字节跳动于4月份正式开源了其统一视频生成框架 Phantom,这是一个专注于“主体一致性(Subject-to-Video, S2V)”的视频生成框架。它能够从参考图像中提取关键主体元素,并结合文本描述,生成符合预期、视觉一致的高质量视频。

什么是 Phantom?
Phantom 是一个跨模态对齐驱动的视频生成框架,核心目标是确保视频中的主体(如人物、动物或物体)在生成过程中保持与输入图像和文本的高度一致。
它不仅支持单个主体的视频生成,还支持多主体交互场景,适用于数字人、虚拟试穿、AI短片创作等多种应用场景。
核心功能亮点
✅ 主体一致性视频生成(S2V)
- 单主体生成:输入一张人物/物体图片 + 文本指令(如“她在跳舞”),即可生成对应动作的视频。
- 多主体生成:输入多张图片 + 描述(如“一个人和一只狗在公园玩耍”),可生成互动式视频。
✅ 面部 ID 保持
在生成人物视频时,Phantom 能够有效保留原始面部特征,避免身份漂移问题,特别适合需要高度真实感的数字人应用。
模型演进与现状
字节跳动自今年4月起已陆续发布多个 Phantom 模型:
| 模型名称 | 参数量 | 发布时间 | 特点 |
|---|---|---|---|
| Phantom-Wan-1.3B | 1.3B | 2024年4月21日 | 小型模型,适合本地运行,但效果一般 |
| Phantom-Wan-14B | 14B | 2025年5月27日 | 大型模型,生成质量高,需高性能 GPU 支持 |
据官方透露,未来还将推出:
- Phantom-Wan-14B Pro
- 相关训练数据集
- 完整训练代码
此外,开发者 kijai的ComfyUI插件ComfyUI-WanVideoWrapper早在4月就已经支持此模型,并发布了量化版本模型,进一步降低了本地部署门槛。
- 模型:https://huggingface.co/bytedance-research/Phantom
- GitHub:https://github.com/kijai/ComfyUI-WanVideoWrapper
- 量化版模型:https://huggingface.co/Kijai/WanVideo_comfy/tree/main
- 量化版:https://www.modelscope.cn/models/Kijai/WanVideo_comfy/files(国内用户请从此下载)
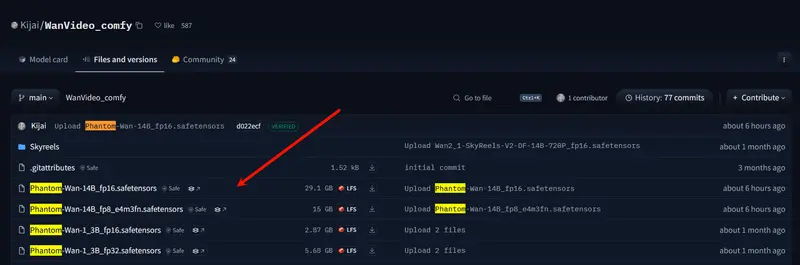
如何使用 Phantom-Wan系列模型?
- 安装所需插件,如ComfyUI-WanVideoWrapper
- 将提供的工作流文件拖入 ComfyUI 界面,从GitHub上下载或者从ComfyUI-WanVideoWrapper
/example_workflows文件夹
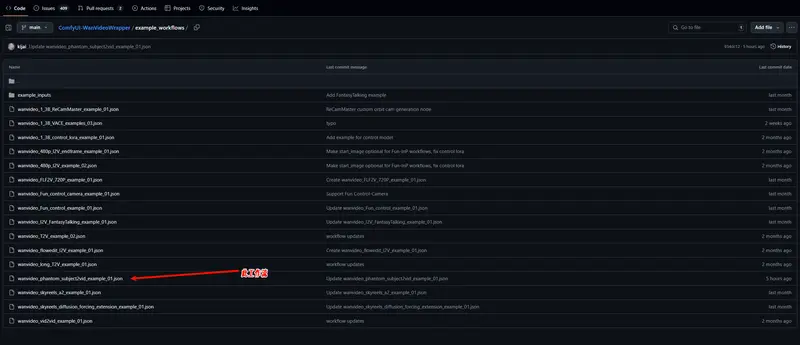
- 下载对应的 Phantom 模型(WAN-1.3B 或 WAN-14B)
- 加载参考图像 + 输入文本指令,开始生成视频
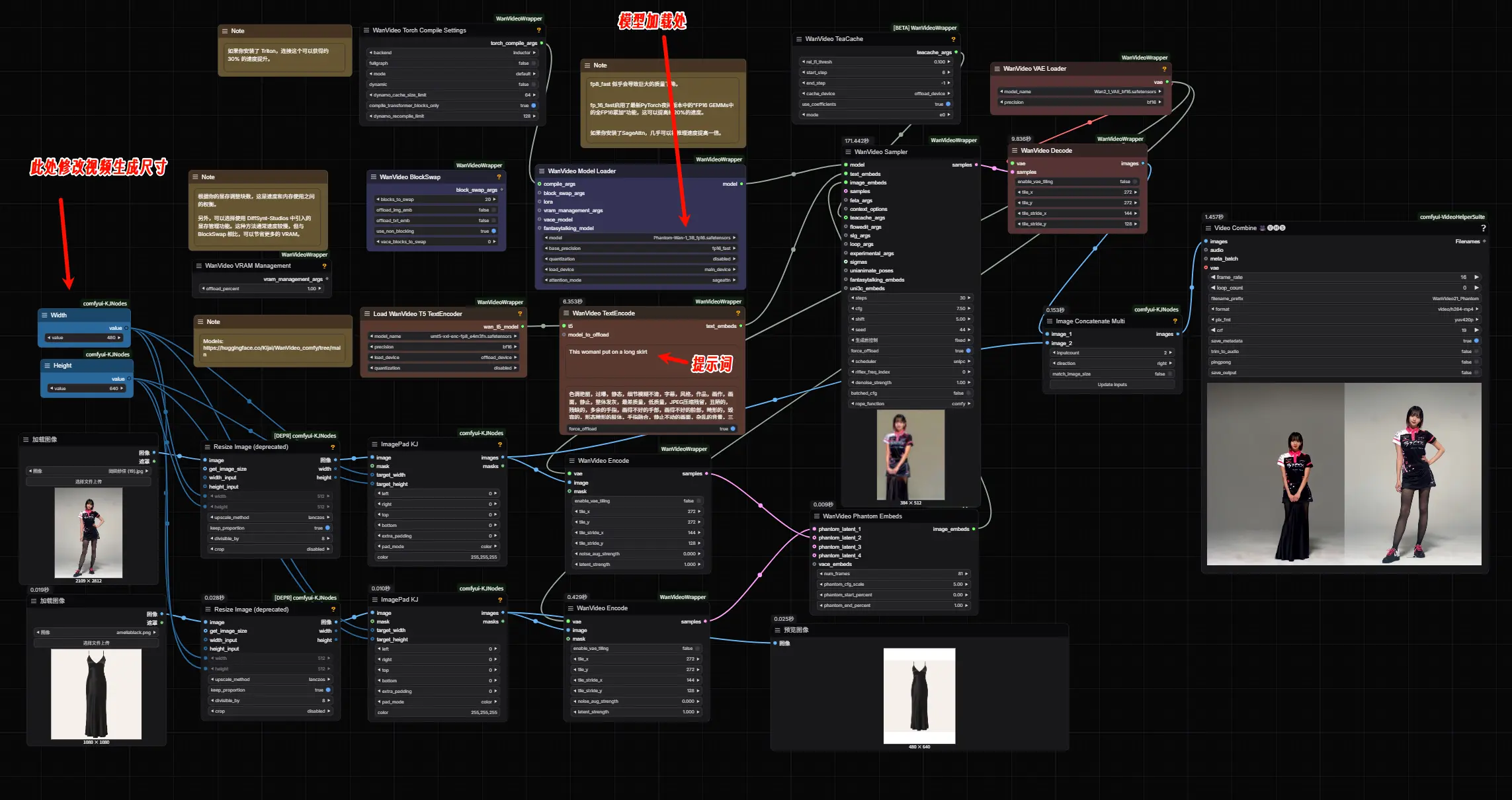
⚠️ 注意:Phantom-Wan-14B 体积较大,生成过程耗时较长,推荐在云端平台运行以提升效率。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...