视频人脸超分辨率(VFSR)的目标是从低分辨率(LR)或严重退化的视频中重建出高分辨率(HR)的人脸图像。尽管人脸图像超分辨率(FSR)领域已经取得了显著进展,但视频人脸超分辨率仍然是一个相对较少被研究的领域。现有的方法要么将通用视频超分辨率网络应用于人脸数据集,要么独立处理每个视频帧。然而,这些方法在重建人脸细节和保持时间一致性方面面临挑战。例如,独立处理每个帧的方法可能会导致视频中人脸的细节不一致,而通用视频超分辨率网络可能无法准确重建人脸的细节。
- 相关主页:https://jnjaby.github.io/projects/KEEP
- GitHub:https://github.com/jnjaby/KEEP
- Demo:https://huggingface.co/spaces/rcfeng/KEEP
南洋理工大学的研究人员推出视频人脸超分辨率的新型框架KEEP,解决视频中人脸图像的超分辨率问题,同时保持时间一致性。

主要功能
- 人脸细节重建:能够从严重退化的视频中重建出高分辨率的人脸细节,例如眼睛、鼻子和嘴巴等面部特征。
- 时间一致性:通过保持稳定的面部先验信息,确保视频中人脸在时间上的连贯性,避免出现闪烁或细节突变。
- 鲁棒性:对非正面人脸和严重退化的视频表现出色,能够稳定地估计人脸先验信息。
主要特点
- 基于卡尔曼滤波的特征传播:利用卡尔曼滤波原理,将之前恢复的帧作为参考,指导当前帧的恢复过程,从而保持时间一致性。
- 稳定的人脸先验信息:通过在潜空间中传播信息,确保人脸先验信息的稳定性,从而在视频帧之间保持一致的外观。
- 可扩展性:虽然以CodeFormer为例进行了实现,但该框架的原理适用于其他基于图像的人脸超分辨率方法。
工作原理
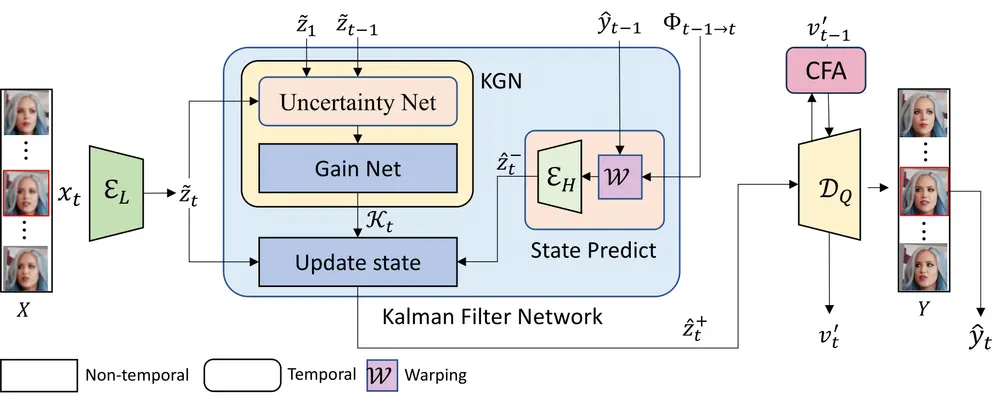
- 状态空间模型:将低质量视频序列和高质量视频序列分别建模为观测值和状态变量,通过非线性动态模型和观测模型来描述它们之间的关系。
- 卡尔曼滤波网络(KFN):通过预测和更新步骤,结合之前恢复的帧信息和当前帧的观测信息,计算出更准确的当前帧状态估计值。该网络包括不确定性网络和增益网络,用于估计卡尔曼增益。
- 跨帧注意力(CFA):在解码器中采用跨帧注意力模块,进一步促进局部时间一致性,通过匹配和融合前一帧的相似特征来增强当前帧的细节。
测试结果
- 定量评估:在VFHQ数据集上,与现有的图像和视频超分辨率方法相比,KEEP在PSNR、SSIM、LPIPS等指标上均取得了更好的结果。例如,在VFHQ-mild数据集上,KEEP的PSNR达到了27.9994 dB,SSIM为0.8267,LPIPS为0.1619。
- 时间一致性:通过σIDS(身份相似度的标准差)和σAKD(关键点距离的标准差)评估时间一致性,KEEP在这两个指标上表现优异,表明其在视频中保持了稳定的身份和姿势。
- 定性评估:在视觉上,KEEP能够恢复出更自然、更一致的人脸细节,避免了其他方法可能出现的闪烁和细节突变问题。
应用场景
- 老电影修复:可以用于修复老电影中的人脸图像,使其在保持原始风格的同时,提升分辨率和视觉质量。
- 监控视频增强:在监控视频中,可以提高人脸的清晰度,有助于身份识别和安全监控。
- 视频会议:提升视频会议中人脸图像的质量,改善用户体验。
- 社交媒体视频:增强社交媒体平台上的用户上传视频中的人脸细节,提升视觉效果。
总之,KEEP通过创新的卡尔曼滤波特征传播机制,为视频人脸超分辨率领域提供了一种有效的解决方案,能够在保持时间一致性的同时,显著提升人脸细节的重建质量。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...