在基于大语言模型(LLM)的文本转语音(TTS)领域,开发者长期面临一个“不可能三角”:速度、质量与可靠性难以兼得。传统的 LLM-TTS 系统往往因为文本与音频表示的不匹配,导致推理缓慢、内存消耗巨大,甚至出现“幻觉”——即模型跳过文本、胡编乱造或丢失内容。
- 1B (英语): huggingface.co/HumeAI/tada-1b
- 3B (多语言): huggingface.co/HumeAI/tada-3b-ml
- Demo: huggingface.co/spaces/HumeAI/tada
- GitHub: github.com/HumeAI/tada
今日,Hume AI 正式发布了其首个开源 TTS 模型 TADA(Text-Acoustic Dual-Aligned)。该模型通过创新的文本 - 声学双对齐标记化方案,彻底重构了语音生成的底层逻辑。实测数据显示,TADA 的实时语音生成速度是同类 LLM-TTS 系统的 5 倍以上,同时在长达 700 秒的音频生成中实现了 零内容幻觉,为端侧部署和长篇语音应用树立了新标杆。

核心痛点:为何传统 LLM-TTS 会“失真”?
要理解 TADA 的突破,首先需要看清现有技术的瓶颈。
在自然语言处理中,1 秒的音频通常包含 12.5 到 25 个声学帧,而对应的文本可能只有 2-3 个词元(Token)。这种数量级的不匹配迫使传统模型必须处理极长的音频序列,导致:
- 上下文窗口爆炸:显存占用高,推理速度慢。
- 内容丢失风险:模型在漫长的音频生成过程中容易“忘记”原始文本,导致跳读、漏读或插入不存在的内容(幻觉)。
- 妥协方案:现有系统常通过降低音频帧率或引入中间语义层来缓解,但这往往以牺牲音质表现力或增加系统复杂度为代价。
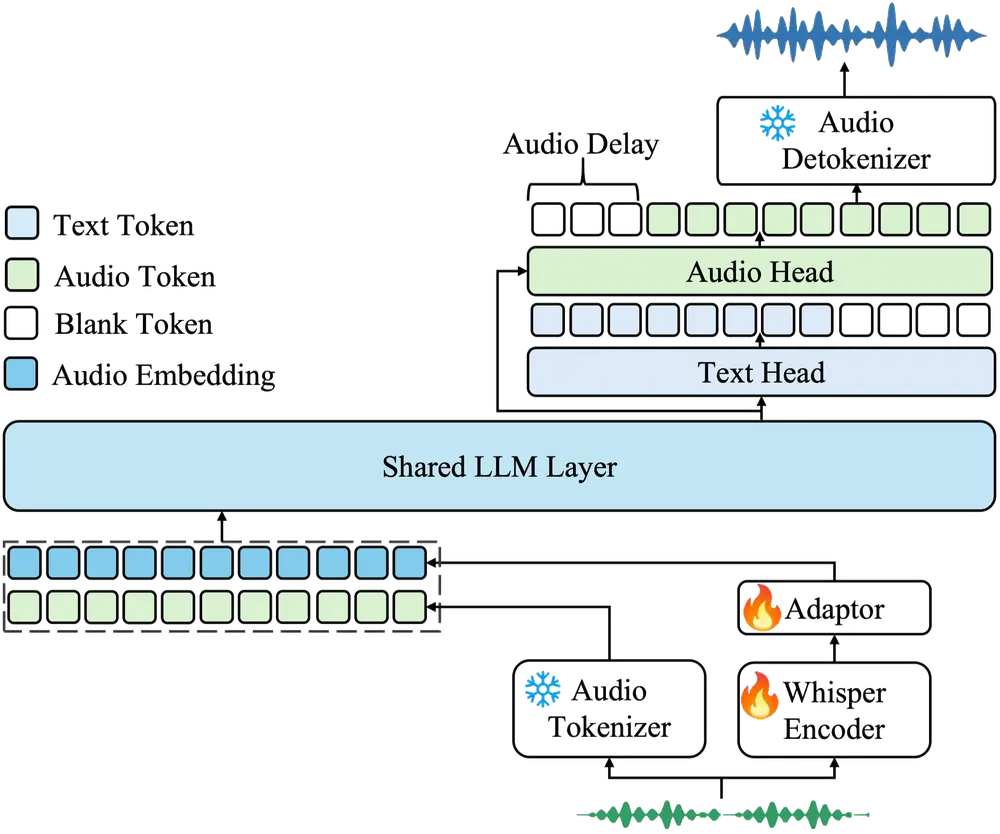
TADA 的解决方案:一对一同步标记化
TADA 选择了一条截然不同的技术路径。它没有试图压缩音频,而是通过一种新颖的标记化方案,强制实现文本词元与声学向量的一对一严格映射。
- 同步流架构:在 TADA 中,每一个大语言模型的推理步骤,精确对应一个文本词元和一个连续的声学向量。文本和语音在模型内部“步调一致”地流动。
- 结构性防幻觉:由于这种严格的 1:1 绑定,模型从架构层面就无法跳过或虚构内容。如果文本有 100 个词,模型就必须生成 100 个对应的音频片段,从根本上杜绝了“胡言乱语”。
- 高效编码:输入端,编码器从对应文本词元的音频片段中提取声学特征;输出端,LLM 的最终隐藏状态直接调节流匹配头(Flow Matching Head)生成声学特征。
性能实测:快 5 倍,零幻觉,长上下文
在 Hume AI 进行的广泛评估中,TADA 展现了压倒性的性能优势:
1. 极速推理
- 实时因子(RTF):低至 0.09。这意味着生成 1 秒的音频仅需 0.09 秒的计算时间。
- 效率对比:相比同类基于 LLM 的 TTS 系统,速度快了 5 倍以上。这得益于其每秒仅需处理 2-3 个词元,而其他方法需处理 12.5-75 个。
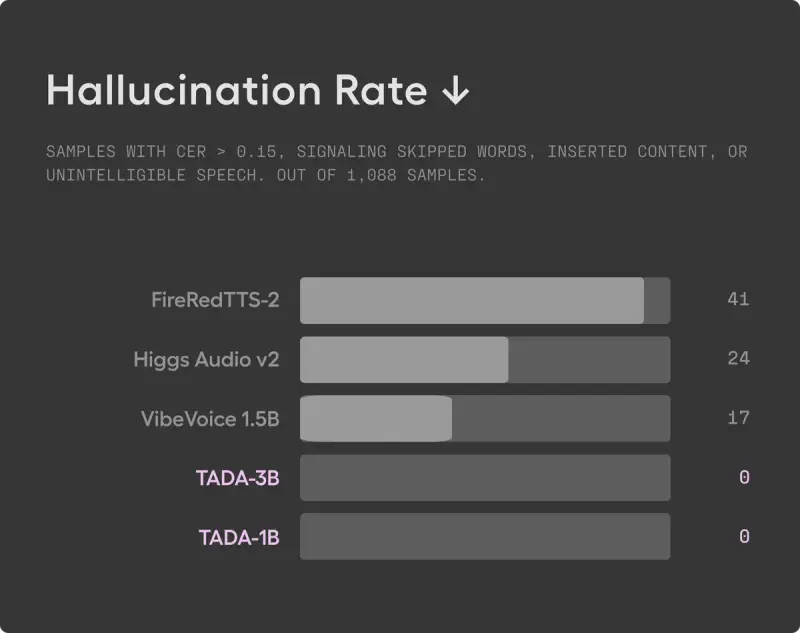
2. 绝对可靠(零幻觉)
- 测试规模:在 LibriTTSR 数据集的 1000+ 测试样本中进行验证。
- 结果:字符错误率(CER)超过 0.15 的样本数为 0。TADA 实现了 零幻觉,没有发生任何跳读、漏读或插入无关内容的情况。这对于医疗、金融等对准确性要求极高的场景至关重要。
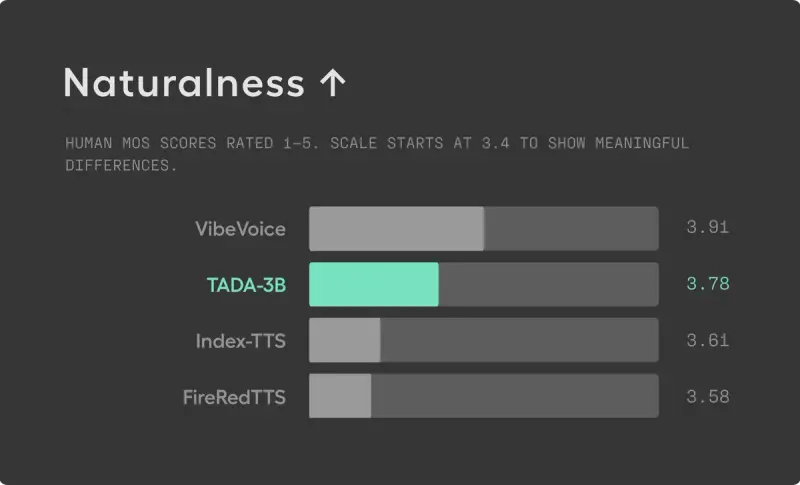
3. 卓越的长文本能力
- 上下文窗口:传统系统在 2048 词元预算下通常只能支持约 70 秒音频,而 TADA 在相同预算下可支持长达 700 秒(约 12 分钟)的连续语音。
- 应用场景:这使得 TADA 能够轻松胜任有声书朗读、长篇新闻播报及多轮深度对话,无需频繁重置上下文。
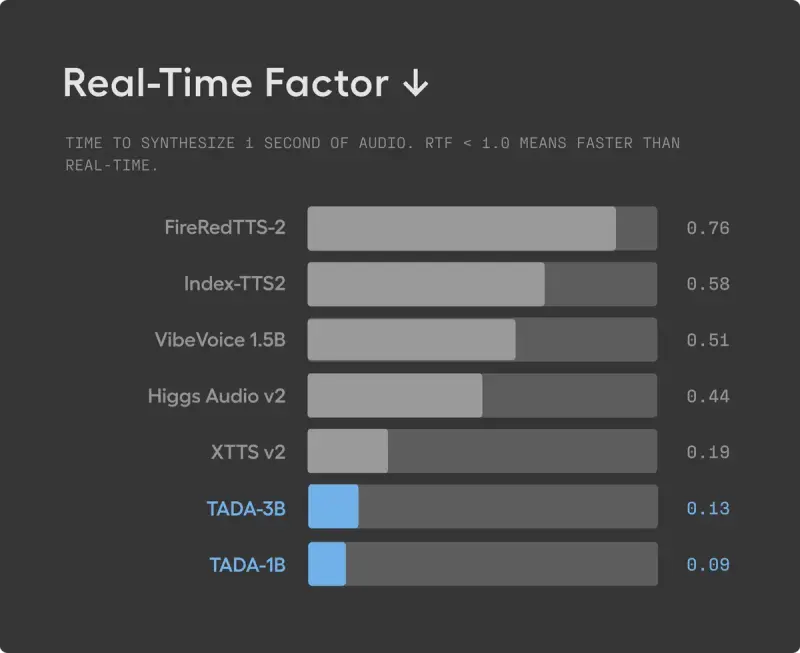
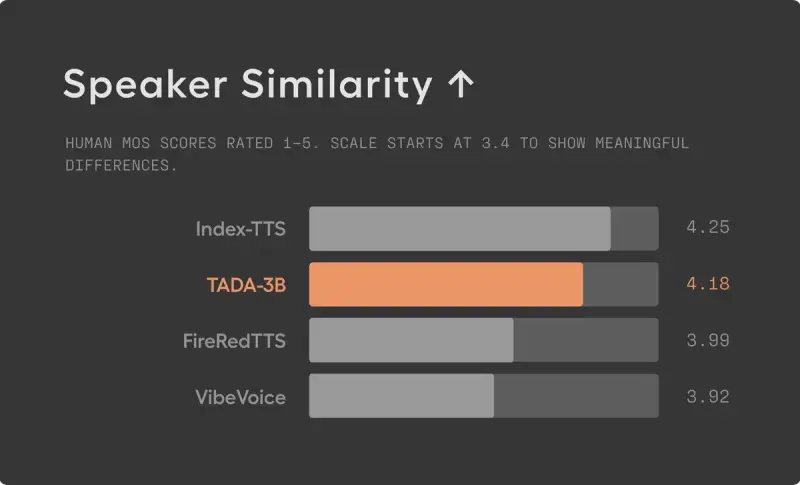
4. 高保真音质
- 说话人相似度:4.18 / 5.0
- 自然度:3.78 / 5.0
- 在人类评估中,TADA 在富有表现力的长语音任务中总体排名第二,超越了部分在更大数据集上训练的竞品。
战略意义:端侧部署与隐私保护
TADA 的高效性使其成为端侧(On-Device)部署的理想选择。
- 低延迟:无需云端往返,在手机、平板或边缘设备上即可实现毫秒级响应。
- 数据隐私:所有语音生成均在本地完成,敏感数据无需上传云端,完美契合 GDPR 等隐私法规。
- 成本优化:摆脱了对昂贵 GPU 云服务的依赖,大幅降低了大规模应用的运营成本。
局限性与未来展望
尽管表现优异,Hume AI 也坦诚地指出了当前版本的局限性:
- 长语音漂移:在超过 10 分钟的连续生成中,偶尔会出现说话人音色漂移。目前建议通过定期重置上下文来缓解,团队正在通过在线拒绝采样策略进一步优化。
- 多模态差距:当模型同时生成文本和语音时,纯文本的逻辑质量略有下降。团队已引入“语音自由引导”(Speech-Free Guidance)技术来平衡这一差距。
- 语言覆盖:当前版本主要支持英语及其他七种语言。Hume AI 计划利用其庞大的微调数据库,训练覆盖更多语种的更大规模模型。
- 场景适配:目前模型主要针对语音延续任务预训练,用于智能助手场景需进一步微调。
对于希望在设备端构建低延迟、高隐私语音应用,或需要处理长篇高可靠性语音内容的开发者而言,TADA 无疑是目前最具竞争力的开源选择。Hume AI 邀请全球研究人员和开发者基于此架构继续探索,共同推动语音 AI 向更高效、更可信的方向演进。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











