在AIGC的众多分支中,歌曲生成因兼具“音乐旋律”“歌词文本”“结构韵律”的多维度创作需求,一直是技术难点。尽管互联网上有海量歌曲资源,但要将这些原始音频转化为可训练AIGC模型的“结构化数据”,传统方式需大量人工标注——比如逐句标记歌词对应音频的时间戳、划分主歌/副歌段落,不仅耗时数月,还容易因主观差异导致标注不一致。
- GitHub:https://github.com/tencent-ailab/songprep
- 模型:https://huggingface.co/tencent/SongPrep-7B
- Demo:https://song-prep.github.io/demo
这种“数据预处理瓶颈”严重制约了歌曲生成模型的发展。为此,腾讯AI实验室提出SongPrep框架及端到端扩展模型SongPrepE2E,通过自动化流水线实现“原始歌曲音频→结构化训练数据”的全流程处理,大幅降低数据准备成本,同时提升下游歌曲生成模型的创作质量。
SongPrep的核心价值:用自动化破解“数据预处理三座大山”
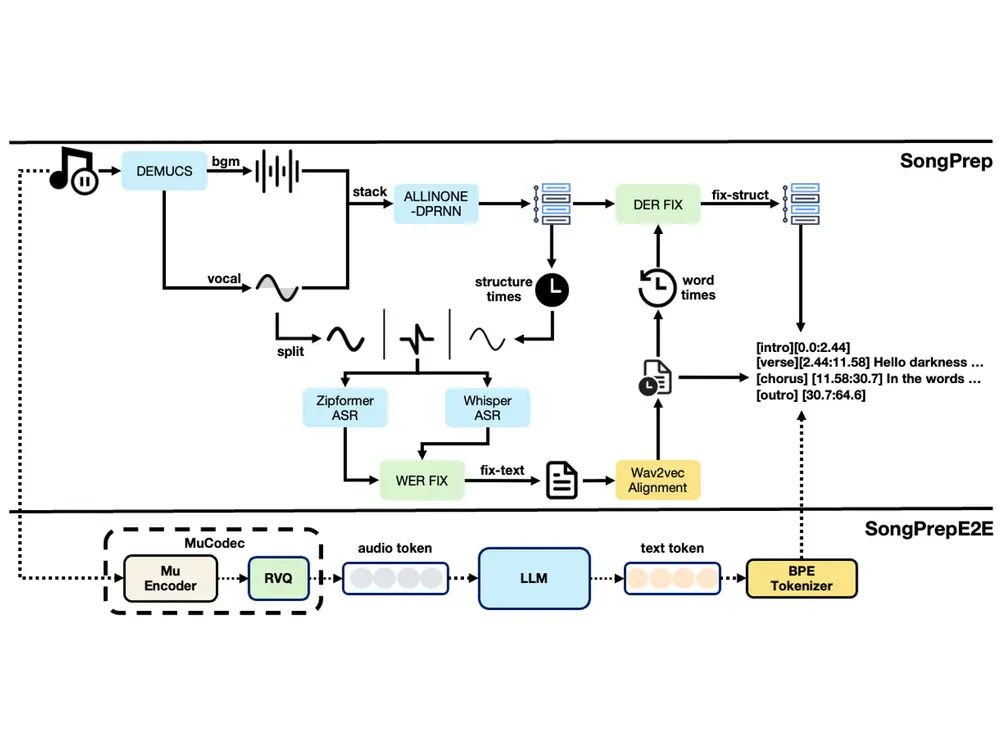
原始歌曲是“人声、乐器、歌词、结构”的混合体,要转化为训练数据,需攻克三个核心难题。SongPrep通过模块化设计,逐一突破这些瓶颈:
| 预处理难题 | 传统人工处理的局限 | SongPrep的自动化解决方案 |
|---|---|---|
| 音源分离 | 难以精准分离人声与乐器,影响后续歌词识别 | 用Demucs模型自动拆分人声、鼓、贝斯、其他乐器四个音轨,为人声提取扫清障碍 |
| 歌曲结构分析 | 人工划分主歌/副歌/桥段耗时且标准不一,误差率高 | 改进的All-In-One模型自动识别歌曲结构,通过DPRNN模块增强全局语义理解,降低分割错误 |
| 歌词识别与对齐 | 手动标记歌词对应音频时间戳效率极低,平均每首歌需1小时 | 结合ASR模型与WER-FIX算法,自动转录歌词并生成精确到毫秒的时间戳 |
例如处理一首流行歌曲时,SongPrep能在几分钟内完成:将“人声+伴奏”分离→识别出“主歌1-副歌-主歌2-副歌-桥段-副歌”的结构→把每句歌词对应到具体音频片段(如“你好吗”对应01:23.456-01:25.123的音频),输出的结构化数据可直接用于训练歌曲生成模型。
技术拆解:从模块化处理到端到端优化
SongPrep的技术演进分为“模块化流水线(SongPrep)”和“端到端升级(SongPrepE2E)”两个阶段,逐步提升处理效率与准确性。
1. SongPrep:三步走的模块化预处理
SongPrep采用“分步骤处理、各模块专攻”的思路,将复杂任务拆解为三个可复用的核心模块:
(1)音源分离:为歌词识别“降噪清场”
歌曲中混杂的乐器声会严重干扰歌词识别,因此第一步是“分离人声与伴奏”:
- 采用预训练的Demucs模型,将原始音频分解为人声、鼓、贝斯、其他乐器四个独立音轨;
- 相比传统分离方法,Demucs能更好保留人声细节(如气音、转音),为人声转录提供“干净素材”。
(2)歌曲结构分析:给歌曲“分段打标”
要让生成的歌曲符合“主歌-副歌”的常规结构,需先让模型学会识别现有歌曲的结构规律:
- 基于改进的All-In-One模型,在原有架构中插入Dual-Path RNN(DPRNN)模块——通过“局部-全局”双重分析,增强模型对长音频中语义关联性的理解(如识别“重复出现的副歌旋律”);
- 自动输出歌曲的结构标签,如“[主歌1]00:15-00:45[副歌]00:46-01:10...”,为后续生成模型提供结构参考。
(3)歌词识别与优化:让“音”与“字”精准对应
从分离出的人声中识别歌词,并对齐到具体时间点,是最核心也最具挑战的一步:
- 先用基于Zipformer的ASR(自动语音识别)模型转录歌词文本,初步得到“歌词-时间戳”对应关系;
- 再通过WER-FIX算法优化结果:结合中文语义规则(如语法通顺性)和常见歌词错误模式(如谐音字混淆),修正转录错误(如将“彼岸”误判为“彼安”);
- 最终输出带精确时间戳的结构化歌词,如“00:20.345 夜空中最亮的星 00:23.678”。
2. SongPrepE2E:端到端升级,跳过“音源分离”更高效
SongPrep虽实现自动化,但多模块串联可能累积误差(如音源分离不彻底会影响歌词识别)。为此,研究团队提出SongPrepE2E端到端模型,直接从完整歌曲音频中提取结构化信息:
(1)技术创新:用“音频标记+LLM”打通全流程
- 先用MuCodec将完整歌曲音频转换为离散音频标记(类似文本的“词向量”,但针对音频特征);
- 将这些标记输入预训练大型语言模型(LLM),同时结合SongPrep生成的高质量结构化数据进行监督微调;
- 微调后的LLM能直接输出“歌曲结构+带时间戳的歌词”,无需单独进行音源分离,减少中间环节的误差传递。
(2)核心优势:效率与准确性双提升
- 省去音源分离步骤,处理速度更快,实时因子(RTF)降低40%(RTF越小,处理效率越高);
- 利用LLM的全局语义理解能力(如结合上下文修正生僻歌词),歌词识别错误率(WER)进一步降低。
实测性能:数据质量与生成效果双重验证
研究团队构建了包含200首歌曲的SSLD-200数据集(带人工精细标注的结构化数据),从“预处理准确性”和“下游生成效果”两方面验证SongPrep的价值。
1. 预处理环节:关键指标全面优于传统方法
- 结构分析:改进的All-In-One模型(SongPrep核心模块)的分割错误率(DER)从25.0%降至16.1%,意味着主歌/副歌等段落的识别更精准;
- 歌词识别:
- 经Demucs分离后,Whisper模型的词错误率(WER)从47.2%(原始音频直接识别)降至27.7%;
- 再经WER-FIX优化,Zipformer ASR模型的WER进一步降至25.8%;
- 端到端优势:SongPrepE2E的DER和WER均优于SongPrep,且处理效率更高,证明端到端方案的先进性。
2. 下游歌曲生成:训练数据质量直接提升创作效果
用SongPrep/SongPrepE2E处理的数据训练歌曲生成模型,在人工评估中(1-5分制)表现显著优于传统方法:
- 音乐性结构:4.12分(传统方法3.58分),生成歌曲的主歌/副歌划分更符合人类创作习惯;
- 歌词匹配度:4.05分(传统方法3.42分),歌词与旋律节奏的契合度更高;
- 主观偏好:68%的测评者认为生成歌曲更接近人类创作水平,显著高于传统方法的39%。
应用场景与开源价值
1. 核心应用:为AIGC歌曲生成“筑基”
SongPrep的直接价值在于降低歌曲生成模型的训练门槛,推动多个应用场景落地:
- 辅助音乐创作:为音乐人提供“结构化素材库”,快速生成符合特定结构、风格的歌曲初稿;
- 个性化歌曲生成:基于用户输入的歌词,生成匹配韵律的旋律,且自动划分主歌/副歌结构;
- 有声内容制作:将散文、诗歌自动转化为带旋律的歌曲,拓展有声内容的表现形式。
2. 开源贡献:SSLD-200数据集推动行业发展
研究团队开源了SSLD-200数据集,包含200首歌曲的:
- 人工标注的精细结构(主歌/副歌/桥段等);
- 带毫秒级时间戳的歌词;
- 分离后的多轨音频。
这一数据集为“结构化歌词识别”领域提供了标准化评估基准,有助于推动相关技术的进一步发展。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











