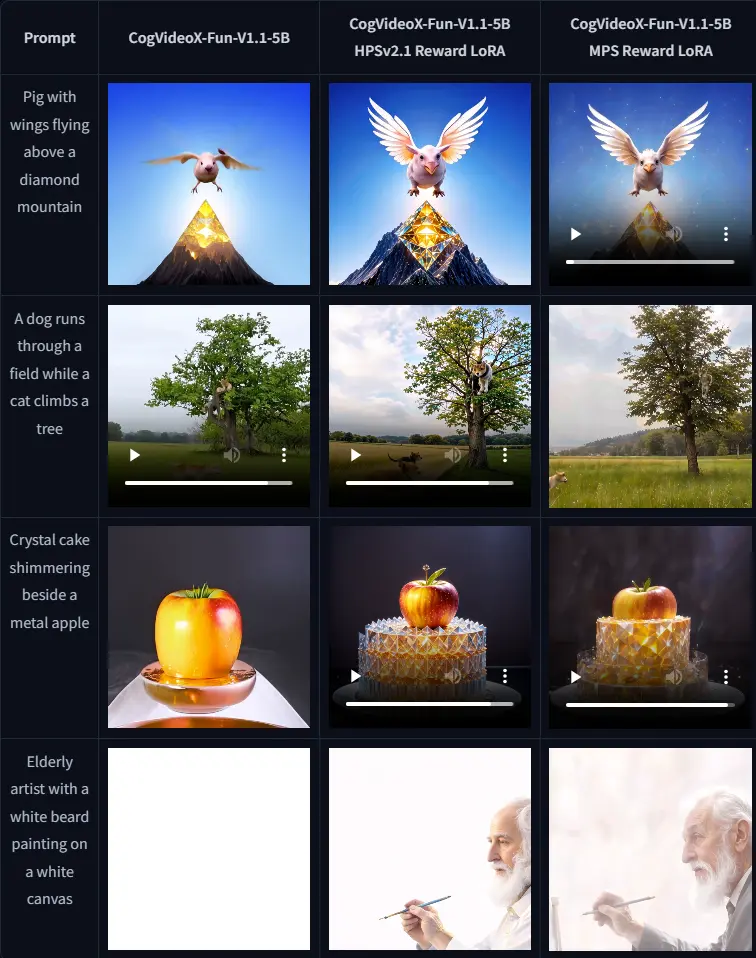
洛桑联邦理工学院(EPFL)的研究团队推出 Stable Video Infinity(SVI) ——一款能够生成任意长度视频的人工智能模型。它通过一项名为 “错误回收微调(Error-Recycling Fine-Tuning)” 的创新训练策略,有效解决了传统视频生成模型在长时间生成中普遍存在的错误累积、视觉漂移与语义退化问题。
- 项目主页:https://stable-video-infinity.github.io/homepage
- 模型:https://huggingface.co/vita-video-gen/svi-model
- GitHub:https://github.com/vita-epfl/Stable-Video-Infinity
- ComfyUI:https://huggingface.co/Kijai/WanVideo_comfy/tree/main/LoRAs/Stable-Video-Infinity
SVI 不仅能生成几十秒的短视频,还可稳定输出数分钟乃至10分钟以上的连贯视频(如社区展示的“汤姆和杰瑞”风格长片),同时保持高时间一致性与合理的场景过渡。

核心能力
1. 无限长度视频生成
- 突破传统模型(通常限于4–16秒)的时长瓶颈
- 视频长度仅受限于硬件和运行时间,无内在上限
- 支持流式生成,适用于长故事、动画剧集或监控模拟等场景
2. 可控的流式故事线
- 通过文本提示流(prompt stream) 动态引导内容演变
- 支持多场景切换(如“城市街道 → 咖啡馆 → 地铁”),实现逻辑连贯的叙事
- 可在生成过程中插入新的条件指令,实现交互式控制
3. 多模态条件输入
SVI 兼容多种控制信号,适用于多样化生成任务:
- 音频驱动:根据语音生成人物口型同步的说话视频
- 骨骼动作:输入动作序列(如舞蹈骨架),生成对应人体运动
- 文本 + 视觉条件:结合文本描述与初始帧/草图,引导生成方向
技术亮点
高时间一致性
- 长时间运行下,主体身份、背景结构、光照风格保持稳定
- 在 50 秒至 250 秒的测试中,主体一致性、背景一致性、成像质量等指标显著优于现有方法
错误自我纠正机制
- 传统方法试图“缓解”错误传播,而 SVI 主动学习如何从错误中恢复
- 通过“错误回收微调”,模型在训练中模拟真实推理时的错误轨迹,并学会纠正
数据高效 + 轻量微调
- 仅需 少量样本(如 1k 视频) 即可完成 LoRA(Low-Rank Adaptation)微调
- 无需从头训练大模型,普通开发者也可定制领域专属的 SVI(如卡通、医学动画等)
零额外推理成本
- 推理阶段不引入新模块或计算开销
- 生成速度与基础模型(如 Wan 2.1/2.2)完全一致,适合部署
工作原理:错误回收微调(Error-Recycling Fine-Tuning)
- 错误注入
在训练时,将模型先前生成的“错误帧”作为噪声注入到干净输入中,模拟长序列推理时的真实退化路径。 - 闭环错误收集
通过自回归生成构建“错误轨迹”,并将关键错误状态存储到回放记忆(replay memory) 中。 - 动态采样与重训
在后续训练中,从回放记忆中按时间步长采样错误样本,与原始数据混合训练,使模型学会在任意时间点恢复一致性。 - 多模态对齐
所有条件信号(文本、音频、骨骼)均通过统一嵌入空间对齐,确保跨模态控制的精确性与时序同步。
实测表现
- 长视频质量:在 50s / 250s 生成任务中,SVI 在人类评估和自动指标(如 FVD、CLIPSIM)上全面领先
- 多模态生成:
- 音频 → 说话人脸:口型同步自然,表情连贯
- 骨骼 → 舞蹈视频:动作流畅,肢体比例稳定
- 稳定性:随着视频长度增加,SVI 的质量衰减远低于基线模型
项目进展:SVI 2.0 Pro 与 Wan 2.2
2025年12月26日更新
- main 分支:基于 Wan 2.1 的 SVI(含 1.0 / 2.0)
- svi_wan22 分支:基于 Wan 2.2 的 SVI 2.0 / 2.0 Pro,性能进一步提升
社区驱动的工作流生态
众多用户已基于 SVI 2.0 Pro + lightx2v 少步蒸馏 LoRA 创建丰富 ComfyUI 工作流,涵盖:
- 多场景短片生成
- 卡通风格长动画
- 音频驱动对话视频
- 骨骼控制舞蹈合成
社区作品质量“远超我们预期”——官方团队诚邀用户在 GitHub 置顶议题中分享创作。
下一步:Wan 2.2 Animate SVI
团队发现,仅用 1k 样本微调 即可激活 Wan 2.2 Animate 的无限生成能力。初步结果已大幅超越早期基于 UniAnimate-DiT 的 SVI-Dance,正在扩大训练规模。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...