
南洋理工大学和商汤科技研究院的研究人员推出视频抠像(Video Matting)框架MatAnyone,可以实现高质量、高稳定性的视频抠像,即使在复杂的背景和多目标场景中也能保持出色的性能。MatAnyone 通过一种基于记忆传播的机制,结合区域自适应记忆融合技术,解决了传统方法在复杂背景或模糊背景下的局限性,并通过大规模高质量数据集和创新的训练策略提升了模型的稳定性和泛化能力。
- 项目主页:https://pq-yang.github.io/projects/MatAnyone
- GitHub:https://github.com/pq-yang/MatAnyone
- Demo:https://huggingface.co/spaces/PeiqingYang/MatAnyone
- 本地安装:https://pinokio.computer/item?uri=https://github.com/pinokiofactory/MatAnyone
例如,在一个包含多人物的视频场景中,MatAnyone 能够准确地将目标人物从背景中分离出来,即使背景中存在其他相似的人物或其他干扰物。它能够保持目标人物的完整性和细节(如头发、边缘等),同时避免背景中的错误抠像(如背景中的相似颜色被误判为前景)。此外,MatAnyone 还能在长视频中稳定地跟踪目标人物,即使在人物快速移动或与其他物体交互时也能保持良好的效果。

主要功能
- 高质量视频抠像:能够生成高分辨率、细节丰富的 alpha 通道(透明度图层),适用于各种视频内容,包括电影、游戏和手机视频。
- 稳定的对象跟踪:即使在复杂背景或多人物场景中,也能准确区分目标对象,并保持其在视频中的连贯性。
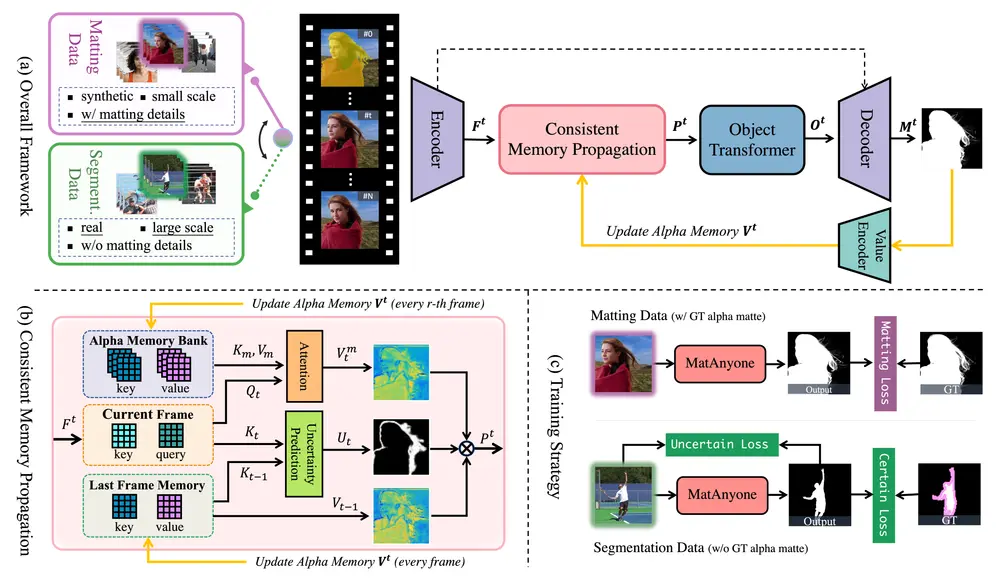
- 区域自适应记忆融合:通过记忆模块,MatAnyone 能够在视频帧之间传播信息,确保核心区域的语义稳定性和边界区域的细节一致性。
- 大规模数据集支持:通过新收集的高质量、大规模数据集(VM800 和 YouTubeMatte),MatAnyone 在训练过程中获得了更好的泛化能力。
主要特点
- 区域自适应记忆传播(CMP):通过估计每个像素相对于前一帧的变化概率,MatAnyone 自适应地融合当前帧和前一帧的信息。这种方法在核心区域保持语义稳定性,同时在边界区域保留细节。
- 核心区域监督(Core-area Supervision):通过引入分割数据来监督核心区域的语义稳定性,MatAnyone 在复杂背景下的表现优于现有方法。
- 创新的训练策略:结合分割数据和抠像数据进行训练,通过区域特定的损失函数(如改进的 DDC 损失)提升模型的泛化能力。
- 灵活的推理策略:支持递归细化(Recurrent Refinement)和无辅助(Auxiliary-free)变体,使其能够适应不同的应用场景。
工作原理
- 记忆传播模块:
- MatAnyone 使用一个记忆模块存储前一帧的 alpha 通道信息,并在当前帧中查询相关信息。
- 通过区域自适应记忆融合,模型能够根据当前帧的变化概率动态调整记忆的权重,从而在核心区域保持稳定,在边界区域保留细节。
- 核心区域监督:
- 通过分割数据对核心区域进行监督,确保模型在语义稳定性方面表现良好。
- 对于边界区域,使用改进的 DDC 损失函数进行监督,避免了传统方法中可能出现的锯齿状边缘。
- 大规模数据集:
- MatAnyone 使用新收集的高质量数据集(VM800)进行训练,该数据集在数量、多样性和细节质量上均优于现有的 VideoMatte240K 数据集。
- 通过这些数据集,模型能够更好地学习复杂的背景和多目标场景。
应用场景
- 影视制作:在电影或电视剧后期制作中,MatAnyone 可以快速准确地将演员从原始背景中分离出来,方便后期合成到新的场景中。
- 虚拟会议:在 Zoom 或其他视频会议软件中,MatAnyone 可以实时将用户从背景中分离出来,替换为虚拟背景,同时保持高质量的细节。
- 游戏开发:在游戏视频制作中,MatAnyone 可以用于将角色从绿幕中分离出来,并与游戏场景进行无缝融合。
- 社交媒体内容创作:在 TikTok、抖音等平台上,创作者可以使用 MatAnyone 快速生成高质量的抠像视频,用于特效制作或创意内容。
- 广告制作:在广告视频中,MatAnyone 可以用于将产品或人物从原始背景中分离出来,替换为更具吸引力的背景,提升视觉效果。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











