
在影视翻译、虚拟人互动和短视频创作中,音频驱动的视觉配音(Visual Dubbing)技术至关重要。然而,传统方法长期受困于一个核心难题:缺乏完美的成对训练数据(即除了嘴型不同,其他完全一致的视频)。
为了解决这个问题,现有主流方案大多采用“面具式修复”:先遮住人物的嘴巴,再根据新语音重新画一张嘴。这种做法虽然规避了数据难题,却带来了严重的副作用:身份失真(脸变得不像本人)、画面瑕疵(口罩边缘有痕迹)、动作泄露(脸颊跟着嘴巴乱动)。
- 项目主页:https://hjrphoebus.github.io/X-Dub
- GitHub:https://github.com/KlingAIResearch/X-Dub
- 模型:https://huggingface.co/KlingTeam/X-Dub
由 清华大学、快手可灵团队、北京航空航天大学、香港科技大学和香港中文大学 联合推出的 X-Dub 正式开源。它提出了一种革命性的 “无掩膜(Mask-Free) 框架,彻底抛弃了遮挡策略,直接利用生成式引导解锁了鲁棒的视觉配音能力,让 AI 配音首次实现了“只动嘴,不动脸”的完美效果。
核心突破:从“修补”到“编辑”
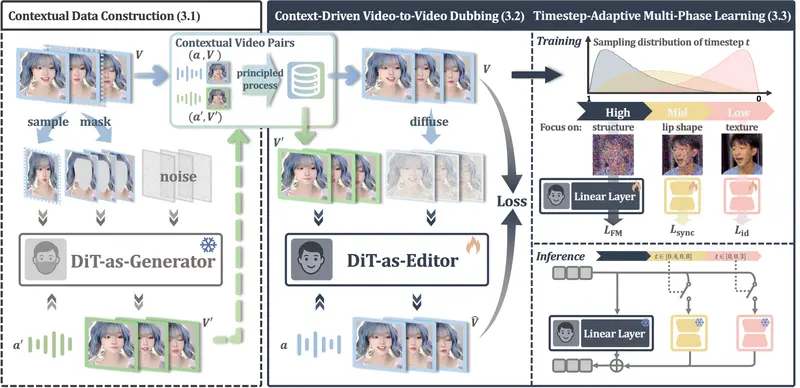
X-Dub 的核心创新在于不再把配音看作“局部修复”任务,而是“全局编辑”任务。
1. 无掩膜编辑 (Mask-Free Editing)
- 传统痛点:掩码会切断时空上下文,导致模型不知道嘴巴周围的脸该怎么长,只能靠猜,结果就是“换嘴不换脸”或边缘模糊。
- X-Dub 方案:直接输入完整视频,让模型自主学会定位并仅修改嘴唇区域。由于保留了完整的时空上下文,人物身份、面部纹理、光影关系被完美保留,彻底消除了“面具感”。
2. 生成式引导策略 (Generative Guidance)
既然没有真实的“完美成对数据”,X-Dub 就自己造数据!
- 第一步(造教材):训练一个高质量的掩码模型作为“数据生成器”。它负责生成大量“伪成对数据”(原视频 vs 重绘嘴型的视频)。
- 第二步(练神功):用这些高质量的伪数据,训练最终的无掩膜模型。模型通过学习“如何把重绘过的嘴还原回原样”,反向掌握了“如何根据新语音精准修改嘴型”的能力。
- 结果:既利用了掩码模型的数据生成能力,又规避了其推理时的画质缺陷。
3. 时序自适应多阶段学习
为了平衡“改嘴型”、“保身份”和“稳画面”这三个冲突目标,X-Dub 采用了精妙的三阶段训练策略:
- 高噪声阶段:聚焦全局结构,确保头部姿态、背景布局不跑偏。
- 中噪声阶段:专注唇部动作,结合语音同步损失,精准匹配发音口型。
- 低噪声阶段:打磨细节纹理,通过身份损失函数,确保五官特征毫厘不差。
主要功能与特点
| 特性 | 传统掩码方案 | **X-Dub **(无掩膜) |
|---|---|---|
| 处理方式 | 遮挡嘴部 -> 重绘 | 直接编辑全图,无需遮挡 |
| 身份一致性 | ❌ 易失真,像换了一个人 | ✅ 完美保留,本人无疑 |
| 画面瑕疵 | ❌ 边缘有痕,易闪烁 | ✅ 自然连贯,无 artifacts |
| 复杂场景 | ❌ 遮挡/侧脸易失效 | ✅ 鲁棒性极强 (成功率 96.4%) |
| 适用范围 | 主要是真人正脸 | 真人 + 动漫 + 动物 + 非人类 |
核心能力全景
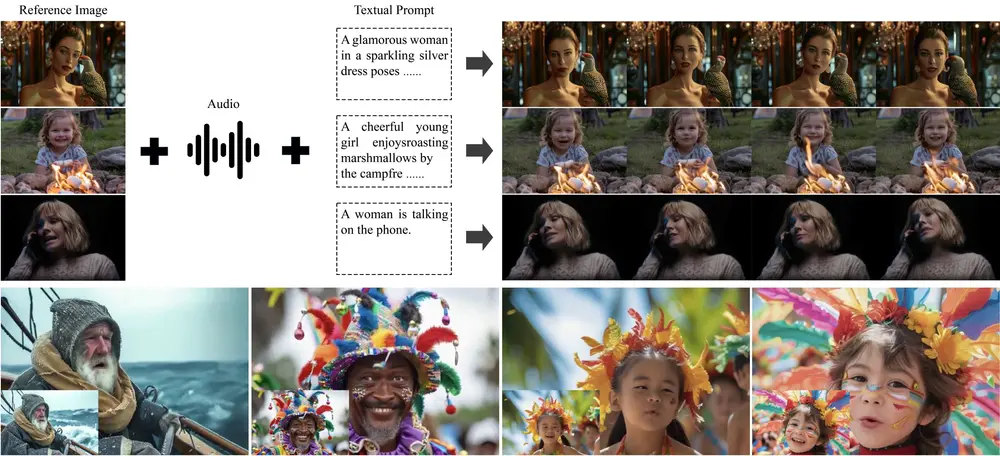
- 🎯 精准唇同步:无论是快速对话、唱歌还是多语言切换,嘴型都能严丝合缝。
- 🛡️ 身份与场景锁定:戴眼镜、手挡嘴、大幅转头、光线变化?统统不影响,背景和人设稳如泰山。
- 🌍 多语言支持:完美适配 英语、普通话、粤语、日语、俄语、法语 六种语言。
- 🎨 跨次元通用:不仅适用于真人,对卡通角色、动画人物甚至动物也有极佳的泛化能力。
实测表现:全面碾压 SOTA
在 HDTF 标准数据集和全新的 X-DubBench 复杂基准测试中,X-Dub 展现了统治级性能:
- 指标领先:在 HDTF 上,唇同步得分提升 4.9%,身份相似度提升 4.3%。在更难的 X-DubBench 上,唇同步得分暴涨 16.0%。
- 鲁棒性爆表:在包含遮挡、极端姿态的复杂场景中,成功率高达 96.4%,比最强传统方法高出 24 个百分点。
- 用户首选:在 30 人盲测中,X-Dub 在真实感、同步度、一致性上均获 **满分评价 **(4.66/5.0),远超竞品。
开源版本说明 (Public Release)
由于公司政策,研究团队无法开源论文中使用的内部私有模型。本次发布的是基于 Wan2.2-TI2V-5B 骨干网络的公开版 X-Dub。
- 实现方式:采用 **多阶段 SFT **(Supervised Fine-Tuning) 替代了原论文的 LoRA 调优,以达到类似效果。
- 性能表现:
- ✅ 优势:泛化能力更强(尤其对动漫/动物),唇同步效果令人满意,与内部版本高度一致。
- ⚠️ 已知差异:相比内部版本,公开版在时间稳定性(偶有闪烁)、主体一致性(偶有颜色/身份漂移)和推理速度(慢约 2 倍)上略有妥协,且极少数情况下可能出现噪帧。
- 适用性:尽管有小瑕疵,但公开版已足以满足绝大多数高质量配音需求,且无需任何掩码操作,使用体验极佳。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











