阿里通义实验室Wan项目组正式推出 Wan2.5-Preview——一个在架构层面实现革新、真正实现“音视频协同生成”的新一代视觉大模型。
它不是简单的功能叠加,而是通过原生多模态统一架构,将文本、图像、音频和视频深度融合,首次实现从“先做画面再配声”到“音画共生”的跨越。
这一升级,标志着 AIGC 从“视觉生成”迈向“视听创作”的关键一步。
核心定位:不止于“出图”,更要“成片”
Wan2.5-Preview 的目标是服务真实的内容生产场景:
- 制作带配音的短视频广告
- 快速生成电商产品宣传片
- 构建虚拟偶像表演片段
- 输出可读性强的设计海报与数据图表
为此,它全面重构了底层架构,并在视频生成、图像生成与图像编辑三大核心能力上实现跃升。
架构创新:真正的原生多模态
✅ 原生多模态统一框架
不同于传统“文本→图像”或“文本→视频”的单向流程,Wan2.5-Preview 采用全新设计的统一架构,同时支持理解与生成任务,并灵活处理以下输入/输出组合:
| 输入 | 输出 |
|---|---|
| 文本 + 图像 | 视频 |
| 音频 + 提示词 | 动态画面 |
| 视频片段 + 指令 | 编辑后视频 |
所有模态在同一系统中流转,无需外部拼接或后期合成。
✅ 联合多模态训练
通过大规模联合训练文本、音频与视觉数据,模型实现了更强的跨模态对齐能力,确保:
- 人物口型与语音节奏一致
- 背景音乐情绪匹配画面氛围
- 音效出现时机精准对应动作
这是实现高质量音视频同步的基础。
✅ 人类偏好对齐(RLHF)
引入基于人类反馈的强化学习(RLHF),持续优化生成结果的审美质量、动态自然度与指令遵循能力,使输出更贴近专业创作者的标准。
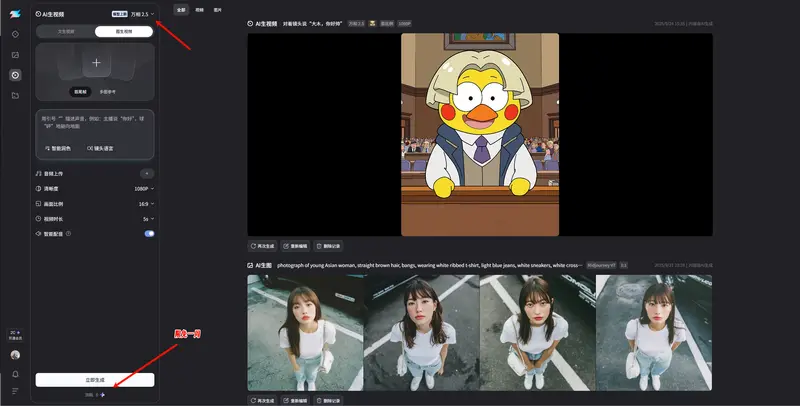
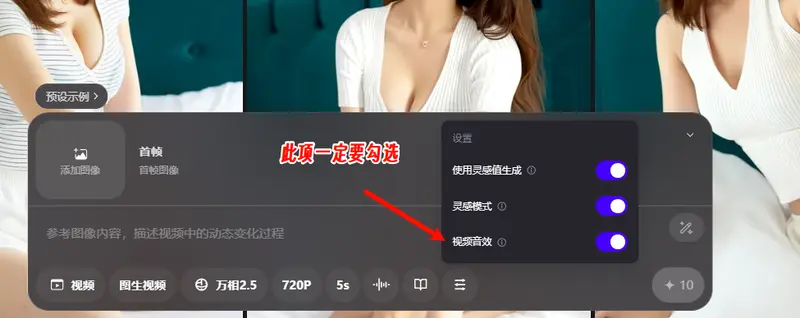
视频生成:会“配音”的 10 秒电影工厂
Wan2.5-Preview 是目前少数能原生生成同步音频的视频模型之一,支持:
- 多人对话人声(含中文、英文、小语种及方言)
- ASMR、环境音效、背景音乐
- 画面与声音毫秒级对齐
关键能力提升:
| 特性 | 表现 |
|---|---|
| 视频时长 | 最高支持 10 秒(较前代翻倍) |
| 分辨率 | 支持 1080p@24fps,画质清晰稳定 |
| 动态表现 | 运镜流畅,结构稳定性显著增强 |
| 叙事能力 | 支持连续情节推进,如“开门→走进房间→坐下” |
创意控制方式多样:
- 文生视频:输入详细提示词,生成完整音画内容
- 图生视频:上传首帧图 + 提示词,延续风格生成动态
- 音频驱动:上传自定义语音或音乐,让模型根据音频节奏生成匹配画面 —— 实现“用我的声音讲你的故事”
💡 应用场景:品牌广告、短剧试镜、虚拟主播内容生成等
图像生成:能“写字”的设计专家
除了写实与艺术风格生成,Wan2.5-Preview 在文字渲染与结构化内容生成方面取得重大突破。
核心能力:
- 稳定文字生成
支持中英文、小语种、艺术字体、长段落排版,可在复杂构图中精准呈现文案,适用于海报、LOGO、封面设计。 - 图表直接输出
可生成科学图表、流程图、数据可视化图、系统架构图、带文字说明的表格等,满足企业文档、教学材料、报告制作需求。 - 美学质感升级
光影真实、材质细腻,在摄影级写实、插画、水彩、矢量等多种风格间自由切换。 - 复杂指令理解
支持逻辑推理类提示,例如:“左边是穿红衣服的孩子在放风筝,右边是同一孩子长大后的模样,站在城市街头”。
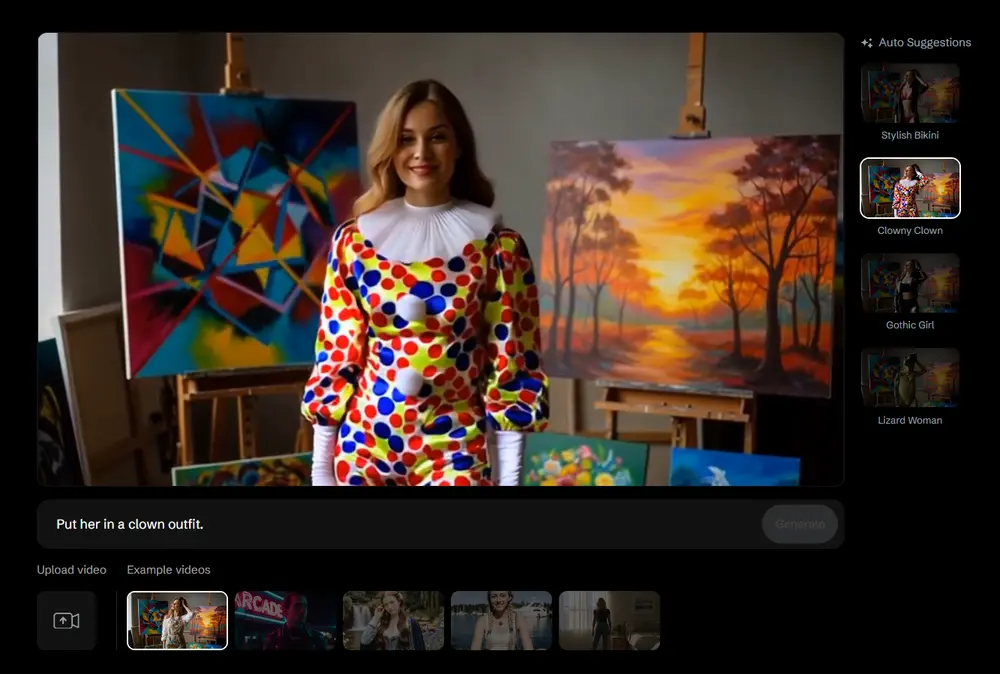
图像编辑:工业级“改字不崩脸”
传统 AI 编辑常面临“换背景就变形、加文字就崩脸”的问题。Wan2.5-Preview 引入更精细的 ID 保持机制,实现高保真图像编辑。
支持的编辑任务包括:
- 更换背景 / 替换颜色 / 添加元素
- 材质转换(如皮革变金属)
- 风格迁移(照片转油画)
- 商品外观定制(不同配色方案预览)
独特优势:
- ✅ 指令驱动:无需 PS 技能,用自然语言即可完成编辑
- ✅ ID 强保持:人脸、商品、品牌标识等关键元素一致性极高
- ✅ 多图参考编辑:可提供多个参考图作为风格或结构引导
示例:上传一张模特图 + 指令“换成沙漠背景,穿着蓝色连衣裙,保持人物不变”,输出结果中人物身份特征高度保留。
如何体验?
Wan2.5-Preview 已上线 通义万相官网、造点AI等,支持以下功能:
- 文生视频(带音频)
- 图生视频(保 ID)
- 文生图(含文字与图表)
- 对话式图像编辑
开发者也可通过 API 接入,集成至自有工作流。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











