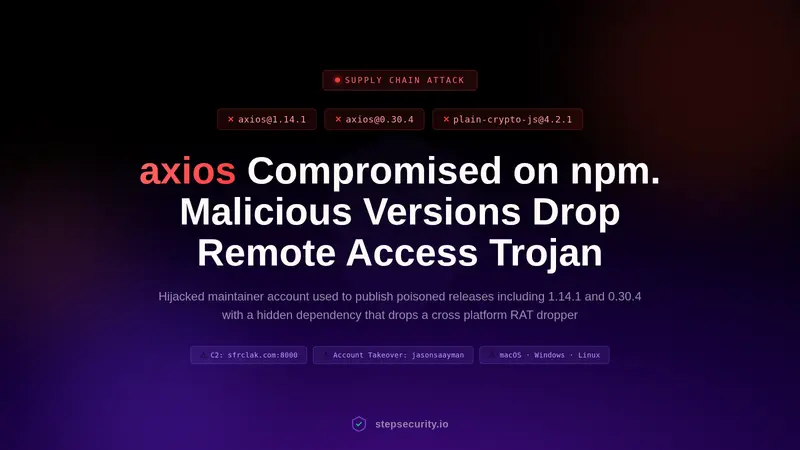
开发者 Jackrong 正式发布了 Qwopus3.5-27B-v3,这是一款基于 Qwen3.5-27B 深度优化的推理增强模型。与前代及市面上大多数追求“长思维链”的模型不同,Qwopus-v3 提出了一项颠覆性的范式转变:从“行动前过度思考”转向“先行动后优化”。
- 模型:https://huggingface.co/collections/Jackrong/qwopus35-v3
该模型专为 OpenClaw 等智能体(Agent)系统设计,在 HumanEval 基准测试中以 95.73% 的严格通过率刷新了 27B 参数级模型的纪录,证明了在序列决策任务中,基于反馈的试错迭代比纯粹的内心推演更为高效。
核心理念:范式转变
❌ 传统误区:行动前过度思考 (Over-thinking before Acting)
当前的语言智能体往往被鼓励在采取行动前进行冗长的思维链(CoT)推理和自反思。然而,新证据表明,这种“纸上谈兵”式的深思熟虑对于复杂的序列决策并非最优解,甚至可能导致分析瘫痪或脱离实际环境。
✅ Qwopus-v3 方案:先行动后优化 (Act First, Optimize Later)
受 Reflexion 和 失败后反思 + 重试 研究的启发,Qwopus-v3 倡导一种执行驱动的优化循环:
- 轻量级初始推理:快速形成初步计划。
- 尽早执行行动:在环境中尝试操作(如编写代码、调用工具)。
- 基于反馈修正:根据执行结果(报错、输出不符)进行针对性的反思和重试。
数据支撑:研究表明,将反思从“行动前”移至“行动后”,可使数学推理任务性能提升 34.7%,函数调用任务提升 18.1%。
技术突破:从“蒸馏模仿”到“结构对齐”
Qwopus-v3 不仅改变了推理策略,更在训练方法论上进行了彻底革新,解决了 v2 版本存在的根本性问题。
🚧 v2 的困境:蒸馏的幻觉
v2 模型主要通过 SFT 蒸馏自 Claude 等强模型的 CoT 数据。研究发现:
- 轨迹伪造:部分教师模型的 CoT 轨迹可能是事后生成的“合理化解释”,而非真实的推理过程。
- 表面模仿:学生模型学到了表面的文本模式,却未掌握底层的逻辑推导能力,导致在分布外(OOD)任务上鲁棒性差。
✅ v3 的革新:结构推理优化
Qwopus-v3 摒弃了盲目的模仿,转而追求过程级的忠实推理:
- 可验证的推理链:使用经过整理、逻辑严密的真实推理数据进行训练。
- 显式中间步骤:强制模型生成清晰、逐步的中间状态,而非压缩的结论。
- 结构对齐:优化推理的基本结构,使其更短、更稳定,同时保持高准确率。
- 代价:生成的 CoT 长度略高于 v2,但换来了更高的可解释性和可靠性。
🛠️ 工具调用强化
针对智能体场景,模型接受了专门的强化学习(RL)训练:
- 优化了连续任务执行中的稳定性。
- 提升了工具调用的熟练度与准确率,完美适配 OpenClaw 等框架。
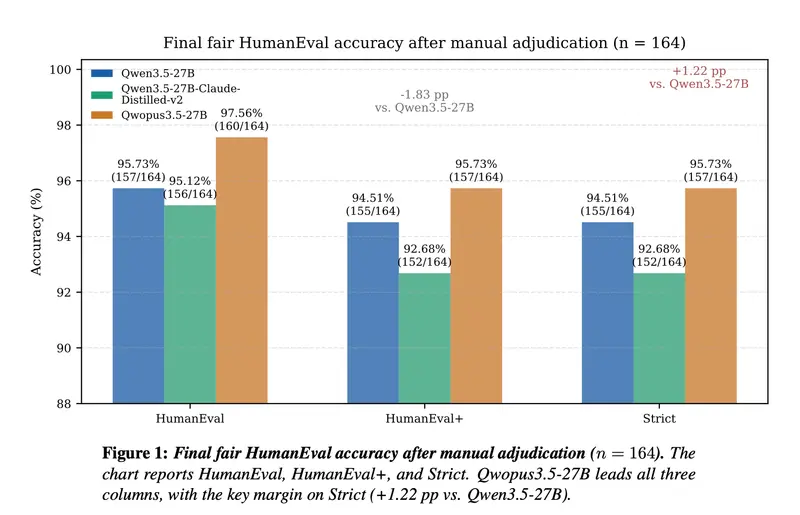
性能实测:HumanEval SOTA
在严格的 HumanEval (164 任务) 基准测试中,Qwopus3.5-27B-v3 展现了统治级实力。测试采用保守的手动判定协议,排除了代码提取污染和格式噪音干扰。
| 模型 | Base Pass (一次通过) | Plus Pass (严格总分) | 对比基线 (Qwen3.5-27B) |
|---|---|---|---|
| 🥇 Qwopus3.5-27B-v3 | 97.56% (160/164) | 95.73% (157/164) | 📈 +1.22 pp |
| Qwen3.5-27B (基线) | 95.73% (157/164) | 94.51% (155/164) | — |
| Claude-Distilled-v2 | 95.12% (156/164) | 92.68% (152/164) | 📉 -1.83 pp |
- 评测环境:Unsloth 运行时,bfloat16 精度。
- 验证方式:由 GPT-4.5-Pro 和 Claude Opus 4.6 交叉验证答案正确性。
- 结论:Qwopus-v3 不仅在绝对分数上领先,还显著减少了需要手动修正的错误次数,展现了更强的泛化能力。
适用场景
Qwopus3.5-27B-v3 是为下一代 AI 智能体 而生的模型:
- 🤖 自主编程代理:在复杂的多步代码生成与调试任务中,能快速试错并自我修正。
- 🔌 工具增强型系统:适用于 OpenClaw、LangChain 等需要频繁调用外部 API 和工具的框架。
- 🧩 复杂逻辑推理:在数学解题、逻辑规划等需要高鲁棒性的场景中表现优异。
- 🔄 交互式工作流:适合需要与环境持续交互、根据反馈动态调整策略的任务。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...