在 AI 语音交互领域,长期存在一个痛点:传统的“语音识别 (ASR) + 大语言模型 (LLM) + 语音合成 (TTS)”三段式架构,导致信息丢失、延迟累积、情感匮乏,且难以实现真正的实时打断与插话。
腾讯 AI 实验室正式开源 Covo-Audio —— 一个仅 70 亿参数 (7B) 的端到端大型音频语言模型。它摒弃了繁琐的中间转换,直接在单一统一架构内处理连续音频输入并生成音频输出,实现了“听 - 思 - 说”的一体化。
- GitHub:https://github.com/Tencent/Covo-Audio
- 模型:https://huggingface.co/tencent/Covo-Audio-Chat
在多项权威基准测试中,Covo-Audio 以小巧的体量,性能媲美甚至超越了 GPT-4o Audio、Step-Audio 2 (32B) 等巨型模型,尤其在中文情感共情和全双工实时交互上达到了业界顶尖水平。
核心突破:为什么 Covo-Audio 与众不同?
1. 🎙️ 真正的端到端 (End-to-End)
- 拒绝“传声筒”:不再是“语音转文字 -> 文字思考 -> 文字转语音”。Covo-Audio 直接理解声波中的语义、语气、停顿和情感,并直接生成带有丰富情感的语音波形。
- 信息零丢失:保留了原声中的微妙细节(如犹豫、强调、笑声),让 AI 的回答不再机械冰冷。
2. 🗣️ 原生全双工 (Native Full-Duplex)
- 边说边听:Covo-Audio-Chat-FD 变体支持真正的实时交互。AI 可以在你说话时倾听,适时插话、附和(“嗯嗯”、“我明白”),或优雅地处理被打断的情况。
- 拟人节奏:通过预训练学习了人类对话的自然节奏,轮次切换成功率高达 99.7%,远超竞品 Moshi (96.8%)。
3. 🧠 智能与音色解耦 (Decoupling)
- 灵活换肤:创新性地将“对话智商”与“声音风格”分离。你可以用几分钟的录音样本,让同一个高智商 AI 大脑瞬间切换成任何人的声音(如明星、亲人、卡通角色),而无需重新训练核心能力。
- 高质量 TTS 迁移:利用上下文适应技术,将高质量语音合成数据的能力迁移到对话模型中,既聪明又好听。
4. 📉 小参数,大能量
- 极致效率:仅 7B 参数量,却在 URO-Bench、VCB Bench 等多个测试中超越了几十亿参数的大模型。这意味着更低的部署成本、更快的响应速度,甚至有望在高端消费级显卡上本地运行。
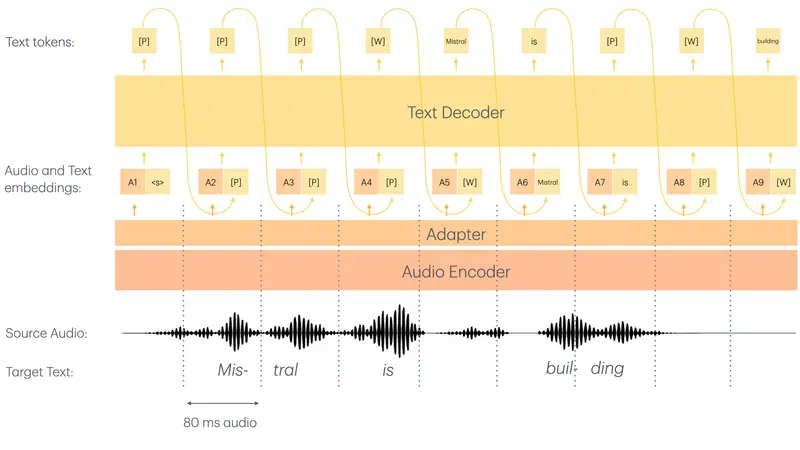
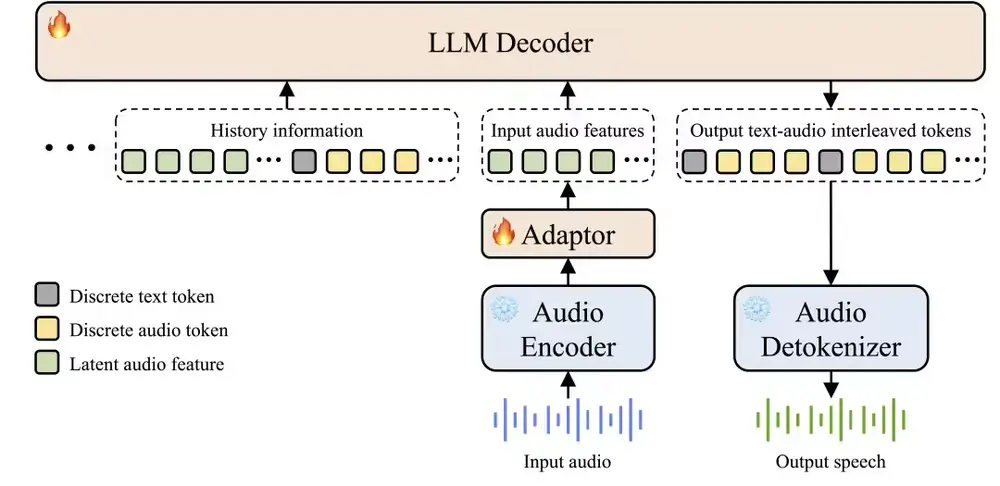
技术架构:三模态交织的智慧
Covo-Audio 的成功源于其独特的分层三模态语音 - 文本交错框架:
- 耳朵 (Whisper-large-v3):强大的语音编码器,擅长嘈杂环境下的听觉感知。
- 神经束 (Adapter):轻量级适配器,将声学特征转化为大模型可理解的格式。
- 大脑 (Qwen2.5-7B):基于通义千问 2.5 基座,负责深度推理、逻辑判断和对话规划。
- 嘴巴 (Speech Tokenizer + Decoder):将离散的语音令牌还原为 24KHz 高保真波形。
训练秘籍:
- 三模态融合:同时处理连续声学特征、离散语音令牌和自然语言文本,让模型既懂“说什么”也懂“怎么说”。
- 伪装训练:巧妙地将 TTS 数据包装成对话数据进行训练,既学会了百变音色,又没变笨。
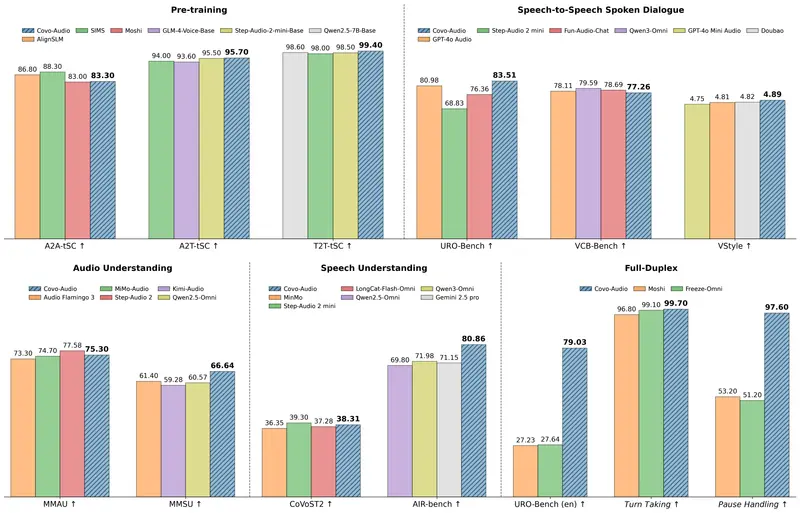
实测表现:全面领先
| 测试维度 | 关键指标 | Covo-Audio 表现 | 对比竞品 (GPT-4o/Step-Audio 2 等) |
|---|---|---|---|
| 口语对话 | URO-Bench (中文) | 三项第一,AlpacaEval 90.02 分 | 超越 GPT-4o Audio, Qwen3-Omni |
| 指令遵循 | VCB Bench (中文) | 93.07 分 (全场最高) | 显著领先同类开源模型 |
| 情感共情 | VStyle (愤怒/悲伤/焦虑) | 三项全部第一 (最高 5.00 分) | 中文场景表现最佳,英文媲美顶尖商用 |
| 全双工交互 | 打断/停顿/附和处理 | 打断处理 96.81%,停顿 97.6% | 远超 Moshi (停顿仅 53.2%) |
| 音频理解 | MMAU (音乐/环境音) | 音乐理解全场最高 (76.05%) | 7B 模型中排名第二,仅次于 32B 模型 |
| 鲁棒性 | 噪音/说话人变化 | 三项子任务全部创纪录 | 抗干扰能力极强 |
应用场景展望
- 🤖 超自然虚拟助手:客服、陪伴型机器人,能听懂用户的愤怒与悲伤,给予有温度的回应。
- 🎧 实时翻译耳机:直接语音进、语音出,保留原说话人的语气和情感,跨语言交流无障碍。
- 🎮 游戏 NPC:拥有无限对话能力且声音多变的 NPC,能根据玩家情绪实时调整语调。
- 🎙️ 个性化有声书:用任意音色朗读故事,同时保持对故事情感的精准演绎。
- 📱 本地化隐私保护:得益于 7B 的小体积,未来可部署在手机或边缘设备上,实现完全离线的私密语音交互。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...