
中国科学院计算技术研究所、中国科学院人工智能安全重点实验室和中国科学院大学的研究人员推出新型语音语言模型 LLaMA-Omni 2 ,旨在实现高质量的实时语音交互。LLaMA-Omni 2 基于 Qwen2.5 系列模型,集成了语音编码器和自回归流式语音解码器,能够在仅使用 200K 多轮语音对话样本进行训练的情况下,展现出强大的语音问答和语音指令跟随能力,超越了之前需要数百万小时语音数据训练的模型(如 GLM-4-Voice)。LLaMA-Omni 2 通过创新的模型架构和高效的训练策略,实现了低延迟、自然流畅的语音生成,为下一代人机交互提供了新的解决方案。
- GitHub:https://github.com/ictnlp/LLaMA-Omni2
- 模型:https://huggingface.co/collections/ICTNLP/llama-omni-67fdfb852c60470175e36e9c
主要功能
- 实时语音交互: LLaMA-Omni 2 能够在用户说话的同时实时生成回应,延迟低至 600 毫秒以内,满足实时交互的需求。
- 高质量语音生成: 通过自回归流式语音解码器和因果流匹配模型,LLaMA-Omni 2 生成的语音自然流畅,接近人类水平。
- 语音指令跟随: 模型能够准确理解和执行语音指令,生成符合指令要求的语音回应。
- 多轮对话支持: LLaMA-Omni 2 支持多轮对话,能够根据对话历史生成连贯的语音回应。
- 低资源训练: 仅需 200K 多轮语音对话样本即可实现高性能,显著降低了训练成本。
主要特点
- 模块化架构: LLaMA-Omni 2 采用模块化设计,将语音编码器、语言模型(LLM)和语音解码器结合在一起,充分发挥各模块的优势。
- 自回归流式生成: 通过自回归文本到语音语言模型(TTS LM)和因果流匹配模型,实现语音的流式生成,确保语音生成的自然性和流畅性。
- 高效的训练策略: 采用两阶段训练方法,先分别训练语音到文本和文本到语音模块,再联合训练,确保模型在语音理解和生成上的性能。
- 低延迟设计: 通过优化读写策略(Read-R-Write-W),在生成文本的同时生成语音,显著降低了系统响应时间。
- 多语言支持: 模型支持多种语言的语音交互,具有广泛的应用前景。
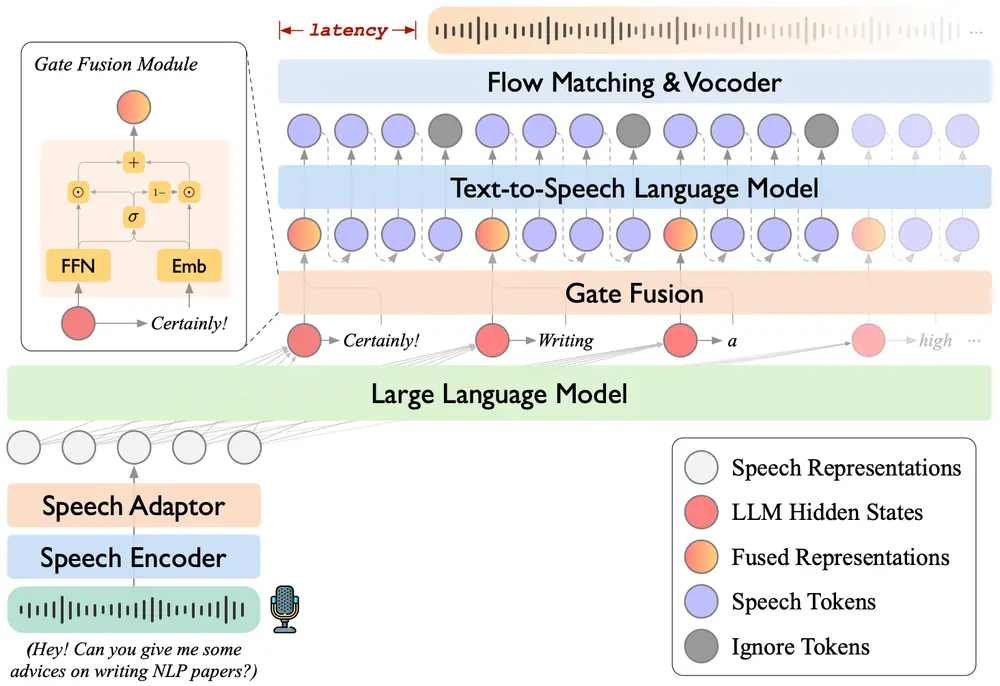
工作原理
- 语音理解: 使用 Whisper-large-v3 的编码器将输入语音转换为特征表示,然后通过语音适配器(包括降采样模块和前馈网络)进一步处理,最终输入到 LLM 中。
- 语音生成: 从 LLM 的输出中提取隐藏状态和文本标记,通过门控融合模块(Gate Fusion Module)将它们融合后输入到 TTS LM 中。TTS LM 生成语音标记,然后通过因果流匹配模型和 HiFi-GAN 语音合成器生成最终的语音波形。
- 两阶段训练: 第一阶段分别训练语音到文本和文本到语音模块;第二阶段联合训练语音到语音模块,优化整体性能。
- 流式生成策略: 采用“读-R-写-W”策略,即每读取 R 个文本标记后生成 W 个语音标记,实现语音的流式生成。
应用场景
- 智能语音助手: LLaMA-Omni 2 可以作为智能语音助手,实时响应用户的语音指令,提供信息查询、日程提醒、天气预报等服务。
- 语音客服: 在客服场景中,LLaMA-Omni 2 能够实时回答客户问题,提供个性化的语音服务,提升客户体验。
- 语音教育: 用于语言学习和教育场景,LLaMA-Omni 2 可以实时生成语音回应,帮助学生练习口语。
- 语音内容创作: 创作者可以使用 LLaMA-Omni 2 生成有声读物、播客等语音内容,提升创作效率。
- 多语言翻译: LLaMA-Omni 2 支持多语言语音交互,可以实时将一种语言的语音翻译成另一种语言的语音,促进跨语言交流。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











