Ollama已完成适配,第一时间上线对谷歌全新开放模型Gemma 4的支持,开发者可快速在本地部署使用该系列模型

Gemma 4由Google DeepMind打造,全系列模型在对应参数规模下均可实现前沿性能表现,适配复杂推理、智能体工作流、代码编写以及多模态理解等多元应用场景。该系列模型具备原生多模态能力,可同时处理文本与图像输入,并输出文本内容。
- 地址:https://ollama.com/library/gemma4
依托全新的能力升级与架构优化,Gemma 4实现了多项核心突破:
- 推理能力:全系列模型均具备高阶推理能力,搭载可自定义配置的思考模式
- 拓展多模态:全系支持文本、图像处理,兼容可变宽高比与分辨率
- 高效多元架构:推出稠密模型与混合专家(MoE)不同规格变体,满足差异化部署需求
- 端侧优化:轻量型号专为笔记本、移动设备的本地高效运行设计
- 超大上下文窗口:轻量模型搭载128K上下文窗口,中型模型支持256K上下文
- 强化编码与智能体能力:编码基准测试表现大幅提升,原生支持函数调用,赋能自主智能体
- 原生系统提示支持:新增对
system角色的原生支持,可实现结构化、可控的对话交互
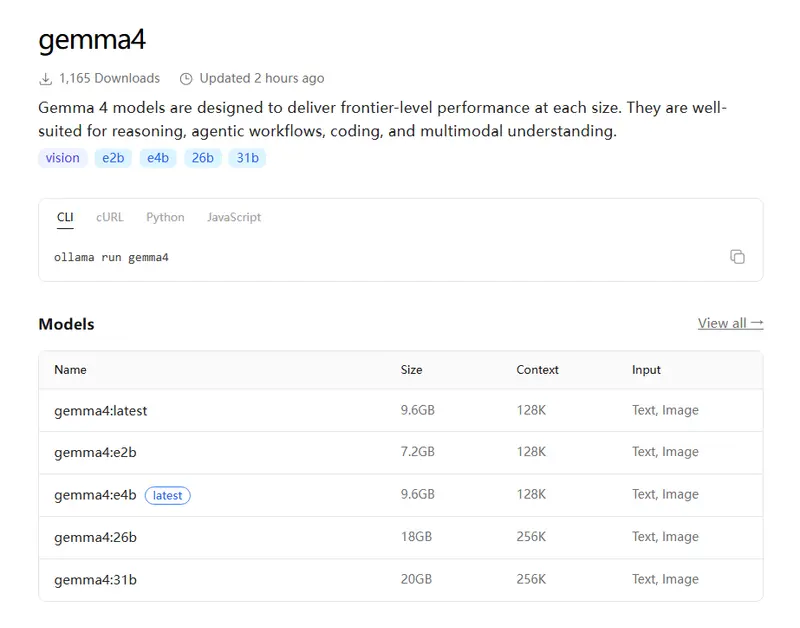
模型分类与Ollama部署指令
边缘模型
型号中字母E代表有效(effective) 参数,专为边缘设备部署场景研发
- Effective 2B (E2B)
ollama run gemma4:e2b
- Effective 4B (E4B)
ollama run gemma4:e4b
工作站模型
该类模型面向本地高阶智能计算场景设计
- 26B(混合专家模型,推理激活4B参数)
ollama run gemma4:26b
- 31B(稠密模型)
ollama run gemma4:31b
最佳使用实践
为保障Gemma 4在Ollama中发挥最优性能,可遵循以下配置规范:
1. 采样参数配置
全场景推荐使用标准化采样参数:
temperature=1.0top_p=0.95top_k=64
2. 思考模式配置
Ollama已自动适配聊天模板逻辑,Gemma 4采用标准system、assistant、user角色体系,可通过专属标记控制思考模式:
- 启用思考:在系统提示开头添加
<|think|>标记,移除即可关闭思考功能 - 标准生成:开启思考后,模型会先输出内部推理内容,再给出最终答案,格式为
<|channel>thought\n[内部推理]<channel|> - 关闭思考:除E2B、E4B外的模型,关闭思考后会生成空思考块,格式为
<|channel>thought\n<channel|>[最终答案]
3. 多轮对话规范
多轮对话交互中,历史记录仅保留模型最终响应内容,无需添加模型的思考推理内容
4. 多模态输入顺序
进行多模态任务时,需将图像、音频内容放置在提示文本之前,保障运行效果
5. 可变图像分辨率配置
Gemma 4支持通过视觉令牌预算调整图像分辨率,令牌预算决定图像表征的计算消耗,可选数值为70、140、280、560、1120
- 分类、字幕生成、视频理解:选用低令牌预算,兼顾推理速度与多帧处理能力
- OCR、文档解析、小字识别:选用高令牌预算,保留视觉细节
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...