今年,随着Stability AI经历了一系列动荡,包括多位主要开发者离职及创始人退出,开源社区对其推出的Stable Diffusion 3 Medium模型也表示不满。在此背景下,Stable Diffusion的主要作者之一Robin Rombach与其他几位离职成员共同创立了新公司——黑森林实验室(Black Forest Labs)。这家初创企业已经完成了3100万美元的种子轮Series Seed融资,并推出了备受瞩目的Flux.1系列文生图模型。

黑森林实验室简介
黑森林实验室的核心成员包括前Stability AI研究科学家Robin Rombach,他在Stability AI任职期间是Stable Diffusion模型的主要开发者之一,并参与了SDXL、SVD等多个项目的研发。除了Rombach之外,团队还包括Andreas Blattmann、Axel Sauer、Dominik Lorenz、Dustin Podel、Frederic Boesel、Patrick Esser、Sumith Kulal、Tim Dockhorn、Yam Levi和Zion English等多位原Stability AI成员。
团队的创新成果包括VQGAN和Latent Diffusion的创造,以及一系列Stable Diffusion模型(包括Stable Diffusion XL、Stable Video Diffusion、Rectified Flow Transformers)的研发,还有用于超快速实时图像合成的Adversarial Diffusion Distillation技术。(官方介绍)
资金
黑森林实验室已成功完成3100万美元的种子轮Series Seed融资。本轮融资由主要投资者Andreessen Horowitz领投,包括著名天使投资人Brendan Iribe、Michael Ovitz、Garry Tan、Timo Aila和Vladlen Koltun等在内的专家也参与了此次投资。此外,General Catalyst和MätchVC也为黑森林实验室提供了后续投资,支持其实现将欧洲最先进的AI技术带给全球用户的愿景。顾问委员会包括内容创作行业的资深人士Michael Ovitz和神经风格转换领域的先驱Matthias Bethge教授。
Flux.1模型系列
黑森林实验室推出了Flux.1系列文生图模型,该系列模型在图像细节、提示遵循、风格多样性和场景复杂性方面定义了新的最高标准。为了平衡可访问性和模型能力,Flux.1提供三个版本:
- FLUX.1 [pro]:提供最先进的图像生成性能,顶级的提示遵循、视觉质量、图像细节和输出多样性。通过API注册获取FLUX.1 [pro]访问权限。也可通过Replicate和fal.ai使用。此外,还提供专门定制的企业解决方案——通过flux@blackforestlabs.ai联系。
- FLUX.1 [dev]:这是一个开放权重、指导蒸馏的模型,适用于非商业应用。直接从FLUX.1 [pro]蒸馏而来,FLUX.1 [dev]获得了类似的品质和提示遵循能力,比同规模的标准模型更高效。FLUX.1 [dev]权重可在HuggingFace上获得,并可以直接在Replicate或Fal.ai上试用。对于商业用途,请通过flux@blackforestlabs.ai联系。
- FLUX.1 [schnell]:这是黑森林实验室最快的模型,专为本地开发和个人使用定制。FLUX.1 [schnell]在Apache2.0许可下公开可用。类似FLUX.1 [dev],模型可在Hugging Face上获得,推理代码可在GitHub和HuggingFace的Diffusers中找到。目前已经在ComfyUI上集成。
如何使用FLUX.1
1、通过Replicate和fal.ai使用
Replicate:
- https://replicate.com/collections/flux
- https://replicate.com/black-forest-labs/flux-pro
- https://replicate.com/black-forest-labs/flux-dev
- https://replicate.com/black-forest-labs/flux-schnell
FAL:
- https://fal.ai/models/fal-ai/flux-pro
- https://fal.ai/models/fal-ai/flux/dev
- https://fal.ai/models/fal-ai/flux/schnell
2、通过API使用
- API地址:https://docs.bfl.ml
3、模型下载及Demo使用
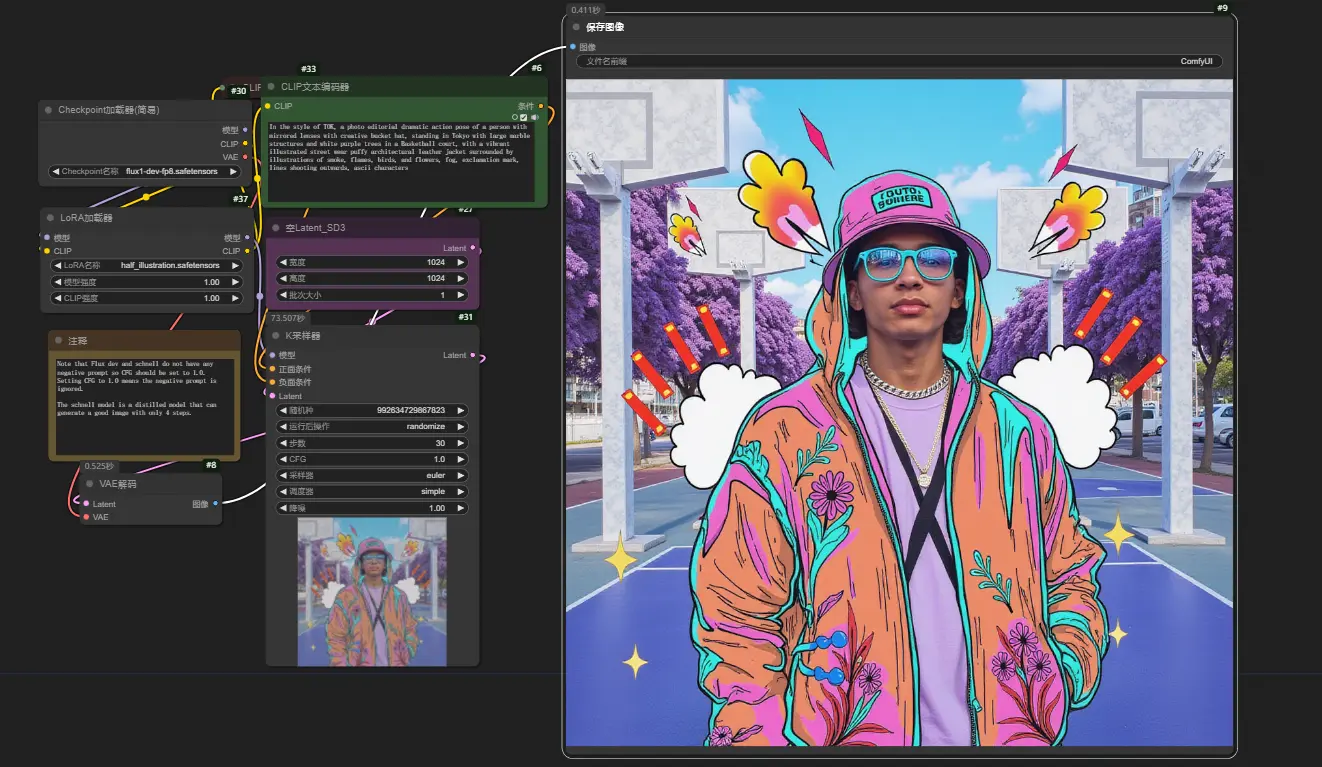
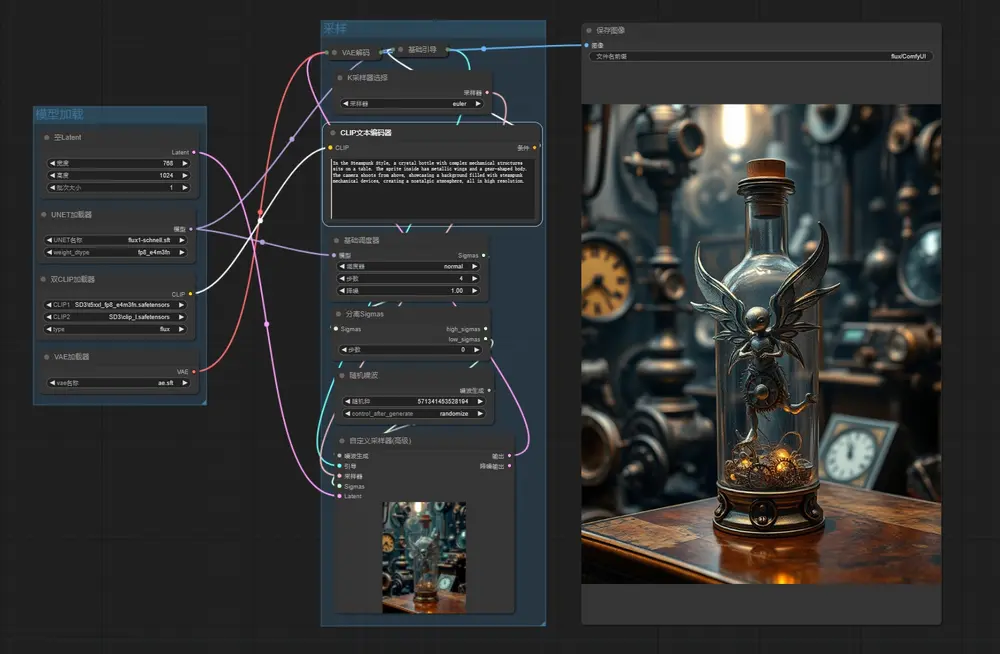
4、通过ComfyUI使用
需要将ComfyUI升级到最新版,然后在下面的地址下载工作流,拖入ComfyUI即可使用。
Transformer驱动的Flow模型规模化
所有Flux.1模型均基于多模态和并行扩散Transformer块的混合架构,并扩展至120亿参数。黑森林实验室通过建立在流匹配上的方法改进了以前的最先进扩散模型,这种方法通用且概念简单,包括扩散作为一种特殊情况。此外,通过纳入旋转位置嵌入和并行注意力层来提高模型性能并改善硬件效率。
图像生成的新基准
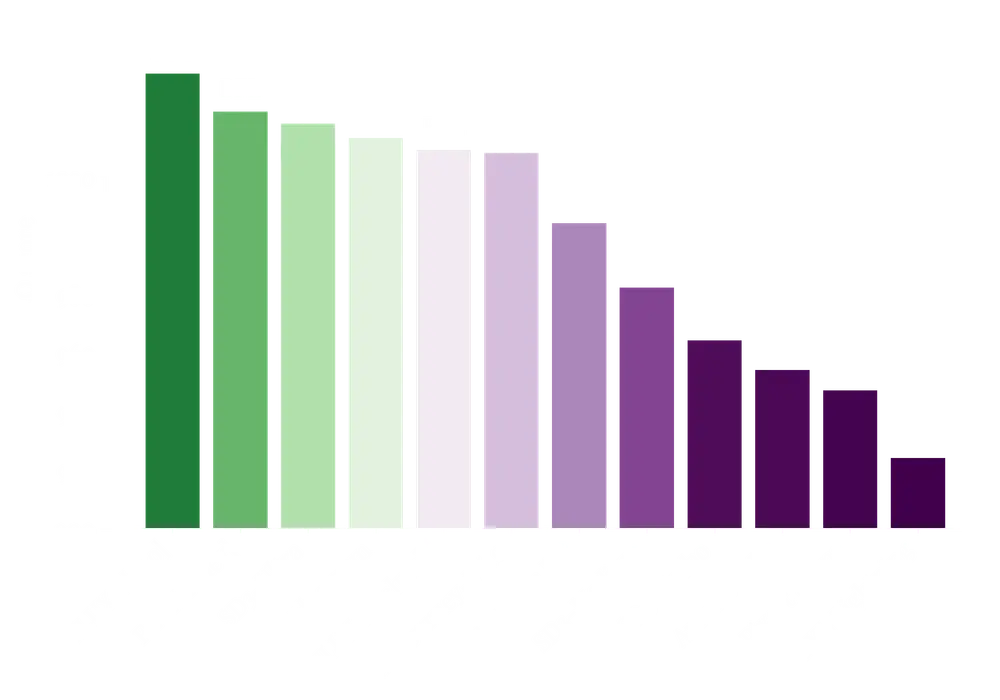
Flux.1系列模型在视觉质量、提示跟随、尺寸/比例可变性、排版和输出多样性等方面超越了流行的模型,如Midjourney v6.0、DALL·E 3(HD)和SD3-Ultra。Flux.1 Schnell是迄今为止最先进的少步骤模型,不仅超越了同类竞争对手,还超越了像Midjourney v6.0和DALL·E 3(HD)这样的强大非蒸馏模型。Flux.1系列模型专门针对预训练中保持整个输出多样性进行了微调。与当前最先进水平相比,它们提供了大幅改进的可能性。
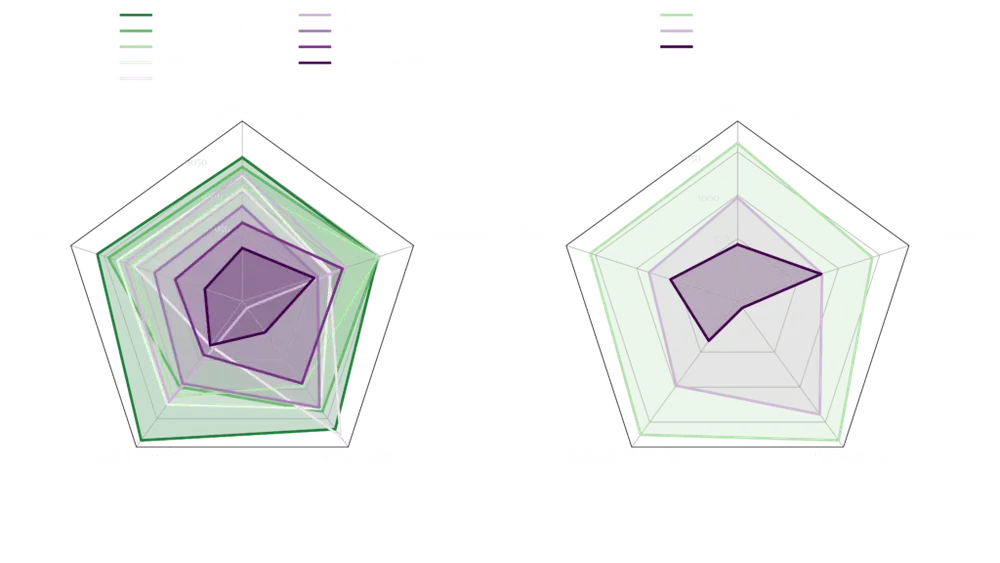
所有Flux.1模型版本都支持0.1和2.0百万像素的多样比例和分辨率范围。

下一步计划
文本到视频模型:黑森林实验室预告将发布一款基于FLUX.1的SOTA文生视频模型,目标是让所有人都能将文本转为视频,实现高清和高速的精确创作和编辑。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











