英伟达推出的 Nemotron-Speech-Streaming-En-0.6B 是 Nemotron Speech 系列中的首个统一语音识别(ASR)模型,专为实时英语转录场景设计。它同时支持低延迟流式处理(如语音助手)和高吞吐批量处理(如语音日志转写),并在单个模型中实现了运行时灵活性与生产级效率的平衡。
- 模型:https://huggingface.co/nvidia/nemotron-speech-streaming-en-0.6b
- Demo:https://huggingface.co/spaces/nvidia/nemotron-speech-streaming-en-0.6b
该模型原生输出带标点符号与正确大小写的文本,无需后处理。更重要的是,它采用缓存感知的流式架构,显著提升计算效率,降低部署成本。
为什么选择 Nemotron-Speech-Streaming-En-0.6B?
1. 真正的流式架构,非“伪流式”
传统流式 ASR 模型常采用“缓冲”策略——即等待固定长度音频片段后再处理,导致端到端延迟不可控。
Nemotron 则采用 缓存感知(Cache-Aware)设计:
- 仅对新增音频块进行计算;
- 重用前序帧的编码器上下文缓存(包括自注意力与卷积层);
- 每个音频帧严格非重叠处理,无冗余计算。
这一设计使模型在维持高准确率的同时,将端到端延迟压缩至最低,适用于语音助手、实时字幕、客服对话等对响应速度敏感的场景。
2. 更高的吞吐与更低的运行成本
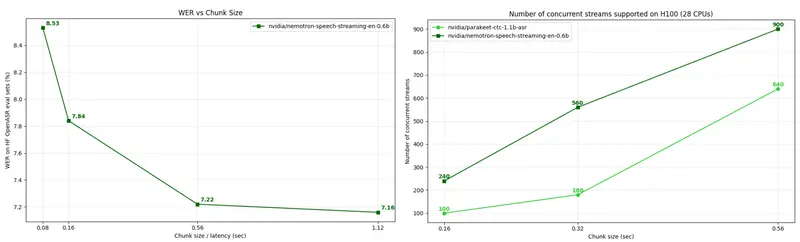
由于避免了重复计算,Nemotron 在相同 GPU 内存限制下可支持更多并行音频流。这意味着:
- 单卡可服务更多用户;
- 单位请求的计算成本显著下降;
- 更适合大规模生产部署。
3. 运行时动态调节延迟-准确率平衡
模型支持在推理时动态选择音频块大小,包括:
- 80ms(超低延迟,适合交互式语音)
- 160ms(平衡点)
- 560ms / 1120ms(高吞吐批量处理)
无需重新训练或切换模型,即可在同一部署实例中适配不同业务需求。
4. 开箱即用的文本质量
输出文本自动包含标点符号与正确大小写(如句首大写、专有名词识别),省去额外后处理模块,简化部署流程。
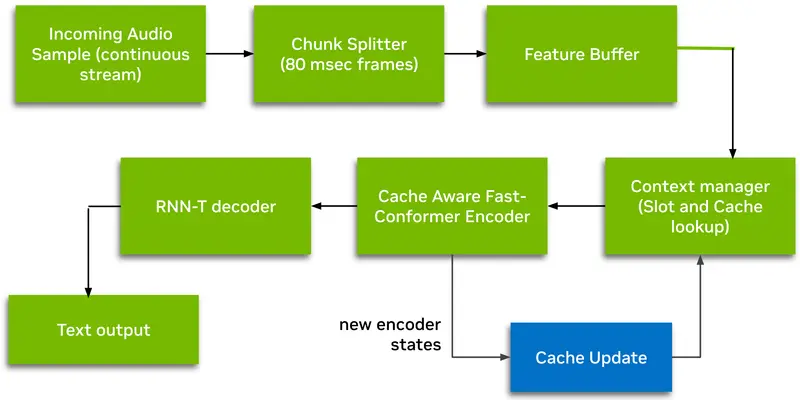
模型架构详解
- 架构名称:FastConformer-CacheAware-RNNT
- 编码器:24 层缓存感知 FastConformer(基于 Conformer 改进)
- 解码器:RNN-T(Recurrent Neural Network Transducer)
- 参数量:600M
- 支持语言:英语(English)
RNN-T 架构天然支持流式输出,无需等待整句结束即可生成部分转录,进一步降低感知延迟。
部署与集成
英伟达已提供多种快速上手路径:
对于希望自托管的团队,模型可通过 NVIDIA NeMo 或 Hugging Face Transformers(适配后)集成到现有语音管线中。
适用场景
✅ 低延迟交互:语音助手、车载语音、智能音箱
✅ 实时辅助:会议字幕、直播转录、无障碍服务
✅ 高吞吐批处理:客服录音转写、语音日志分析、内容审核
✅ 成本敏感型部署:需在有限 GPU 资源下最大化并发能力的场景
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











