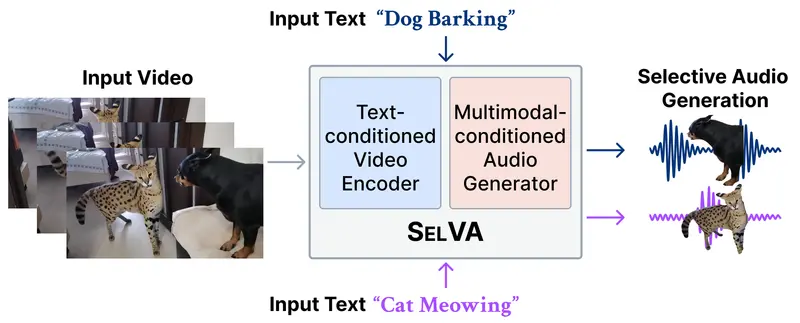
新SelVA:基于文本指令的视频选择性配音技术韩国科学技术院(KAIST)MAC 实验室与梨花女子大学 MMAI 实验室的研究人员共同提出了一项新任务:基于文本条件的选择性视频到音频生成(Text-Conditioned Selective Vi...视频模型# SelVA# 配音10小时前040