在高分辨率、长时序视频生成任务中,扩散变换器(Diffusion Transformer, DiT)已成为主流架构。然而,其核心组件——自注意力机制——面临着一个根本性瓶颈:计算复杂度随序列长度呈平方级增长(O(N²))。
对于一段包含数万时间步的视频 latent 序列,传统注意力不仅消耗巨大显存,更成为推理延迟的主要来源。尽管已有稀疏注意力和线性注意力等优化方案,但往往面临“降速不提质”或“损失生成质量”的困境。
为此,清华大学与加州大学伯克利分校的研究团队联合提出 SLA(Sparse-Linear Attention),一种全新的可训练混合注意力机制。它通过动态划分注意力权重并应用差异化计算策略,在将注意力复杂度降至 O(N) 的同时,几乎无损地保留原始生成质量。
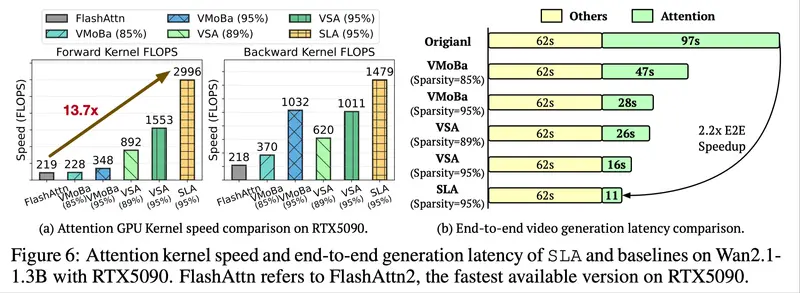
该方法已在 Wan2.1-1.3B 等主流 DiT 模型上验证,实现端到端 2.2 倍加速,注意力内核性能提升达 13.7 倍。
问题本质:为什么标准注意力是视频生成的瓶颈?
现代视频扩散模型通常将输入编码为高维 latent token 序列。例如:
- 分辨率:720×1280
- 帧率:16fps
- 时长:5秒 → 80帧
- 每帧 token 数:~46,656(来自VAE压缩)
总序列长度可达 数十万 tokens。在此规模下,标准注意力需计算 N×N 的相似度矩阵,带来以下问题:
| 问题 | 影响 |
|---|---|
| 显存占用过高 | 无法在单卡上运行长序列 |
| 计算量巨大 | 推理耗时长达分钟级 |
| 扩展性差 | 难以支持更长视频或更高分辨率 |
现有解决方案各有局限:
- 稀疏注意力:依赖固定模式(如局部窗口),高稀疏度下易丢失关键上下文;
- 线性注意力:基于核函数近似,对高秩、大权重注意力建模能力弱。
SLA 的目标,是融合二者优势,构建一种既高效又保质的通用注意力替代方案。
SLA 的核心思想:分而治之,按需计算
SLA 的设计基于一个重要观察:
注意力权重并非均匀分布,而是呈现出明显的“双模态”结构 —— 少数位置具有高影响力(关键),多数位置贡献微弱(边缘或可忽略)。
基于此,SLA 将注意力权重矩阵划分为块,并动态分类为三类:
| 类别 | 特征 | 处理方式 |
|---|---|---|
| 关键(Critical) | 高幅值、高秩,决定全局语义 | 使用 FlashAttention 精确计算 |
| 边缘(Marginal) | 幅值较低、低秩,提供补充信息 | 使用线性注意力近似处理 |
| 可忽略(Negligible) | 接近零,噪声为主 | 直接跳过计算 |
这种混合策略实现了真正的“按需分配”计算资源。
工作流程详解
1. 动态权重分类
在训练初期,模型通过少量前向传播收集注意力分布统计信息,利用聚类或阈值方法将权重块自动标记为三类。这一过程可微调,具备任务适应性。
2. 分层计算执行
不同类别采用不同的计算路径:
- 关键块:使用 FlashAttention 或 Memory-Efficient Attention 实现高性能精确计算;
- 边缘块:映射至核函数空间,通过线性递归聚合完成 O(N) 近似;
- 可忽略块:置零或直接绕过,不参与任何运算。
3. 统一融合输出
各分支结果在输出端统一拼接或加权融合,形成最终的注意力输出,并支持反向传播。
整个流程被封装为一个可插拔模块,仅需少量微调即可适配现有 DiT 架构。
性能表现:快 2.2 倍,FLOPs 降 95%
在 Wan2.1-1.3B 模型上的实测结果显示,SLA 在保持质量的前提下显著提升效率:
| 指标 | 原始(全注意力) | SLA | 提升/降低 |
|---|---|---|---|
| 注意力计算复杂度 | O(N²) | O(N) | ↓ 95% FLOPs |
| 注意力内核耗时 | 97 秒 | 11 秒 | ↑ 8.8× 内核加速 |
| GPU 内核效率 | - | - | ↑ 13.7× 吞吐提升 |
| 端到端生成时间 | 320 秒 | 144 秒 | ↑ 2.2× 加速 |
值得注意的是,这些优化是在不改变模型结构、不牺牲分辨率与时长的前提下实现的。

生成质量评估:无明显退化
为了验证 SLA 是否影响视觉质量,研究团队在 VBench 等基准上进行了对比测试:
- CLIP Score:SLA 与全注意力模型相差 <0.5;
- 用户偏好测试:盲评中超过 48% 用户认为 SLA 输出质量“相当或更好”;
- 时间连贯性:运动轨迹平滑,未出现断裂或闪烁现象;
- 文本对齐度:关键语义元素(如物体、动作)准确还原。
这表明,SLA 的近似策略并未破坏模型的核心生成能力。
工程实现:高效 GPU 内核实现在
SLA 不只是一个算法设计,更是一次系统级优化。研究团队将其前向与反向传播完全融合进一个定制化的 CUDA 内核中:
- 支持动态分支判断;
- 减少内存往返次数;
- 最大化利用 Tensor Core;
- 与主流框架(PyTorch)无缝集成。
这一实现使得理论上的计算节省真正转化为实际的推理速度提升。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











