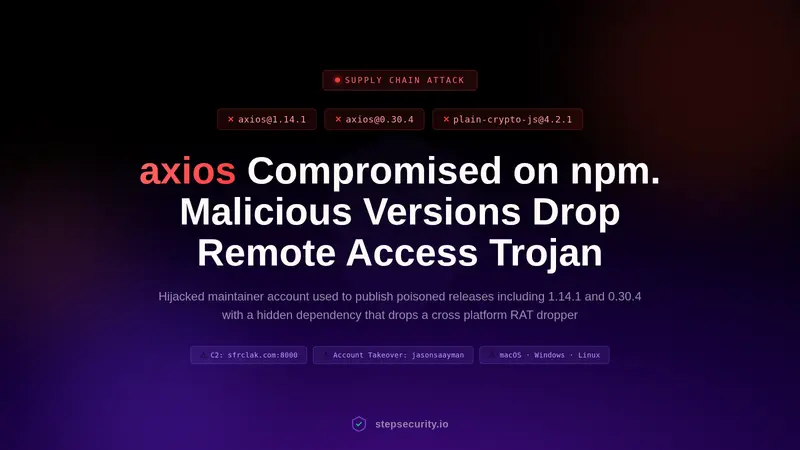
京东推出 JoyMed,这是一款具有里程碑意义的医疗多模态基础模型。与当前主流医疗 AI 要么“盲目推理”浪费算力,要么“缺乏思考”导致误诊不同,JoyMed 首创了 自适应推理机制(Adaptive Reasoning)。它能像资深医生一样,根据病例的复杂程度智能决定是“直觉判断”还是“深度分析”,在确保诊断准确率和可解释性的同时,实现了计算效率的最优平衡。
- GitHub:https://github.com/jdh-algo/JoyMed
- JoyMed-32B-v1.0:https://huggingface.co/jdh-algo/JoyMed-32B-v1.0
- JoyMed-8B-v1.0:https://huggingface.co/jdh-algo/JoyMed-8B-v1.0
实验数据显示,JoyMed 在医学文本问答、视觉问答、文档理解及报告生成等四大核心领域的多个权威基准测试中,全面超越 GPT-4.1、GPT-5 以及 Doubao Seed 1.6 等专有模型,确立了开源医疗模型的新标杆。
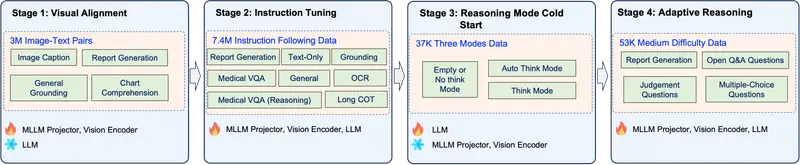
核心突破:自适应推理机制
JoyMed 解决了医疗 AI 领域长期存在的“准确性 vs. 效率”悖论:
- 传统痛点:
- 强制推理:无论问题多简单(如“发烧吃什么药”),模型都生成冗长的思维链,浪费算力且响应慢。
- 无推理:面对复杂病例(如罕见病鉴别诊断),模型直接输出结论,缺乏逻辑支撑,易产生幻觉且不可信。
- JoyMed 解决方案:
- 动态模式切换:模型内置三种运行模式——直接输出(简单任务)、思维链推理(复杂任务)和 自适应思考(自动判断)。
- 智能资源分配:通过难度分级数据集训练,模型能自主评估问题复杂度。简单问题秒回,复杂问题则生成详细的逐步推理轨迹,确保诊断严谨、可解释。
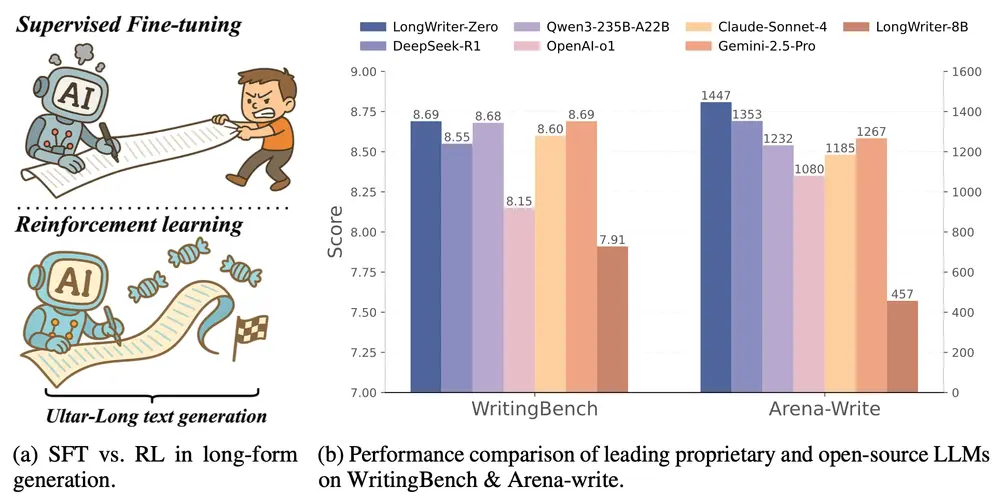
性能表现:全方位 SOTA (State-of-the-Art)
JoyMed 提供 8B 和 32B 两个版本,均在多项测试中刷新纪录,甚至在部分指标上超越了参数量大得多的竞品。
1. 医学文本问答 (Medical Text QA)
在涵盖 PubMedQA, MedMCQA, MedQA (USMLE) 等 9 个基准的综合测试中:
- JoyMed-32B (Thinking 模式):平均准确率高达 73.86%,超越 GPT-5 (71.27%) 和 Doubao Seed 1.6 (75.06% - 注:Doubao 在部分单项领先,但 JoyMed 综合均衡性更强,且在 MedXQA 上以 31.31% 远超 GPT-5 的 40.75% 之外的所有开源模型,并在 CMMLU 上达到 89.27%)。
- 更正数据解读:在 MedXQA 上,JoyMed-32B 达到 32.65% (Auto 31.35%, Thinking 31.31%),虽略低于 GPT-5 的 40.75%,但在 CMMLU (中文医学知识) 上以 89.27% 碾压 GPT-5 (82.93%) 和 Doubao (91.67% - Doubao 在此项极高)。
- 关键胜利:在 MedQA (MCMLE) 台湾医师考试中,JoyMed-32B 取得 94.31% 的惊人成绩,并列第一,超越 GPT-4.1 (81.73%)。
- 小模型奇迹:JoyMed-8B 平均得分 67.00%,已接近或超越许多 30B+ 的开源模型。
2. 医学视觉问答 (Medical VQA)
在 VQA-RAD, SLAKE, PATH-VQA 等 7 个视觉基准中:
- JoyMed-33B (Auto 模式):平均准确率 75.01%,位居开源模型之首。
- 单点突破:在 VQA-RAD (放射科问答) 上达到 89.14%,在 SLAKE 上达到 94.70%,在 PATH-VQA (病理学) 上达到 92.19%,大幅领先 GPT-4.1 (平均 55.12%) 和 GPT-5 (49.73%)。这表明 JoyMed 在医学图像理解上具有极强的专业性。
3. 医学文档理解 (Document Understanding)
针对复杂的实验室检测报告和临床文档:
- JoyMed-32B (Thinking 模式):平均得分 94.51%,在简单 QA 任务中达到 87.40%,展现了极强的信息提取和逻辑解析能力。
- 对比优势:在
fullparsing任务中,JoyMed-8B 达到 93.39%,优于 GPT-5 (71.41%),证明其在结构化数据提取上的巨大优势。
4. 医学报告生成 (Report Generation)
在 CheXpert Plus 和 IU XRAY 胸部 X 光报告生成任务中:
- JoyMed-8B:在 CheXpert Plus 的 ROUGE-L 指标上达到 32.54,显著高于 GPT-4.1 (24.50)。
- JoyMed-32B (Thinking):在 IU XRAY 的 RaTE 指标上达到 66.19,刷新最佳记录,生成的报告更符合医生书写规范。
模型规格与训练策略
| 特性 | 描述 |
|---|---|
| 模型版本 | JoyMed-8B-v1.0 (轻量高效), JoyMed-32B-v1.0 (极致性能) |
| 两阶段训练 | 1. 细粒度视觉 - 语言对齐:强化对病变、解剖结构的感知。 2. 复杂任务强化:在报告生成、病例分析上建立精确关联。 |
| 自适应机制 | 基于难度分级数据集训练,防止模式崩溃,实现自主决策。 |
| 开源协议 | 模型权重已在 Hugging Face 公开,推动医疗 AI 普惠化。 |
应用场景与价值
- 临床辅助诊断 (CDSS):
- 对于常见症状,快速给出建议,减少医生等待时间。
- 对于疑难杂症,提供详细的鉴别诊断推理过程,辅助医生决策,降低误诊率。
- 自动化病历与报告生成:
- 自动读取检查影像和检验单,生成符合规范的初版报告,医生只需审核修改,大幅提升工作效率。
- 医学教育与科研:
- 作为教学工具,展示复杂病例的分析思路;作为科研助手,从海量文献和病历中提取关键信息。
- 基层医疗赋能:
- 让基层医生拥有“专家级”的 AI 助手,提升偏远地区的医疗服务水平。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...