如果你正在使用 ComfyUI 进行视频或图像模型推理,现在可以更高效地完成生成任务了!
由北京大学与华为的研究人员提出的MagCache 扩散模型加速技术,开发团队已经推出插件 ComfyUI-MagCache。该插件不仅兼容原生节点流程,还支持主流模型如 Wan2.1、HunyuanVideo 和 FLUX-dev,最高可实现 2~3 倍的推理加速,同时保持高质量输出。
🔧 什么是 MagCache?
MagCache 是一种无需训练、即插即用的缓存加速方法,基于“残差幅度变化”规律进行误差建模,并通过自适应跳步策略动态减少冗余计算步骤,从而显著提升扩散模型推理效率。

其核心优势包括:
- 无需修改模型结构
- 支持多种视频/图像扩散模型
- 仅需一个样本完成校准
- 加速比达 2~3 倍,画质损失可控
🚀 支持模型一览
目前 ComfyUI-MagCache 已支持以下主流模型:
| 模型类型 | 模型名称 |
|---|---|
| 视频扩散 | Wan2.1 T2V / I2V |
| 视频扩散 | HunyuanVideo T2V |
| 图像扩散 | FLUX-dev T2I |
未来还将持续扩展更多模型支持。
⚙️ 安装方式
目前还没有上架ComfyUI Manager,需要手动进行安装,只需三步即可在你的 ComfyUI 中启用 MagCache:
- 进入 custom_nodes 目录
cd ComfyUI/custom_nodes - 克隆插件仓库
git clone https://github.com/zehong-ma/ComfyUI-MagCache.git - 安装依赖
cd ComfyUI-MagCache/
pip install -r requirements.txt - 重新启动 ComfyUI
🧪 使用说明
✅ 添加 MagCache 节点
- 在工作流中,将 MagCache 节点插入到“加载扩散模型”或“加载 LoRA”节点之后。
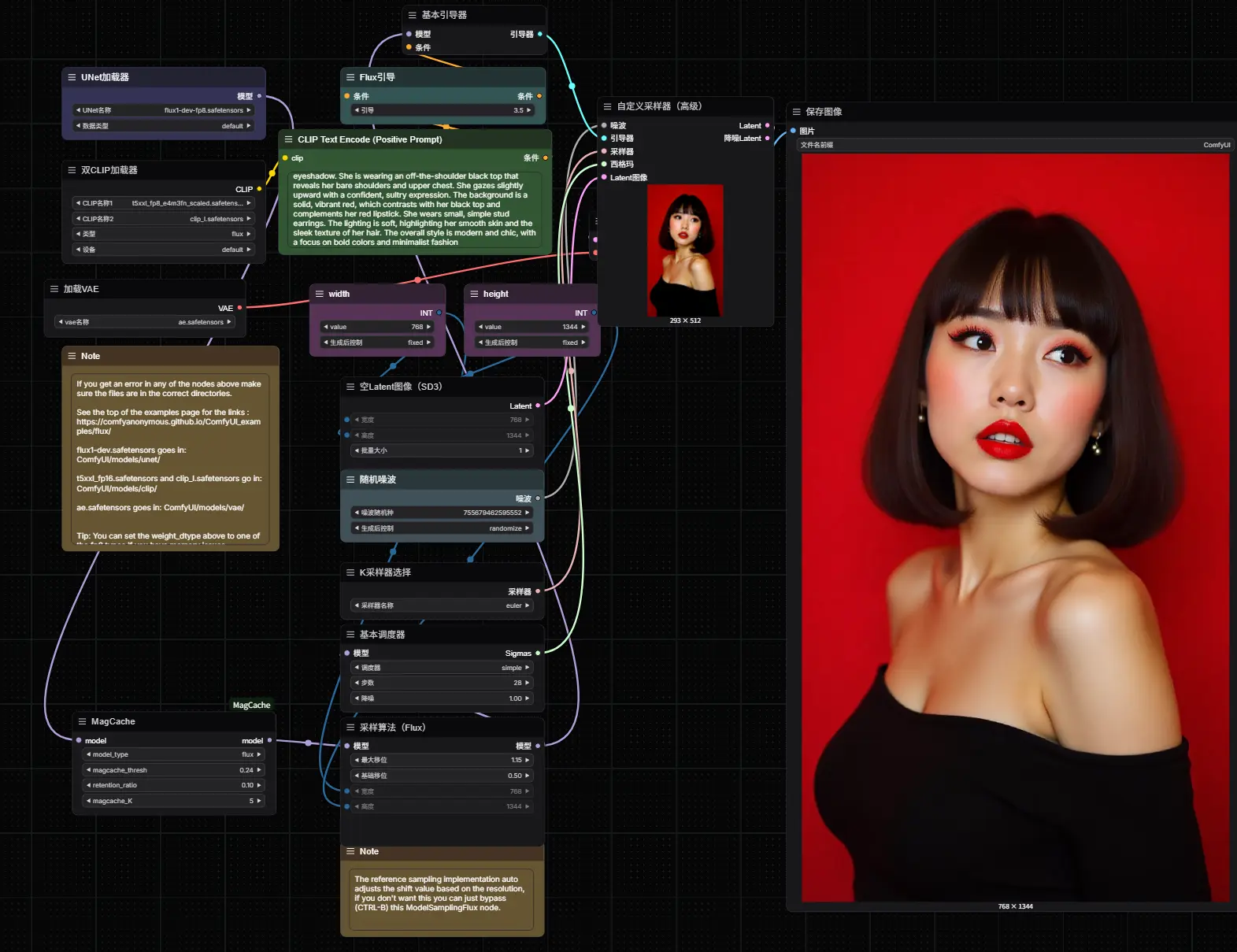
- 参数推荐如下(可根据需求微调):
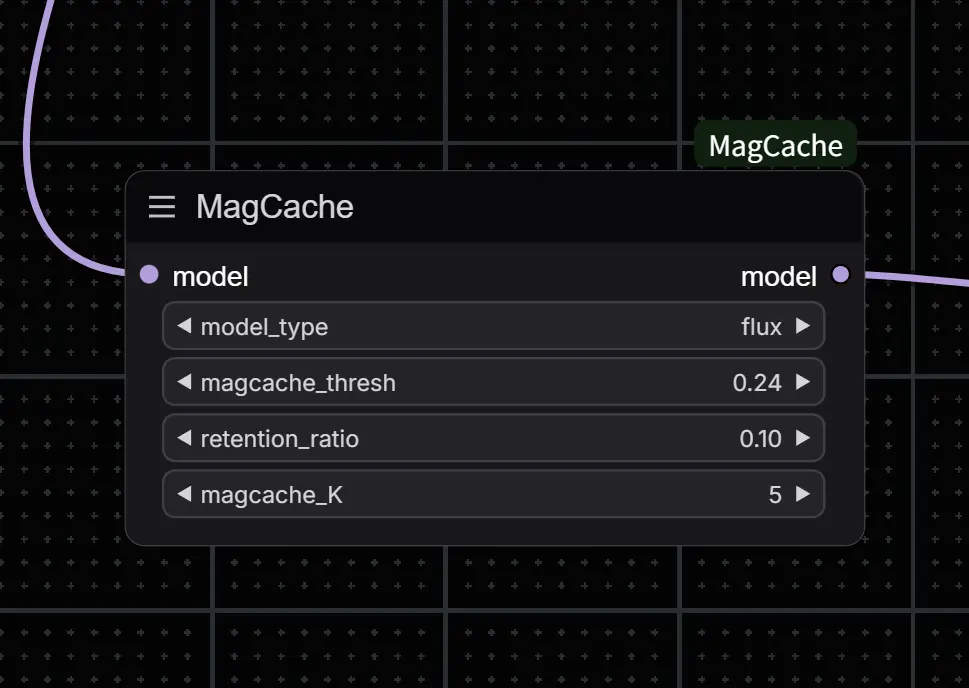
| 模型 | magcache_thresh | retention_ratio | magcache_K |
|---|---|---|---|
| FLUX | 0.24 | 0.1 | 5 |
| HunyuanVideo-T2V | 0.24 | 0.2 | 6 |
| Wan2.1-T2V-1.3B | 0.12 | 0.2 | 4 |
| Wan2.1-T2V-14B | 0.24 | 0.2 | 6 |
| Wan2.1-I2V-480P/720P | 0.24 | 0.2 | 6 |
如果发现质量下降,建议适当降低
magcache_thresh和magcache_K值。
💡 使用编译模型(可选)
为了进一步加速推理,ComfyUI-MagCache 还提供了“编译模型”节点,利用 PyTorch 的 torch.compile 技术对模型进行优化,首次运行稍慢,后续推理速度大幅提升。
📁 示例工作流
插件已提供多个示例流程供参考,位于 examples 文件夹中,涵盖:
- FLUX-dev(图像生成)
- HunyuanVideo-T2V
- Wan2.1-T2V
- Wan2.1-I2V
🧾 性能表现总结
| 模型 | 加速比 | 画质损失 |
|---|---|---|
| Wan2.1 | 2.68x | 可接受 |
| HunyuanVideo | 2.82x | 几乎无损 |
| FLUX-dev | ~2.1x | 微小损失 |
实验表明,在 LPIPS、SSIM、PSNR 等指标上,MagCache 表现优于现有方法,是当前最实用的扩散模型加速方案之一。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...