ComfyUI-LongCat-AudioDiT-TTS 是将美团最新开源的 LongCat-AudioDiT 模型原生集成到 ComfyUI 的自定义节点插件。它利用基于扩散变换器(DiT)的架构和 ODE 欧拉求解器,让你能在 ComfyUI 工作流中直接生成广播级质量(24kHz)的语音。
- GitHub:https://github.com/Saganaki22/ComfyUI-LongCat-AudioDIT-TTS
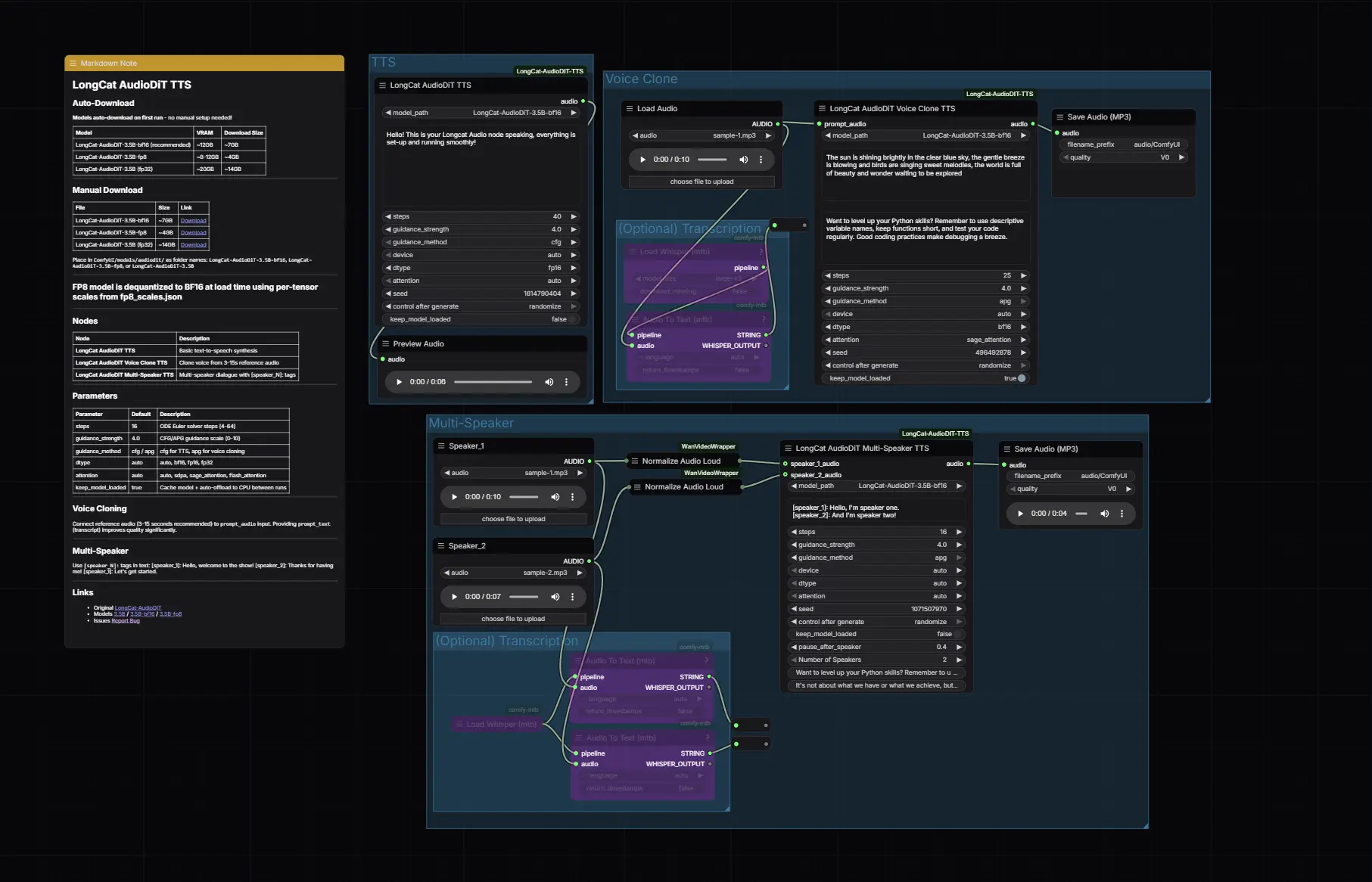
该插件的核心优势在于零样本语音克隆能力:只需提供一段 3-15 秒的参考音频,即可完美复刻说话人的音色、语调和情感,无需任何微调。此外,它还支持通过简单的标签语法生成多说话人对话,让 AI 配音和有声书制作变得前所未有的简单高效。
核心功能亮点
1. 零样本语音克隆 (Zero-Shot Voice Cloning)
- 即插即用:上传任意短音频(推荐 3-15 秒),模型即可提取声纹特征。
- 高保真复刻:精准还原原说话人的音色、呼吸感、停顿习惯甚至情绪色彩。
- 无需训练:完全基于预训练模型推理,秒级完成克隆。
2. 多说话人对话合成
- 剧本式输入:在文本中使用
[speaker_1]:,[speaker_2]:等标签,即可自动生成多人对话。 - 独立音色控制:为每个标签分配不同的参考音频,模拟真实的访谈、广播剧或会议场景。
- 智能停顿:自动在说话人切换时插入自然停顿(可配置时长)。
3. 基于扩散的高质量生成
- DiT 架构:采用 Diffusion Transformer 结合 ODE 欧拉求解器,生成的语音连贯性极强,无机械感。
- 自适应引导:支持 CFG (Classifier-Free Guidance) 和 APG (Adaptive Projected Guidance),后者专为语音克隆优化,能有效减少伪影和破音。
4. 极致性能与兼容性
- 多精度支持:
- FP8 / BF16:大幅降低显存占用(3.5B 模型仅需 8-14GB 显存),适合消费级显卡。
- FP32:提供最高理论质量(需 20GB+ 显存)。
- FP16 混合模式:针对纯 TTS 任务优化,自动处理编码器溢出问题。
- 注意力加速:支持 SDPA, SageAttention, FlashAttention,显著提升推理速度。
- 智能缓存:支持模型驻留内存 (
keep_model_loaded),避免重复加载带来的延迟。
模型版本与显存需求
插件支持自动下载多种量化版本的模型,以适应不同硬件:
| 模型版本 | 参数量 | 显存占用 (估算) | 特点 | 推荐场景 |
|---|---|---|---|---|
| 1B | 1 Billion | ~6-8 GB | 最小最快,质量尚可 | 低显存卡,快速测试 |
| 3.5B-bf16 | 3.5 Billion | ~10-14 GB | 推荐,质量与速度平衡 | 大多数 RTX 30/40 系列 |
| 3.5B-fp8 | 3.5 Billion | ~8-12 GB | 下载小,加载时反量化为 BF16 | 显存紧张但想跑大模型 |
| 3.5B (FP32) | 3.5 Billion | ~20 GB+ | 原始精度,理论最佳 | 高端卡 (3090/4090) |
注意:首次运行会自动从 HuggingFace 下载对应模型到
ComfyUI/models/audiodit/。
安装指南
方法一:ComfyUI Manager (推荐)
- 打开 ComfyUI Manager。
- 搜索
LongCat-AudioDiT。 - 点击 Install。
- 重启 ComfyUI。
方法二:手动安装
cd ComfyUI/custom_nodes
git clone https://github.com/saganaki22/ComfyUI-LongCat-AudioDIT-TTS.git
cd ComfyUI-LongCat-AudioDIT-TTS
pip install -r requirements.txt
插件启动时会自动检查并安装缺失的 Python 依赖。
节点详解与工作流
1. 基础 TTS (LongCat AudioDiT TTS)
适用于使用预设音色或不需要克隆特定人声的场景。
- 输入:
text(文本),steps(步数),guidance_strength(引导强度)。 - 输出:
audio(生成的语音)。
2. 语音克隆 (LongCat AudioDiT Voice Clone TTS)
核心节点。用于复刻特定说话人声音。
- 输入:
prompt_audio: 参考音频 (3-15 秒效果最佳)。prompt_text: (可选) 参考音频的文本转录,提供后可显著提升克隆准确度。text: 想要合成的新文本。guidance_method: 建议选择apg(自适应投影引导) 以获得更自然的克隆效果。
- 输出:
audio(克隆后的语音)。
3. 多说话人对话 (LongCat AudioDiT Multi-Speaker TTS)
用于生成多人互动的音频。
- 输入:
num_speakers: 说话人数量 (2-10)。speaker_N_audio: 每个说话人的参考音频。speaker_N_ref_text: 每个参考音频的转录文本。text: 包含标签的剧本。
- 文本格式示例:
[speaker_1]: 你好,今天天气真不错。 [speaker_2]: 是啊,很适合出去走走。 [speaker_1]: 那我们要不要去公园? - 输出:
audio(完整的对话音频)。
关键参数调优建议
| 参数 | 推荐设置 | 说明 |
|---|---|---|
| steps | 16 (快) / 32 (优) | 扩散步数。16 步已足够清晰,32 步细节更丰富。 |
| guidance_strength | 4.0 | 引导强度。过高可能导致声音僵硬,过低可能偏离文本。 |
| guidance_method | apg (克隆) / cfg (TTS) | 语音克隆务必使用 apg,能显著减少噪声和失真。 |
| dtype | auto 或 bf16 | 除非显存极度紧张,否则不要用 FP16 跑克隆任务(会溢出)。 |
| attention | sage_attention | 如果安装了 SageAttention,选它速度最快。 |
| pause_after_speaker | 0.4 | 多说话人模式下,角色切换间的静音秒数。 |
⚠️ 重要提示:关于 FP16 的限制
- 纯 TTS:可以使用 FP16 加速。
- 语音克隆/多说话人:不支持 FP16。因为参考音频编码过程在 FP16 下会导致数值溢出 (NaN),产生静音或噪音。
- 自动保护:如果你在克隆节点选择了 FP16,插件会自动将其升级为 BF16 并弹出警告。请确保你的显卡支持 BF16 (RTX 30 系及以上)。
应用场景
- 🎧 有声书制作:为不同角色分配不同音色,一键生成长篇对话。
- 📹 视频配音:克隆自己的声音或名人声音(需注意版权)进行视频解说。
- 🎮 游戏 NPC:快速生成大量带有不同情绪和音色的 NPC 台词。
- 📻 广播剧创作:单人模拟多人对话,低成本制作剧情音频。
- 🔊 个性化助手:为本地 AI 助手定制独特的语音反馈。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











