
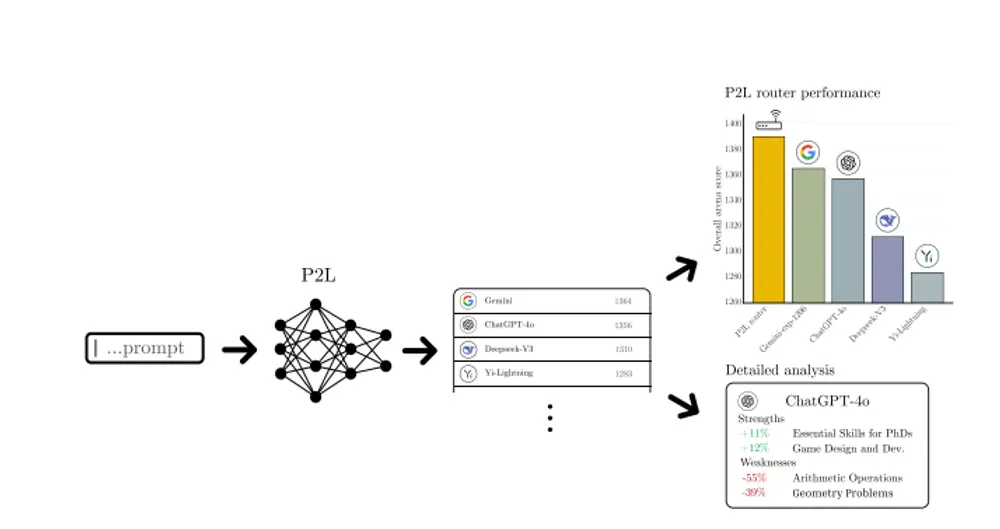
LMArena 推出了 Prompt-to-Leaderboard(P2L),这是一种创新方法,旨在通过自然语言提示生成针对特定使用场景的实时大语言模型(LLM)排行榜。P2L 的核心思想是训练一个大型语言模型,使其能够根据输入的提示生成“特定于提示”的排行榜,从而帮助用户更精准地评估和选择适合其需求的语言模型。
背景与挑战
传统的大语言模型评估通常依赖于准确率或人类偏好等聚合指标,这些指标通过对用户和提示进行平均计算得出。然而,这种平均化的方法掩盖了模型在特定用户群体或特定提示下的性能差异。例如,在游戏开发中,开发者可能需要选择最适合处理 SQL 查询的语言模型,但传统的排行榜可能无法提供足够的细节,因为 SQL 查询仅占总提交的一小部分(如 0.6%)。这使得开发者难以找到最适合其任务的模型。
为了解决这一问题,LMArena 提出了 Prompt-to-Leaderboard (P2L) 方法,该方法能够生成针对特定提示或提示集的排行榜,从而实现对模型性能的细粒度评估。
- GitHub:https://github.com/lmarena/p2l
- 模型:https://huggingface.co/collections/lmarena-ai/prompt-to-leaderboard-67bcf7ddf6022ef3cfd260cc
- Demo:https://lmarena.ai/?p2l
例如,在游戏开发中,开发者可能需要选择最适合处理 SQL 查询的语言模型。传统的排行榜可能无法提供足够的细节,因为 SQL 查询仅占总提交的 0.6%。而 P2L 可以针对 SQL 查询生成一个专门的排行榜,帮助开发者快速找到最适合的模型。
主要功能
- 生成特定提示的排行榜:P2L 能够根据输入的提示生成一个排行榜,量化不同模型在该提示下的表现。
- 个性化评估:通过聚合多个提示的排行榜,P2L 可以为用户或企业生成个性化的模型推荐。
- 最优查询路由:P2L 可以根据提示动态选择最适合的模型,优化查询的分配,提高整体性能。
- 自动分析模型优缺点:通过细粒度的评估,P2L 能够自动识别模型在不同任务中的强项和弱项。
主要特点
- 细粒度评估:P2L 能够捕捉模型在不同提示下的性能差异,而不仅仅是平均表现。
- 高效性:P2L 在训练时利用人类偏好反馈,能够快速生成排行榜,无需大量数据。
- 可扩展性:P2L 的性能随着模型规模和数据量的增加而提升,适用于大规模应用场景。
- 隐私保护:P2L 的输出仅基于输入提示和模型性能,不涉及用户数据的泄露。
- 灵活性:P2L 可以扩展到其他类型的反馈模型(如平局、实值反馈等),通过参数化统计模型进行建模。
工作原理
- 数据收集与建模:
- 收集人类对模型输出的偏好数据(如成对比较)。
- 使用 Bradley-Terry (BT) 模型或其他参数化统计模型,将提示映射到模型性能的向量(排行榜)。
- 训练 P2L 模型:
- 将预训练的语言模型的输出头替换为一个系数头,输出每个模型的 BT 系数。
- 使用最大似然估计或负对数似然损失进行训练,优化模型以预测人类偏好。
- 生成排行榜:
- 对于每个提示,P2L 模型输出一个向量,表示不同模型在该提示下的表现。
- 这些向量可以用于生成特定提示的排行榜,或通过聚合生成个性化排行榜。
- 最优路由策略:
- 基于生成的排行榜,P2L 可以动态选择最适合当前提示的模型,优化查询分配。
- 通过线性规划等方法,P2L 可以在成本约束下最大化性能。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











