
美团 LongCat 团队推出了 LongCat-AudioDiT,这是一种基于扩散模型的最新文本转语音(TTS)系统。该模型的核心创新在于摒弃了传统的中间声学特征(如梅尔频谱图),直接在波形潜空间(Waveform Latent Space)中进行扩散生成。
- GitHub:https://github.com/meituan-longcat/LongCat-AudioDiT
- LongCat-AudioDiT-3.5B:https://huggingface.co/meituan-longcat/LongCat-AudioDiT-3.5B
- LongCat-AudioDiT-1B:https://huggingface.co/meituan-longcat/LongCat-AudioDiT-1B
这种端到端的架构不仅简化了处理流程,还有效解决了传统多级转换带来的误差累积问题。在权威的 Seed 基准测试中,LongCat-AudioDiT 在零样本语音克隆的说话人相似度上超越了此前的最先进模型(如 Seed-TTS),同时保持了极高的可懂度和自然度。目前,代码和模型权重已正式开源。
核心功能
1. 零样本声音克隆 (Zero-Shot Voice Cloning)
只需提供一段任意长度的参考音频(Prompt),模型即可精准复刻说话人的音色、语调、节奏和情感,无需针对特定说话人进行微调或额外训练。
2. 高保真语音生成
生成的语音细节丰富,背景干净,无明显机械感或伪影。通过直接在潜空间操作,保留了更多原始波形的细微特征,听感接近真人录音。
3. 多语言与长文本支持
支持中文、英文等多种语言的混合输入。得益于扩散模型的稳定性,在处理长文本时能保持语气的连贯性,避免出现断句异常或音色漂移。
4. 极简架构
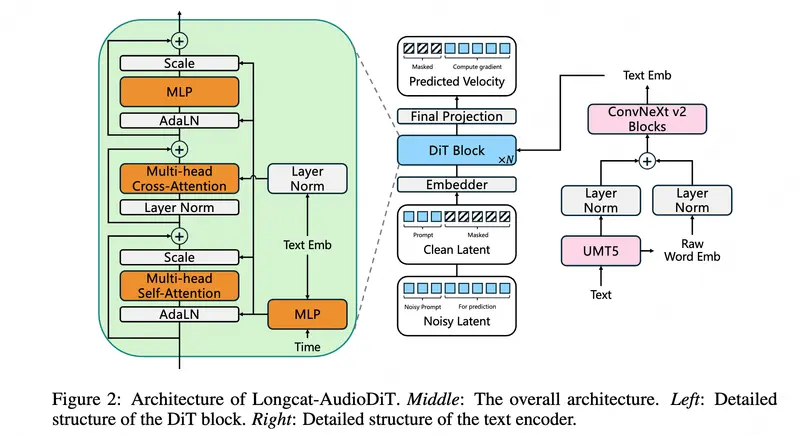
整个系统仅由两个核心组件构成:
- 波形变分自编码器 (Wav-VAE):负责将原始音频波形压缩为紧凑的潜变量,并能高保真地还原。
- 扩散主干网络 (Diffusion Backbone):基于 Transformer 架构,负责根据文本和参考音频,从噪声中逐步生成目标潜变量。
技术亮点与创新
1. 直接在波形潜空间运行
传统 TTS 通常遵循 文本 -> 频谱图 -> 声码器 -> 波形 的多阶段流程,每一级转换都会带来信息损失。LongCat-AudioDiT 采用 文本 -> 潜变量 -> 波形 的端到端路径,直接从 Wav-VAE 的潜空间生成数据,从根本上减少了失真。
2. 修正训练 - 推理不匹配 (Training-Inference Mismatch)
团队发现并修复了扩散模型在 TTS 任务中长期存在的一个隐患:在推理过程中,提示音频(Prompt)的特征可能会随去噪步骤发生偏移,导致音色不一致。LongCat-AudioDiT 引入了一种机制,在推理的每一步强制固定提示部分的特征,确保克隆音色的稳定性。
3. 自适应投影引导 (Adaptive Projected Guidance)
取代了传统的无分类器引导(Classifier-Free Guidance, CFG),该方法通过更柔和、自适应的方式引导生成过程。这不仅提升了语音质量,还有效避免了强 CFG 常导致的过饱和、刺耳或破音等 artifacts。
4. 关于 Wav-VAE 的反直觉发现
研究揭示了一个有趣的现象:Wav-VAE 的重建保真度越高,并不一定意味着最终 TTS 效果越好。过度的重建能力可能会引入难以被扩散模型拟合的噪声或复杂细节。团队通过实验找到了重建质量与生成可控性之间的最佳平衡点。
性能表现
在 Seed 基准测试(业界公认的语音克隆评测集)中,LongCat-AudioDiT-3.5B 版本取得了 SOTA(State-of-the-Art)成绩:
| 指标 | 数据集 | LongCat-TTS-3.5B | 此前最佳 (Seed-TTS) | 提升 |
|---|---|---|---|---|
| 说话人相似度 | Seed-ZH (中文) | 0.818 | 0.809 | +1.1% |
| 说话人相似度 | Seed-Hard (困难集) | 0.797 | 0.776 | +2.7% |
| 可懂度 (WER/CER) | 综合评估 | 极具竞争力 | - | 持平或更优 |
| 自然度 (MOS) | 主观听测 | 高分 | - | 接近真人 |
注:数据显示其在保持极高清晰度的同时,在音色相似度上实现了新的突破,特别是在高难度的跨语句克隆场景中表现稳健。
工作原理简述
- 编码阶段:使用预训练的 Wav-VAE 将参考音频和目标音频(训练时)压缩为低维潜变量序列。
- 生成阶段:
- 输入文本嵌入和参考音频的潜变量。
- 扩散过程:Transformer 主干网络接收随机噪声,结合文本和参考信息,通过多步去噪,逐步“雕刻”出目标音频的潜变量。
- 在此过程中,应用自适应投影引导来优化生成方向,并锁定参考音频部分的特征以防止漂移。
- 解码阶段:将生成的潜变量序列输入 Wav-VAE 解码器,还原为最终的音频波形。
开源与应用
- 开源状态:代码、模型权重(包括 3.5B 版本)及训练/推理脚本已在 GitHub 和 HuggingFace 发布。
- 适用场景:
- 有声书与配音:快速生成高质量、情感丰富的朗读音频。
- 虚拟人与游戏:为角色提供低成本、高相似度的语音方案。
- 内容创作:视频创作者可利用少量样本克隆特定音色进行解说。
- 辅助技术:为失语症患者保留或重建个性化语音。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











