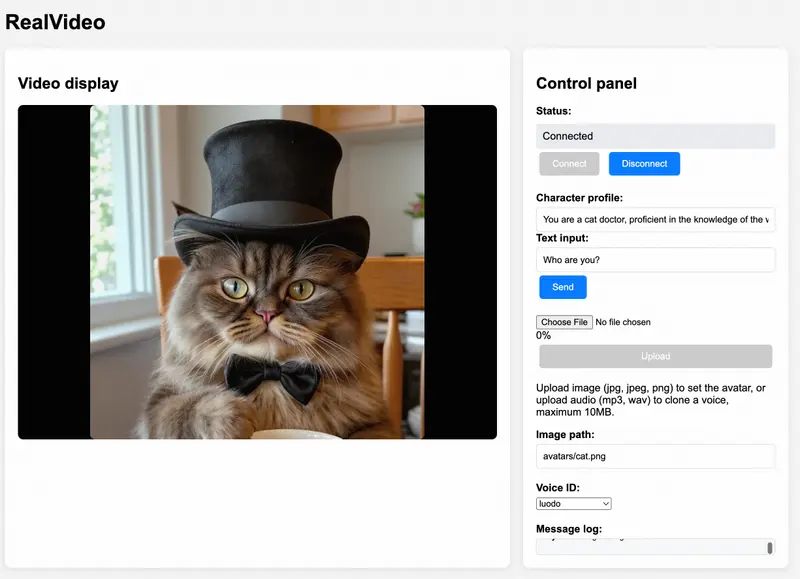
字节跳动研究团队推出了Seaweed APT2,一款专为实时交互式场景设计的流式视频生成模型。该模型能够在单块H100 GPU上实现每秒24帧、分辨率高达736x416(等效640x480)的不间断视频生成,且支持长达一分钟的连续输出。相比现有方法,在速度与效率方面实现了显著提升。

核心技术亮点
实时流式生成,低延迟高效率
Seaweed APT2采用自回归方式逐帧生成视频,每次生成一个潜在帧(包含4个实际视频帧),并通过KV缓存机制确保推理过程中计算量始终维持在1NFE(单次网络前向评估)。这种设计使得模型可以在极低延迟下持续输出视频流。
- 性能表现:
- 单卡H100即可实现实时24fps输出
- 支持分辨率达736x416(等效640x480)
- 可生成长达1分钟(1440帧)的视频
- 相比前代APT1,生成帧数提升近30倍
高分辨率支持
在多GPU环境下,Seaweed APT2还能实现更高清的视频生成:
- 使用8块H100 GPU,可实时生成1280x720分辨率视频
- 保持1NFE计算量的前提下,生成质量稳定,无明显退化
交互式应用场景展示
Seaweed APT2不仅支持高质量视频生成,还具备强大的交互控制能力,适用于多种实时互动场景。
虚拟人类生成
用户可以通过上传初始图像指定人物身份,并通过姿态控制实时调整虚拟人的动作。模型能够根据输入的姿态信号快速响应,生成符合预期的动作序列。
示例:用户上传一张正面人像后,通过姿态控制让虚拟人做出挥手、点头等动作。
世界探索模拟
用户还可以通过相机控制在虚拟环境中自由移动。模型根据相机位移和方向变化,动态生成对应的视角画面。
- 输入包括相机运动轨迹嵌入(位移与朝向)
- 输出为对应视角下的连续视频流
- 支持长时间沉浸式探索体验
创新架构设计
Seaweed APT2采用了对抗训练+自回归建模相结合的新范式,区别于传统扩散模型或基于标记预测的方法。
核心架构特点:
- 类似LLM的因果注意力机制,仅关注当前及之前帧
- 引入滑动窗口与KV缓存,保证推理速度恒定
- 生成器与判别器均采用因果结构
- 判别器并行处理所有帧,使用相对GAN损失与R1/R2正则化
自回归对抗后训练(AAPT)
该方法以预训练的双向视频扩散模型为基础,通过对抗训练将其转换为高效的自回归生成器。训练中引入了一系列支持长视频生成的技术,有效克服了数据与内存限制。
与其他方法对比
我们对Seaweed APT2与其他主流视频生成模型进行了横向比较,包括SkyReel-V2等基于扩散强制的方法。
- 扩散类模型在生成超过20秒视频时出现严重退化
- 调整CFG参数虽能缓解部分问题,但牺牲了画面结构一致性
- Seaweed APT2在长期稳定性与视觉质量上表现更优
挑战与局限性
尽管Seaweed APT2在多个方面取得了突破,但仍存在一些挑战:
- 快速运动建模困难:由于1NFE设计,模型在处理突发性复杂动作时受限
- 长距离记忆不足:滑动窗口机制导致远距离依赖难以维持
- 物理规律约束缺失:部分生成结果可能违反常识物理规则
- 未进行偏好对齐训练:如扩散模型中常见的偏好优化尚未实施
关键技术验证实验
输入回收的重要性
我们通过消融实验验证了“输入回收”机制对长时间生成的影响。当不回收历史帧作为后续输入时,模型无法维持大范围运动的一致性。
教师强制 vs 学生强制训练
在训练策略上,尝试了类似语言模型的教师强制方法,但发现其在推理阶段容易产生漂移。推测原因在于视频生成涉及连续值预测,误差累积更为敏感。
迈向无限长度生成
Seaweed APT2具备一定的零样本外推能力,可在未见过的长度范围内继续生成视频:
- 成功生成5分钟(7200帧)视频
- 仍受制于滑动窗口机制,可能出现主体遗忘或结构崩溃
我们认为这是构建无限长度流式生成系统的重要一步,未来将持续优化模型的记忆机制与结构稳定性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











