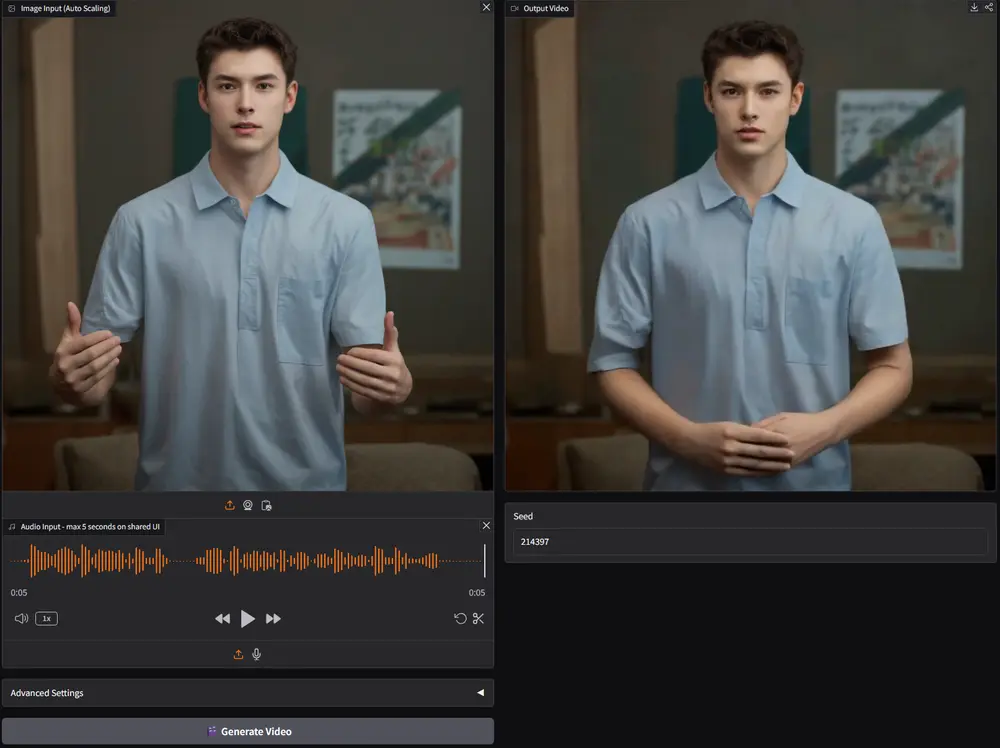
由加州大学伯克利分校、麻省理工学院、斯坦福大学、德克萨斯大学奥斯汀分校与 First Intelligence 联合研发的 StreamDiffusionV2 正式开源。这是一个面向交互式直播场景的实时扩散模型处理管线,旨在解决现有视频生成系统在低延迟、高帧率和时间一致性方面的关键挑战。
相比早期基于图像扩散模型的方案(如原始 StreamDiffusion),V2 版本全面转向视频扩散架构(Wan2.1-T2V-1.3B),在保持低延迟的同时显著提升了动态内容的时间连贯性,适用于风格迁移、虚拟直播、创意视觉特效等实时应用。
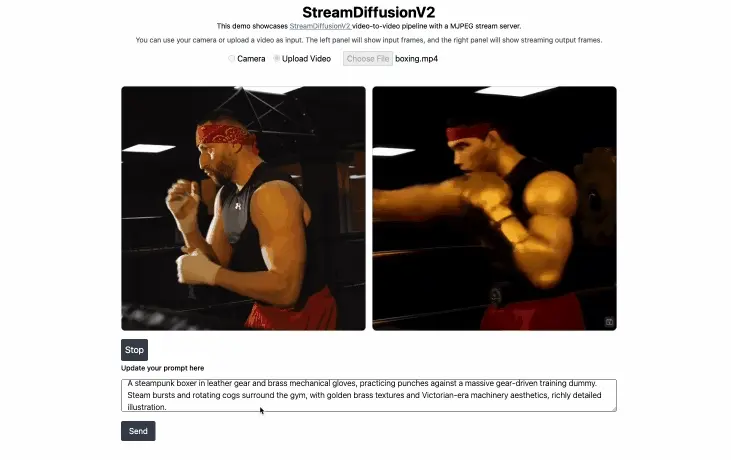
项目代码与文档已在 GitHub 公开,支持多 GPU 部署,且无需 TensorRT 或量化即可实现高性能推理。
为什么需要新的实时生成系统?
当前主流视频生成模型多为离线设计,侧重于批量处理以优化吞吐量,不适用于直播这类对单帧响应时间敏感的场景。
而在线流媒体面临的核心约束包括:
- 每帧必须在固定截止时间内完成(通常 <100ms);
- 输入节奏不稳定,需应对突发请求或用户交互;
- 需支持分辨率、降噪步数等参数动态调整。
为此,StreamDiffusionV2 构建了一套从算法到系统的协同优化框架,满足创作者和平台对高帧率、低抖动、灵活配置的需求。
核心特性一览
| 特性 | 说明 |
|---|---|
| 支持模型 | 基于 Causal-DiT 视频扩散架构(源自 CausVid) |
| 实时性能 | 单张 RTX 4090 上可达 8.6 FPS(1 步降噪,512×512);4×H100 达 42 FPS(4 步) |
| 分辨率支持 | 支持 512×512 和 832×480 等常见直播尺寸 |
| 多GPU扩展 | 支持流水线并行,在消费级与企业级硬件均可部署 |
| 动态控制 | 支持运行时调整降噪步数(1–4 步)、分辨率、批大小 |
| 开源协议 | MIT 许可,可用于商业用途 |
该系统已在远程服务器上用于演示宠物/人物风格化直播,轻微卡顿主要源于网络传输延迟(50–300ms),非本地推理问题。
关键技术创新
1. 流水线并行 + 动态流批处理
为适配不同硬件条件,StreamDiffusionV2 采用流水线并行将模型拆分至多个 GPU。但传统做法难以提升效率——因视频扩散计算密集,易造成瓶颈。
团队发现,VAE 编解码模块导致设备负载不均。为此提出:
- 动态调度器:根据运行时实测延迟自动重分配模块;
- 流批处理机制:在内存受限前提下通过小批量叠加提升吞吐量。
这使得即使在无 NVLink 的消费级显卡(如 RTX 4090)上也能实现稳定输出。
✅ 在 512×512 分辨率下,双卡 RTX 4090 可达 16.6 FPS(1 步),单卡达 8.6 FPS。
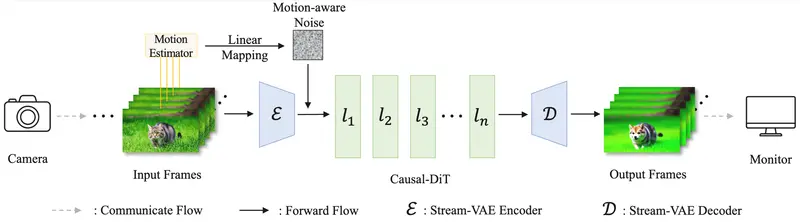
2. Stream-VAE:低延迟视频编码器
传统 VAE 处理长序列,带来高延迟。StreamDiffusionV2 引入 Stream-VAE,每次仅处理短片段(如 4 帧),并通过缓存特征保持跨帧一致性。
这一设计兼顾了:
- 推理速度(降低编码延迟);
- 时间稳定性(避免闪烁或跳变);
- 内存占用可控(适合长时间运行)。
3. 滚动 KV 缓存 + Sink Token
为了维持长时间生成中的风格一致,系统采用改进的 滚动 KV 缓存机制:
- 不维护无限长缓存,而是设定最大长度;
- 引入 Sink Token,保留关键上下文信息,在滚动更新中防止风格漂移;
- 当时间戳超过阈值时主动重置位置编码,避免 RoPE 越界导致视觉异常。
这套机制支持无限长度视频流生成,适用于持续直播场景。
4. 运动感知噪声控制器
高速运动常导致生成画面模糊或断裂。为此,团队提出一种无需训练的自适应方法:
- 计算连续帧间的均方误差(MSE)作为运动强度指标;
- 将其线性映射为初始噪声水平;
- 强运动 → 更高噪声 → 更强重构能力;
- 弱运动 → 低噪声 → 更平滑过渡。
该控制器可在不修改模型权重的情况下,动态平衡生成质量与运动连续性。
应用场景示例
StreamDiffusionV2 已验证以下使用模式:
- 🐾 宠物直播风格化
摄像头捕捉宠物活动,实时转换为动漫、油画或赛博朋克风格,适合内容创作者打造个性化频道。 - 👤 人物形象重塑
视频博主可将自己置于幻想世界背景中,实现虚拟角色直播,类似虚拟偶像但无需预渲染。 - 🎨 创意视觉特效集成
可接入 TouchDesigner、OBS 等工具链,用于现场演出、艺术装置或互动展览。
所有演示均基于远程服务运行,本地推理性能可通过配置进一步优化。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...