ComfyUI-LatentSyncWrapper是专门为ComfyUI设计的非官方节点,基于字节跳动的LatentSync框架,实现视频中嘴唇动作与音频输入的同步。借助这一工具,用户可以在ComfyUI环境中轻松生成唇音同步的视频内容。
先决条件
在安装和使用此节点之前,请确保您的ComfyUI 已经满足以下条件:
- ComfyUI 已正确安装并能够正常运行
- ComfyUI_AceNodes 节点,用于处理视频输入和输出。
- FFmpeg 已安装,并且路径已添加到系统的环境变量中(相关:ffmpeg安装教程)
安装步骤
目前此节点还没在ComfyUI Manager上架,你可以手动进行安装,确认所有先决条件均已满足后,按照以下步骤进行安装:
将ComfyUI-LatentSyncWrapper仓库克隆到ComfyUI的custom_nodes目录中:
cd ComfyUI/custom_nodes
git clone https://github.com/ShymuelRonen/ComfyUI-LatentSyncWrapper.git
cd ComfyUI-LatentSyncWrapper
pip install -r requirements.txt
模型下载
首次使用时,节点将自动从HuggingFace下载所需的模型文件。这些模型包括:
- LatentSync UNet模型
- Whisper音频处理模型
您也可以选择手动下载模型,以避免初次运行时的网络延迟。模型可以从HuggingFace仓库获取,下载后请确保检查点文件放置在正确的路径下。
使用方法
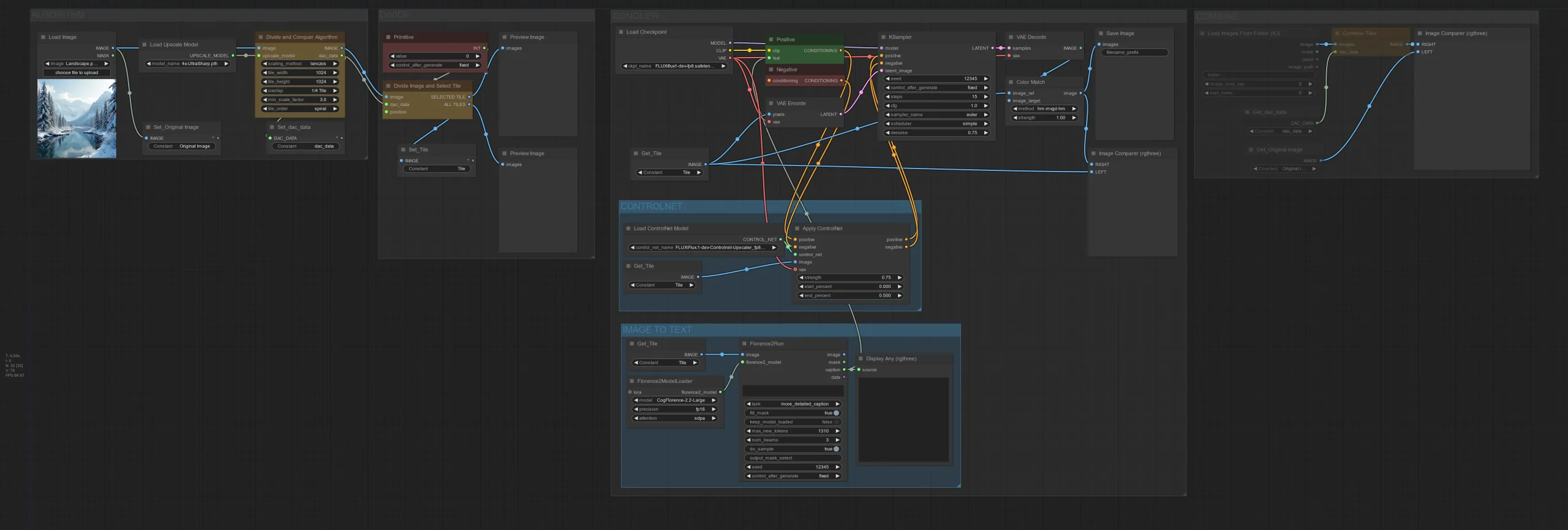
- 加载视频:使用AceNodes视频加载器选择输入视频文件。
- 加载音频:使用ComfyUI音频加载器加载音频文件。
- 设置种子值(可选):如果您希望每次生成的结果一致,可以设置一个随机种子值(默认值为1247)。
- 连接节点:将视频和音频输入连接到LatentSync节点。
- 运行工作流:启动工作流,处理后的视频将保存到ComfyUI的输出目录中。
节点参数
- video_path: 输入视频文件的路径。
- audio: 从AceNodes音频加载器获取的音频输入。
- seed: 用于生成可重复结果的随机种子(默认值:1247)。
已知限制
- 最佳效果:该节点最适合清晰、正面拍摄的人脸视频。
- 不支持动漫/卡通人脸:目前仅适用于真实人脸视频。
- 帧率要求:视频应为25 FPS,若不符合将自动转换。
- 人脸可见性:视频中的人脸应在整个过程中保持可见。
升级情况
字节跳动的LatentSync升级到1.5版,此节点也已实现对该模型的支持。
LatentSync 1.5 的新特性
时间层改进:修正后的实现相较于 1.0 版本显著提升了时间一致性。 更好的中文支持:通过额外的训练数据,大幅改善了对中文视频的表现。 降低显存需求:现在仅需 20GB 显存(可在 RTX 3090 上运行),得益于以下优化: 在 U-Net、VAE、SyncNet 和 VideoMAE 中使用梯度检查点技术。 使用原生 PyTorch FlashAttention-2 实现(无需依赖 xFormers)。 更高效的 CUDA 缓存管理。 针对时间层和音频交叉注意力层的聚焦训练。
代码优化: 移除了对 xFormers 和 Triton 的依赖。 升级到 diffusers 0.32.2。
使用方法
使用 AceNodes 视频加载器选择输入视频文件。 使用 ComfyUI 音频加载器加载音频文件。 (可选)设置一个种子值以获得可重复的结果。 (可选)调整 lips_expression参数以控制唇部运动强度。(可选)修改 inference_steps参数以平衡质量和速度。将流程连接到 LatentSync1.5 节点。 运行工作流。
处理后的视频将保存在 ComfyUI 的输出目录中。
节点参数
video_path:输入视频文件的路径。 audio:从 AceNodes 音频加载器获取的音频输入。 seed:用于生成可重复结果的随机种子(默认值:1247)。 lips_expression:控制唇部运动的表现力(默认值:1.5)。 较高值(2.0-3.0):唇部运动更明显,适合表达性较强的语言。 较低值(1.0-1.5):唇部运动更微妙,适合平静的语言。 该参数影响模型的引导比例,在自然运动和唇形同步精度之间取得平衡。
inference_steps:推理过程中的去噪步数(默认值:20)。 较高值(30-50):结果质量更高,但处理速度较慢。 较低值(10-15):处理速度更快,但可能质量较低。 默认值 20 通常能在质量和速度之间取得良好平衡。
提升效果的小技巧
对于演讲或需要清晰唇部动作的场景,尝试将 lips_expression值提高到 2.0-2.5。对于日常对话,默认值 1.5 通常表现良好。 如果唇部动作显得不自然或过于夸张,尝试降低 lips_expression值。不同语言和语音模式可能需要不同的参数值。 如果需要更高质量的结果且可以等待,将 inference_steps提高到 30-50。对于快速预览或不太关键的应用,可将 inference_steps降低到 10-15。
已知限制
最适合正面清晰的人脸视频。 目前不支持动漫/卡通面孔。 视频应为 25 FPS(会自动转换)。 视频中人脸需全程可见。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











