韩国科学技术院(KAIST)MAC 实验室与梨花女子大学 MMAI 实验室的研究人员共同提出了一项新任务:基于文本条件的选择性视频到音频生成(Text-Conditioned Selective Video-to-Audio Generation),并推出了名为 SelVA 的模型。
- 项目主页:https://jnwnlee.github.io/selva-demo
- GitHub:https://github.com/jnwnlee/selva
- 模型:https://huggingface.co/jnwnlee/SelVA
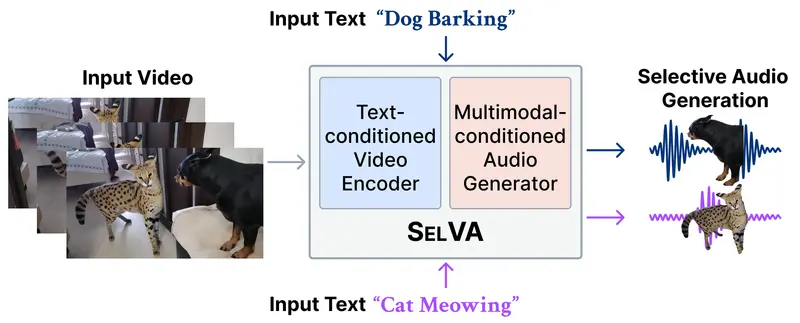
传统的视频转音频模型通常会生成视频中所有可见声源的混合声音,无法区分特定对象。而 SelVA 允许用户通过文本提示作为“选择器”,仅从包含多个对象的复杂视频中,提取并生成与指令相匹配的特定声音,忽略其他无关噪音。这一能力对于需要独立音轨进行后期混音、编辑的多媒体制作至关重要。
核心突破:从“全量生成”到“按需提取”
1. 文本即选择器 (Text as Selector)
- 传统局限:现有模型(如 Foleycrafter, Diff-Foley)倾向于生成画面中所有潜在声源的混合音。若视频中有狗叫、车流和人声,输出往往是三者的嘈杂混合。
- SelVA 方案:将文本提示(如“狗叫声”)视为显式过滤器。模型利用交叉注意力机制,从视频编码特征中精准提取与文本语义相关的视觉特征,仅合成目标声音。
2. 抑制无关激活 (Suppressing Irrelevant Activations)
为了不让模型“分心”,SelVA 引入了补充令牌(Complementary Tokens)。
- 这些令牌在微调过程中协助交叉注意力模块,主动抑制与文本指令无关的视觉特征激活。
- 结果是模型能更稳健地进行语义定位(找到发声物体)和时间定位(确定发声时刻),即使背景中有其他干扰声源。
3. 自监督混合训练 (Self-Supervised Mixing)
针对缺乏“单声源纯净视频 - 音频”对的问题,研究团队设计了一种自主视频混合方案:
- 通过将多个单源视频在视觉上混合,构建出多声源的训练数据。
- 利用自监督学习,让模型学会从混合画面中分离出对应单一文本指令的声音,有效克服了数据稀缺的限制。
技术架构与工作流程
SelVA 的工作流程可以概括为“看视频 → 听指令 → 选声音”:
- 视频编码:使用预训练的视频编码器提取时空特征。
- 文本引导选择:
- 输入文本提示(如 "car engine")。
- 通过交叉注意力机制,结合补充令牌,筛选出与 "car engine" 相关的视觉特征,屏蔽其他(如行人、鸟叫)特征。
- 音频生成:基于筛选后的特征,通过扩散模型生成高保真、时间同步的音频波形。
| 组件 | 功能描述 |
|---|---|
| 视频编码器 | 提取包含多对象动作的视觉特征 |
| 文本选择器 | 利用文本提示作为查询向量,定位目标声源 |
| 补充令牌 | 辅助抑制非目标特征的激活,提升信噪比 |
| 扩散生成器 | 根据筛选特征合成最终音频 |
性能表现:VGG-MonoAudio 基准测试
研究团队构建了 VGG-MonoAudio,一个专门用于评估选择性配音任务的干净单源视频基准数据集。实验结果显示:
- 全面领先:在音频质量(FAD, KL Div)、语义对齐(CLAP Score)和时间同步(KLD, LSE)三项核心指标上,SelVA 均优于现有最先进模型。
- 人类偏好:在盲测中,用户普遍认为 SelVA 生成的声音更清晰、指令匹配度更高,且无背景杂音干扰。
- 复杂场景鲁棒性:即使在多声源混杂(如同时有猫叫和狗叫)的场景下,SelVA 也能准确区分并只生成指定动物的叫声,极少出现“串音”现象。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...