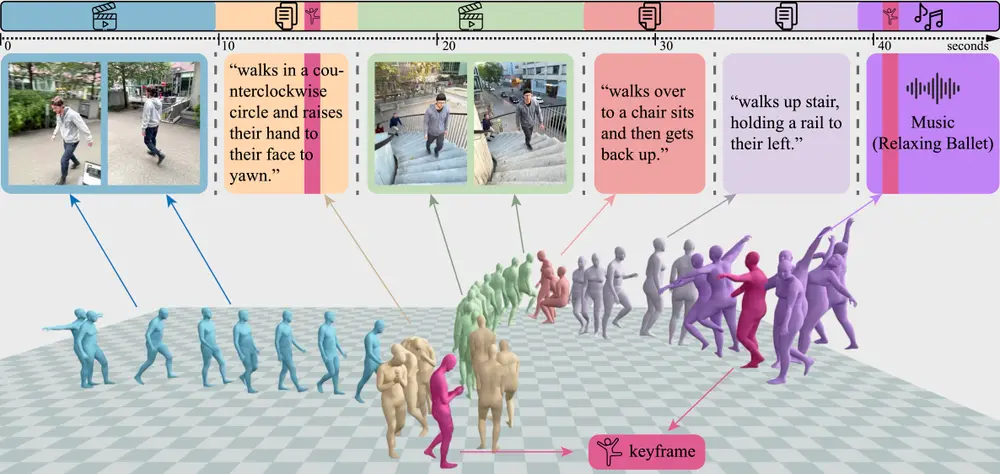
英伟达研究团队开发的统一框架 GENMO,用于人类运动建模。GENMO 的目标是将人类运动估计(estimation)和生成(generation)任务整合到一个框架中,从而实现从视频、2D 关键点、文本描述、音乐和3D 关键帧等多种条件信号中生成和估计高质量的人类运动。例如,GENMO 可以从一段视频中估计出精确的全局运动,或者根据文本描述生成相应的舞蹈动作,甚至可以根据音乐节奏生成舞蹈。
主要功能
GENMO 的主要功能包括:
- 运动估计:从视频中估计出精确的全局人类运动,即使在动态摄像头和遮挡条件下也能保持高精度。
- 运动生成:根据文本描述、音乐或其他条件生成多样化的、逼真的运动序列。
- 多模态融合:支持多种条件信号(如视频、文本、音乐、2D 关键点和3D 关键帧)的组合输入,并生成平滑的过渡。
- 可变长度运动生成:能够生成任意长度的运动序列,而无需复杂的后处理步骤。
主要特点
GENMO 的主要特点如下:
- 统一框架:将运动估计和生成任务整合到一个模型中,通过将运动估计重新定义为受约束的运动生成问题,实现了两者的协同优化。
- 双模式训练:采用估计模式和生成模式的双重训练范式,分别针对运动估计的准确性和运动生成的多样性进行优化。
- 多模态条件支持:能够处理多种类型的条件信号,并在不同时间间隔内灵活组合这些信号。
- 高效生成:通过单次前向扩散过程生成运动序列,无需复杂的后处理步骤。
- 数据利用:利用大规模的2D 视频数据增强生成能力,减少对3D 运动捕捉数据的依赖。
工作原理
GENMO 的工作原理基于以下几个核心组件:
- 运动表示:采用包含全局运动、局部运动和相机姿态的统一运动表示,支持从视频中估计运动和根据条件生成运动。
- 双模式训练:
- 估计模式:通过最大似然估计(MLE)训练模型,以确保运动估计的准确性。
- 生成模式:通过标准的扩散模型训练目标,使模型能够从条件信号中学习丰富的生成分布。
- 多模态融合:通过加性融合块将不同类型的条件信号(如视频、文本、音乐)融合到运动生成过程中。
- 多文本注入:通过多文本注意力机制处理多个文本输入,并将它们限制在指定的时间窗口内,以实现灵活的文本条件运动生成。
- 可变长度运动生成:使用相对位置嵌入和滑动窗口注意力机制,支持生成任意长度的运动序列。
测试结果
GENMO 在多个基准测试中表现出色:
- 运动估计:
- 在 RICH 和 EMDB 数据集上,GENMO 的全局运动估计性能优于现有的专门用于运动估计的方法。
- 在 3DPW 数据集上,GENMO 的局部运动估计性能也优于现有方法,尤其是在处理严重遮挡和截断的情况下。
- 运动生成:
- 在 AIST++ 数据集上,GENMO 的音乐到舞蹈生成性能优于现有的专门方法,展现出更高的运动多样性和音乐相关性。
- 在 HumanML3D 和 Motion-X 数据集上,GENMO 的文本到运动生成性能优于基线模型,尤其是在利用2D 数据进行训练时。
- 运动插值:
- 在运动插值任务中,GENMO 通过其统一的估计和生成训练,实现了优于扩散模型基线的性能。
应用场景
GENMO 的应用场景非常广泛,包括但不限于:
- 游戏开发:快速生成高质量的动画和运动序列,减少人工建模的工作量。
- 虚拟现实(VR)和增强现实(AR):创建逼真的虚拟环境和角色运动。
- 影视制作:生成用于动画和特效的运动序列,提高制作效率。
- 教育和培训:创建用于教学的运动模型和场景。
- 机器人技术:为机器人生成自然和流畅的运动轨迹。
通过其高效的数据处理、高质量的生成结果和灵活的控制能力,GENMO 为人类运动建模领域提供了一个强大的工具,能够显著提升生产效率和创作灵活性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...