
在内容创作、虚拟社交等场景中,“基于单张图像生成个性化视频”是重要需求——比如用一张自拍生成动态表情视频,或让历史人物照片“动起来”讲述故事。但这类任务长期面临核心挑战:如何在保证视频自然流畅的同时,精准保留人物身份特征。
传统方法要么难以还原面部细节(生成视频与原图差异大),要么需要大规模微调基础模型(计算成本高)。为此,字节跳动提出了Lynx模型,基于开源扩散变换器(DiT)基础模型,通过两个轻量级适配器的创新设计,仅用单张输入图像就能生成“身份高度保真、动作自然连贯、场景符合提示”的个性化视频,大幅降低了高保真个性化视频生成的技术门槛。

Lynx的核心突破:解决“身份保真”与“生成质量”的平衡难题
个性化视频生成的核心矛盾在于:既要让生成的人物“像原图”(身份保真),又要让视频“动得自然、场景对味”(生成质量)。传统方法往往顾此失彼,而Lynx通过针对性设计实现了双向优化。
1. 传统方法的三大局限
- 身份失真:生成视频中的人物面部特征(如眉形、脸型)与输入图像偏差大,甚至出现“换脸”效果;
- 细节丢失:皮肤纹理、妆容等细粒度特征在动态生成中模糊或消失;
- 成本高昂:为保留身份特征,需对基础模型进行大规模微调,消耗大量计算资源。
2. Lynx的针对性解决方案
Lynx的创新在于不重构基础模型,仅通过两个轻量级适配器“嫁接”功能,在保证生成质量的同时,实现高效身份保留:
| 核心需求 | 技术方案 | 具体效果 |
|---|---|---|
| 精准保留身份 | ID适配器(ID-adapter) | 提取输入图像的核心身份特征,转化为紧凑令牌全程指导生成,确保脸型、五官等关键特征一致 |
| 还原细粒度细节 | Ref适配器(Ref-adapter) | 注入输入图像的VAE密集特征,保留皮肤纹理、发丝等细微特征,避免动态生成中的细节模糊 |
| 保证视频自然性 | 基于DiT的时序建模+渐进式训练 | 生成视频的动作连贯、光照一致,符合物理规律和场景逻辑 |
技术拆解:两个适配器如何让单图“动起来”且“不变样”
Lynx基于开源的Diffusion Transformer(DiT)基础模型构建,核心创新在于ID适配器和Ref适配器的设计,两者分工协作,共同实现高保真个性化生成。
1. ID适配器:抓住“身份核心特征”,全程锚定人物
ID适配器的作用是“从单张图像中提取身份标识,并让生成过程始终围绕该标识”,具体流程:
- 首先用成熟的人脸识别模型ArcFace,从输入图像中提取面部嵌入向量(一串数字,浓缩了该人物的核心身份特征,如脸型、眼距、眉形等);
- 再通过Perceiver Resampler将高维嵌入向量转换为紧凑的身份令牌(更适合扩散模型处理的格式);
- 在视频生成的每一步,这些身份令牌通过交叉注意力机制,强制模型生成的面部特征与输入图像保持一致——比如输入图像是“高鼻梁”,令牌就会约束生成视频中所有帧的鼻梁特征不能偏离。
这种设计的优势在于:仅用少量参数(轻量级)就实现了身份的强约束,无需修改基础模型结构。
2. Ref适配器:注入“细粒度细节”,还原纹理质感
如果说ID适配器负责“大方向不错”,Ref适配器则负责“细节不丢”:
- 先将输入图像送入预训练的VAE(变分自编码器)编码器,提取密集视觉特征(包含皮肤纹理、毛孔、妆容、发丝等细微信息);
- 这些特征通过跨注意力机制,被注入到DiT模型的所有Transformer层中——意味着从视频生成的“草图阶段”到“精细渲染阶段”,细粒度细节都能得到保留;
- 例如输入图像中人物有“左脸颊的痣”,Ref适配器会确保生成视频的所有帧中,这个痣的位置、形状都与原图一致,不会在动态中消失或移位。
3. 训练策略:分阶段学习,兼顾“静态特征”与“动态规律”
Lynx采用“图像预训练→视频训练”的两阶段策略,让模型逐步掌握个性化视频生成的核心能力:
- 图像预训练阶段:用大规模人脸图像数据训练适配器,让模型先学会“从单张图像精准提取身份和细节特征”,确保静态生成时的高保真度;
- 视频训练阶段:引入视频数据(包含不同动作、光照、场景),训练模型学习“如何让人物自然运动”——比如头部转动时的面部透视变化、说话时的嘴部动作规律,同时通过约束机制保证运动中身份特征不漂移。
此外,训练中采用“空间-时间帧打包”设计,让模型能同时处理不同分辨率(如512×512、256×256)和不同时长(如4秒、8秒)的视频数据,增强模型的适应性。
实测性能:身份相似度与生成质量双领先
研究团队构建了包含40个主体、20个无偏提示的测试基准(共800个测试案例),从“身份保真度”“提示遵循性”“视频质量”三个维度评估Lynx的表现,结果全面优于现有方法。
1. 身份相似度:显著优于对比方法,核心特征高度一致
在三个权威面部识别模型(facexlib、insightface、字节内部模型)上,Lynx生成视频的平均相似度得分分别为0.779、0.699、0.781,较次优方法分别高出9.2%、7.5%、8.3%。直观来看,即使视频中人物做出转头、微笑等动作,其脸型、眉形、眼部特征等仍与输入图像高度吻合,未出现传统方法中常见的“越动越不像”问题。
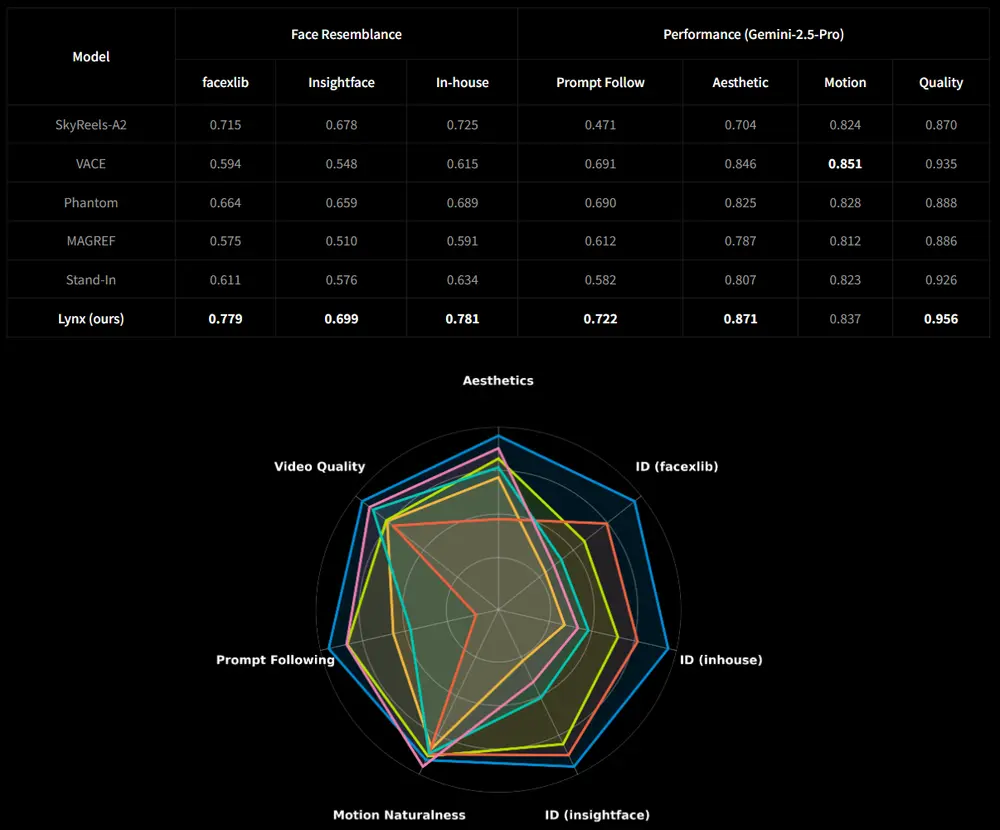
2. 生成质量:兼顾语义准确与视觉自然
在人工评估中(1-5分制),Lynx在四个关键维度中的三项排名第一:
- 提示遵循性(视频内容与文本描述的匹配度):4.21分,能准确生成“戴眼镜”“微笑”“转头”等提示动作;
- 美学质量(画面清晰度、色彩自然度):4.15分,皮肤纹理、光影过渡等细节处理细腻;
- 整体视频质量:4.23分,综合表现最优;
- 运动自然性:4.08分,虽略低于某专项优化模型,但仍处于领先水平,动作流畅无卡顿。
应用场景与技术价值
Lynx的轻量级设计和高保真特性,使其在多个场景中具有实用价值:
- 内容创作工具:帮助普通用户快速生成个性化动态内容,如用自拍生成表情包、虚拟形象短视频,无需专业剪辑技能;
- 虚拟社交:在元宇宙、虚拟偶像等场景中,让用户基于单张照片创建“数字分身”,支持实时动态互动;
- 影视后期辅助:为历史影像修复、人物重现提供技术支持,比如让老照片中的人物“动起来”讲述故事,同时保持原貌;
- 低成本个性化生成:相比需要大规模微调的方案,Lynx的轻量级适配器设计大幅降低了计算成本,更易在消费级设备上部署。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











