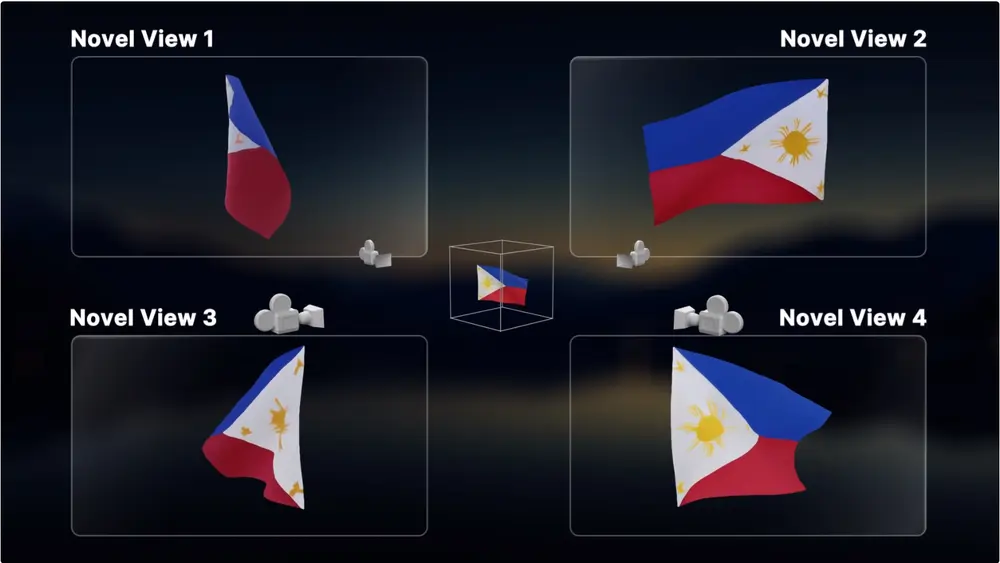
在视频生成领域,一个长期挑战是:如何让用户通过简单指令(如文本、草图或相机轨迹),灵活定制视频中一个或多个主体的外观、动作与空间关系?
由约翰·霍普金斯大学、Adobe 研究院、香港大学、香港中文大学与上海交通大学联合提出的工作 OmniVCus,提供了一种新的解决方案。它不依赖迭代优化,而是采用前馈式生成架构,结合多模态控制条件,实现高效、可控的主题驱动视频定制。
- 项目主页:https://caiyuanhao1998.github.io/project/OmniVCus
- GitHub:https://github.com/caiyuanhao1998/Open-OmniVCus
- 模型:https://huggingface.co/CaiYuanhao/OmniVCus
本仓库是基于论文公开方法与数据,使用公开代码重新训练的可复现实现,后续将持续完善。
核心能力:不止于“生成”,而是“定制”
OmniVCus 的目标不是从零生成一段视频,而是在已有主体基础上,按用户意图进行编辑与重组。其关键能力包括:
- 多主体定制:即使训练时仅见单主体,推理时也能生成包含多个主体的协调视频;
- 指令式编辑:通过自然语言指令修改主体姿态、动作或风格(如“将人物转为水彩风格”);
- 零样本组合:支持训练未见过的主体组合,实现泛化定制;
- 多模态控制:同时接受文本、深度图、掩码、相机轨迹等多种信号,精确引导生成过程。
例如,用户可提供一张人物图像 + 一段文本“跳舞”,再叠加一个深度图控制其在 3D 空间中的位置,OmniVCus 即可生成一段符合所有条件的视频。
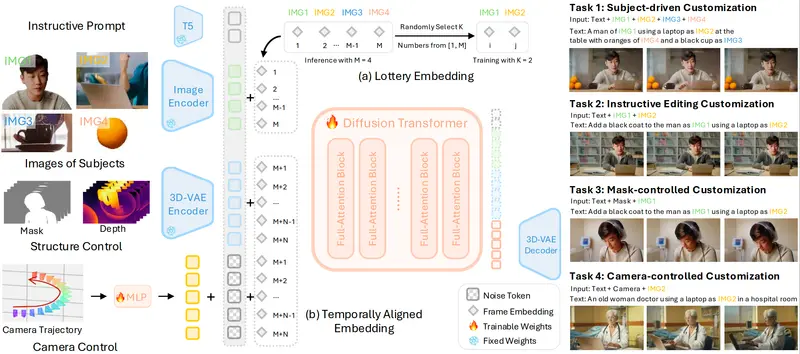
技术突破:三大关键设计
1. VideoCus-Factory:自动构建训练数据对
现有方法缺乏高质量的“输入-输出”视频定制对。OmniVCus 提出 VideoCus-Factory 数据构建管道,从无标签原始视频中自动:
- 使用多模态大模型(如 Kosmos-2)检测主体并生成语义描述;
- 提取深度图、实例掩码、相机轨迹等控制信号;
- 通过数据增强与过滤,构建可用于训练的多主体定制样本。
这解决了多主体视频定制缺乏监督信号的根本问题。
2. Lottery Embedding(LE):突破主体数量限制
训练时仅使用有限数量的主体,但希望推理时支持任意数量组合?OmniVCus 引入 Lottery Embedding 机制:
- 在训练阶段,通过稀疏激活策略,让有限主体“激活”更多帧级嵌入;
- 推理时,这些嵌入可被新主体复用,实现超训练规模的主体定制。
3. Temporally Aligned Embedding(TAE):提升时序控制精度
为确保控制信号(如深度图序列)与视频帧严格对齐,OmniVCus 设计 TAE:
- 为噪声标记与对应控制信号分配相同的帧嵌入;
- 使模型在去噪过程中天然对齐时空信息,显著提升动作连贯性与空间一致性。
4. Image-Video Transfer Mixed(IVTM)训练
将图像编辑任务(如风格迁移、局部重绘)与视频定制任务混合训练,使模型学会:
- 将图像级编辑能力迁移到视频时序中;
- 实现“指令式视频编辑”,如“给视频中的人物换衣服”。
模型架构
OmniVCus 基于 扩散 Transformer(DiT) 构建,将文本、参考图像、控制信号(深度/掩码/轨迹)等多模态输入统一编码为一维标记序列,通过前馈方式一步生成完整视频。
不同于需多次迭代或微调的方案,OmniVCus 无需 test-time optimization,生成速度快,适合实际部署。
实验结果
在多项基准测试中,OmniVCus 显著优于现有方法:
- 多主体协调性:生成的多主体视频在动作同步、空间布局上更合理;
- 控制保真度:深度图能准确控制主体远近,掩码可精准实现纹理替换;
- 指令对齐度:用户研究显示,其在“提示-视频匹配度”“主体身份保持”“整体质量”三项指标上均领先;
- 零样本泛化:可生成训练未见的主体组合(如“猫+汽车”共同运动)。
潜在应用场景
- 视频创作工具:创作者输入草图+文本,快速生成主题视频;
- 影视后期:根据剧本指令自动生成角色特定动作或场景;
- AR/VR 内容生成:动态生成符合用户交互意图的虚拟角色;
- 个性化广告:按品牌需求定制含特定主体与风格的短视频。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











