今日,谷歌正式推出全新开放模型Gemma 4,并称其为“迄今为止最智能的开放模型”。该模型专为高级推理和智能体工作流打造,核心亮点在于实现了前所未有的单位参数智能水平,既能在自有硬件上高效运行,又能通过宽松的开源许可证,为全球开发者提供无门槛的创新支持。
- 模型:https://huggingface.co/collections/google/gemma-4
- Demo:https://aistudio.google.com/prompts/new_chat?model=gemma-4-31b-it
- 官方介绍:https://blog.google/innovation-and-ai/technology/developers-tools/gemma-4
- Ollama:https://ollama.com/library/gemma4
- LM Studio:https://lmstudio.ai/models/gemma-4

Gemma系列模型的发展势头十分强劲,自第一代发布以来,开发者下载量已突破4亿次,衍生出超过10万个变体,形成了一个充满活力的“Gemma宇宙”。谷歌表示,团队认真倾听了开发者在突破AI边界过程中对模型能力的需求,而Gemma 4正是基于这些需求打造的突破性成果,全程在Apache 2.0许可下开放,兼顾能力与灵活性。
值得注意的是,Gemma 4与谷歌专有模型Gemini 3源于同一套一流的研究和技术,二者形成互补,为开发者提供了业界最强大的“开放+专有”双工具组合——既可以借助Gemma 4的开放性自由定制,也能依托Gemini 3的专有优势实现更复杂的场景落地。
核心亮点:业界领先的能力,兼顾移动与高性能
Gemma 4并非单一模型,而是包含四个不同尺寸的多功能模型系列,分别是有效2B(E2B)、有效4B(E4B)、26B混合专家(MoE)和31B稠密模型。与传统开放模型不同,整个系列不仅能满足基础聊天需求,更擅长处理复杂逻辑推理和智能体工作流,在性能上实现了重大突破。
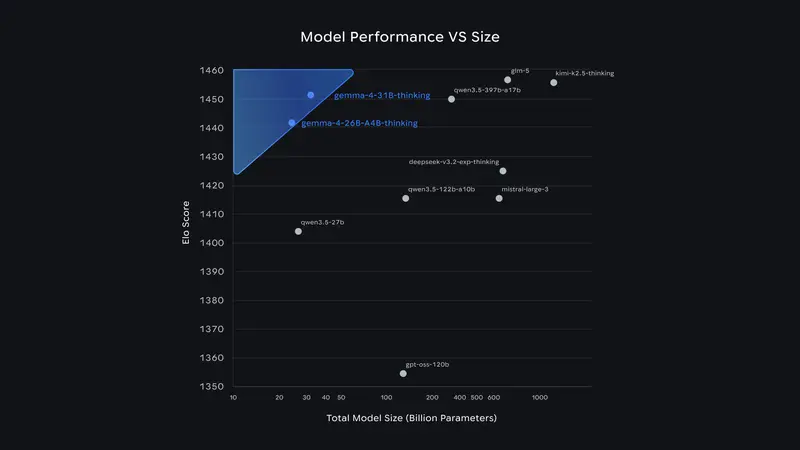
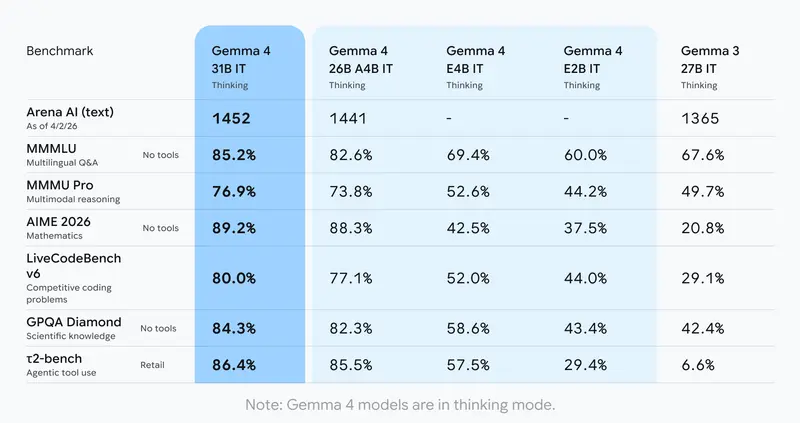
在大型模型领域,Gemma 4的表现尤为突出:31B稠密模型目前在行业标准Arena AI文本排行榜上,位列全球开放模型第3名;26B混合专家模型稳居第6名,其性能甚至优于比自身参数大20倍的其他开放模型。对于开发者而言,这种高单位参数智能意味着,无需投入高额硬件成本,就能实现前沿AI能力。
而在边缘端,E2B和E4B模型则重新定义了设备端AI的实用性——谷歌并未盲目追求参数数量,而是优先优化多模态能力、低延迟处理和生态集成,让AI能力能够轻松落地到各类小型设备上,打破了“高性能AI只能依赖大型服务器”的局限。
关键特性:强大、易用、开放,覆盖多场景需求
Gemma 4之所以能成为谷歌迄今为止能力最强的开放模型系列,核心在于其全面且实用的特性,能够满足从基础开发到前沿研究的各类需求,具体包括:
- 高级推理能力:具备多步规划和深度逻辑分析能力,在数学计算、指令遵循等需要复杂推理的基准测试中,表现较上一代有显著提升,能够轻松应对需要层层拆解的复杂任务。
- 原生支持智能体工作流:内置函数调用、结构化JSON输出和原生系统指令功能,开发者可以直接基于此构建自主智能体,实现与各类工具、API的交互,可靠执行复杂工作流。
- 高质量代码生成:支持离线代码生成,能够将普通工作站转变为本地优先的AI代码助手,帮助开发者提升编码效率,减少重复工作量。
- 全场景多模态支持:所有模型均原生支持视频、图像处理,适配可变分辨率,在OCR识别、图表理解等视觉任务上表现出色;此外,E2B和E4B模型还具备原生音频输入功能,可用于语音识别和语音理解。
- 超长上下文窗口:边缘端模型(E2B、E4B)拥有128K上下文窗口,大型模型(26B、31B)则支持高达256K上下文窗口,能够一次性处理代码仓库、长文档等大体积内容,无需分段解析。
- 多语言原生支持:基于超过140种语言进行原生训练,能够帮助开发者构建面向全球用户的应用程序,兼顾包容性和高性能。
多硬件适配:从手机到服务器,全场景离线运行
Gemma 4的一大核心优势的是硬件适配的广泛性,谷歌针对不同硬件和用例,对模型权重进行了量身优化,确保开发者能在需要的地方,获得前沿推理能力,具体分为两大类别:
1. 26B和31B模型:面向PC与专业开发场景
这两款大型模型主打前沿智能,可完全离线运行于个人电脑,专为研究人员和专业开发者设计。其中,未量化的bfloat16权重可高效适配单个80GB NVIDIA H100 GPU;量化版本则能原生运行于消费级GPU,完美支撑IDE编码、智能体工作流等本地开发场景。
两者分工明确:26B混合专家(MoE)模型专注低延迟,推理期间仅激活总参数中的38亿,能提供极快的每秒令牌生成速度;31B稠密模型则最大化原始性能,为模型微调提供了强大的基础,适合对精度要求较高的研究和生产场景。
2. E2B和E4B模型:面向移动与物联网设备
这两款模型从头开始设计,核心目标是最大化计算和内存效率,推理期间仅激活有效20亿和40亿参数,能有效节省设备内存和电池消耗。通过与谷歌Pixel团队、高通、联发科等移动硬件厂商的深度合作,这两款多模态模型可在手机、树莓派、NVIDIA Jetson Orin Nano等边缘设备上完全离线运行,且延迟几乎为零。
对于Android开发者而言,目前可在AICore开发者预览版中原型设计智能体流程,实现与Gemini Nano 4的前向兼容性,为后续Android端AI应用开发铺垫基础。
开源许可:Apache 2.0加持,自由部署无门槛
谷歌表示,团队充分听取了开发者的反馈,认为AI的未来需要协作,因此Gemma 4采用了商业许可宽松的Apache 2.0开源许可证。这一许可证为开发者提供了完全的灵活性和数字主权,让开发者能够完全控制自己的数据、基础设施和模型。
开发者可自由基于Gemma 4构建应用,安全部署到任何环境——无论是本地设备、私有服务器,还是云端平台,都无需担心限制性障碍,极大降低了创新门槛。
安全与生态:信任为基,多工具多平台支持
在安全方面,Gemma 4经历了与谷歌专有模型(如Gemini 3)同样严格的基础设施安全协议,能够满足企业和主权组织对安全、可靠性的最高标准,成为值得信赖的AI开发基石。
为了让开发者快速上手,谷歌为Gemma 4构建了完善的生态系统,提供了多渠道、多工具支持,具体包括:
- 快速实验:可在Google AI Studio(支持31B、26B MoE模型)或Google AI Edge Gallery(支持E4B、E2B模型)中立即探索;Android开发者可在Android Studio中驱动Agent Mode,通过ML Kit GenAI Prompt API构建生产级应用。
- 多工具兼容:首日支持Hugging Face系列工具、LiteRT-LM、vLLM、llama.cpp、Ollama、NVIDIA NIM等主流开发工具,开发者可自由选择适配自身项目的工具链。
- 便捷下载:可从Hugging Face、Kaggle、Ollama等平台直接获取模型权重,无需复杂流程。
- 灵活定制:可通过Google Colab、Vertex AI,甚至普通游戏GPU,对模型进行训练和微调,适配自身特定需求。
- 云端扩展:如需大规模生产部署,可借助Google Cloud的Vertex AI、Cloud Run、TPU加速服务等,突破本地硬件限制,同时满足受监管工作负载的合规要求。
- 多硬件加速:开箱即适配NVIDIA、AMD、谷歌TPU等行业领先硬件,从边缘设备到大型服务器,均可实现高性能运行。
- 生态共建:可加入Kaggle上的Gemma 4 Good Challenge,参与构建具有积极社会影响力的AI产品,推动AI技术正向应用。
总体而言,Gemma 4的发布,不仅填补了谷歌在高端开放模型领域的进一步空白,更通过广泛的硬件适配、宽松的开源许可和完善的生态支持,为开发者提供了更灵活、更强大的AI工具。无论是专业研究人员、企业开发者,还是入门级开发者,都能借助Gemma 4,在自有硬件上实现前沿AI能力,推动AI创新落地到更多场景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...