南京大学和腾讯人工智能实验室的研究人员推出人像视频生成框架V-Express,它用于生成高质量的人像视频。这项技术特别关注于如何平衡不同控制信号(如文本、音频、参考图像、姿态、深度图等)的强弱,以便在生成视频中实现更协调和有效的控制。研究人员未来的工作方向,包括支持多语言、减少计算负担和显式控制面部属性等。这些改进将进一步扩展V-Express的应用范围,并提高其性能和实用性。
- 项目主页:https://tenvence.github.io/p/v-express
- GitHub:https://github.com/tencent-ailab/V-Express
- 模型地址:https://huggingface.co/tk93/V-Express
- ComfyUI插件:https://github.com/tiankuan93/ComfyUI-V-Express
例如,你想要创建一个能够模仿真实人物说话的视频。使用V-Express,你可以提供一段音频、一个参考图像(显示人物的面部)和一些关键点图像(V-Kps),这些关键点图像显示了人物面部在不同时间点的姿态。V-Express将这些输入整合起来,生成一个视频,其中人物的嘴唇动作与音频同步,面部表情和姿态与V-Kps图像匹配,同时保持了参考图像中的背景和面部特征。
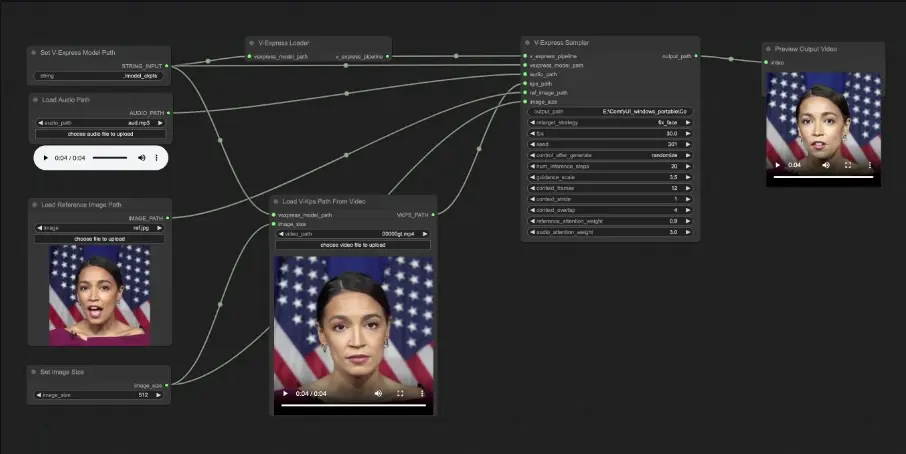
主要功能与特点:
- 平衡控制信号:V-Express能够处理不同强度的控制信号,特别是那些较弱的信号(如音频),这些信号在与较强的信号(如面部姿态和参考图像)竞争时常常会被掩盖。
- 渐进式训练:通过分阶段的渐进式训练方法,V-Express逐步实现了对弱控制信号的有效控制。
- 条件性dropout操作:为了平衡不同控制信号,V-Express采用了条件性dropout操作,这有助于防止模型学习到直接复制参考图像的捷径,而是更多地依赖于运动注意力层的指导。
- 高质量视频生成:实验结果表明,V-Express能够生成与音频同步的高质量人像视频,并保持面部身份和姿态的一致性。
工作原理:
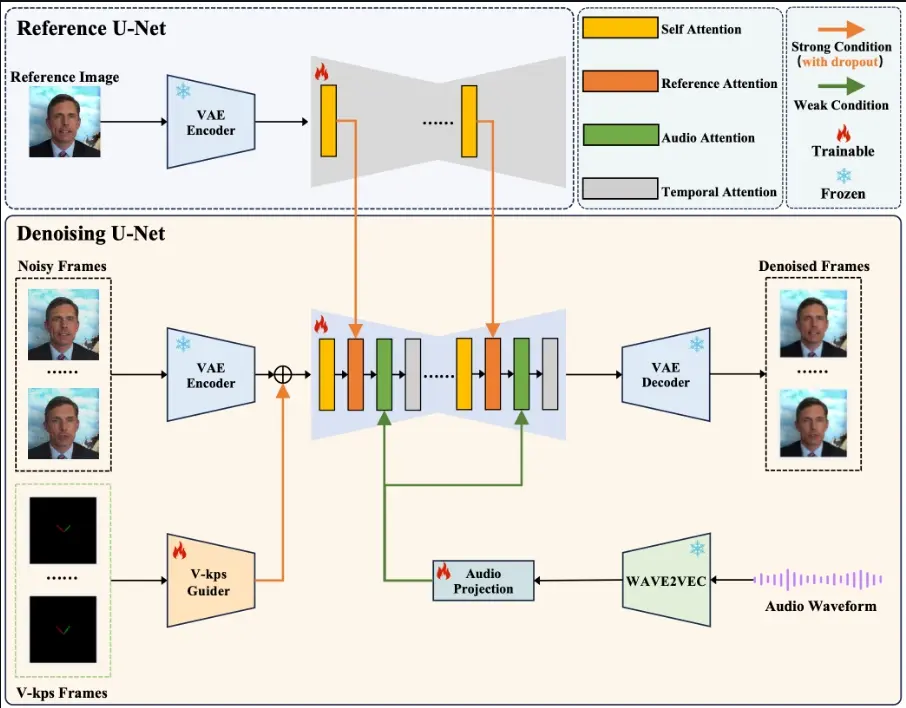
- Latent Diffusion Model (LDM):V-Express使用潜在扩散模型来生成视频帧,该模型通过变分自编码器(VAE)在潜在空间内执行扩散和逆扩散过程。
- ReferenceNet、V-Kps Guider和Audio Projection:这些模块分别用于编码参考图像、V-Kps图像和音频,以有效处理各种控制输入。
- 注意力层:V-Express的架构包括自注意力层和交叉注意力层,用于处理时间关系和空间关系。
- 运动注意力层:用于捕捉视频帧之间的时间依赖性,确保生成的帧展现出平滑和连贯的过渡。
具体应用场景:
- 虚拟头像:在虚拟现实或增强现实中创建逼真的虚拟角色。
- 数字娱乐:为游戏或电影制作高质量的动画视频。
- 个性化视频内容创作:允许用户通过音频和图像生成个性化的视频内容。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...