 数据集:提供训练和评估所用的数据集,支持用户进行进一步的研究和开发。
- 代码:提供完整的训练和推理代码,促进社区内的协作和创新。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











