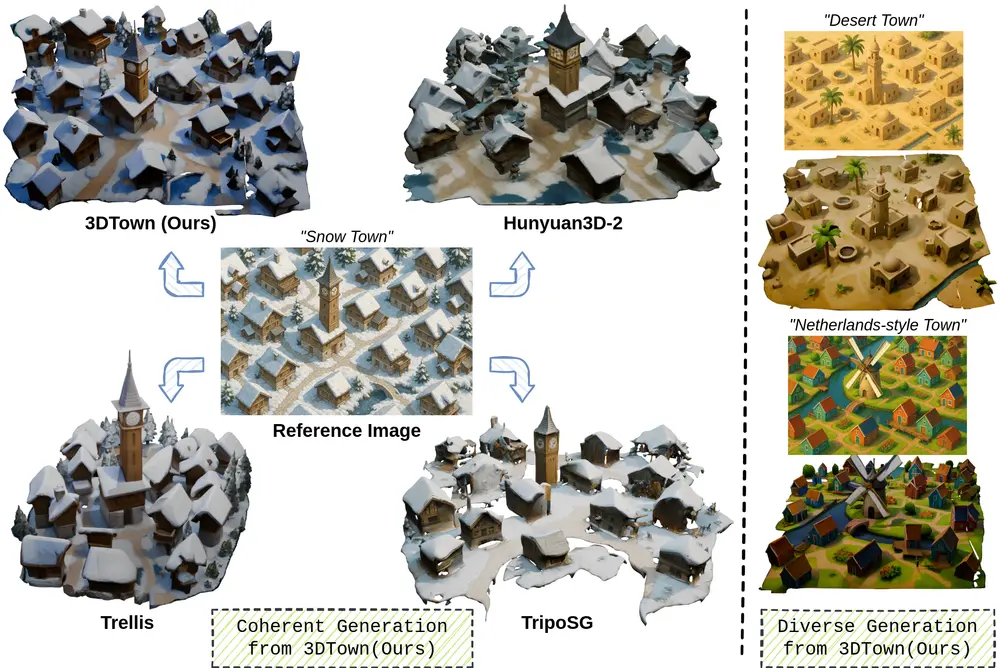
清华大学软件学院、清华大学交叉信息研究所和重庆大学计算机学院的研究人员推出 Vid2World,将预训练的视频扩散模型(Video Diffusion Models)转化为交互式世界模型(Interactive World Models)。世界模型能够基于历史观测和动作序列预测未来状态,对于序列决策任务至关重要。
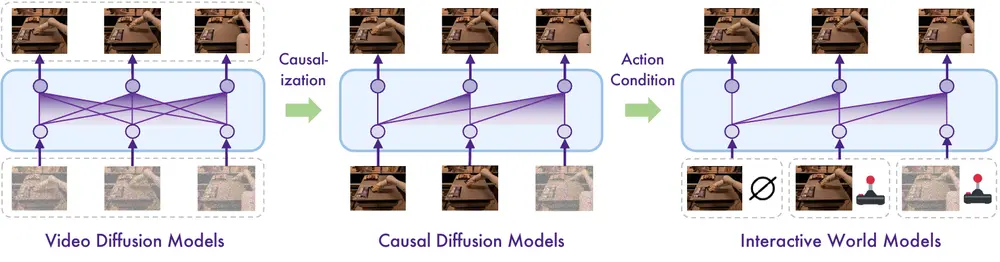
现有的世界模型通常需要大量的特定领域数据进行训练,并且生成的预测结果质量较低、细节粗糙。相比之下,视频扩散模型在大规模互联网数据集上训练,能够生成高质量的视频序列,捕捉真实世界中的多样化动态。Vid2World 通过架构和训练目标的调整,将视频扩散模型转化为能够进行自回归(autoregressive)和动作条件(action-conditioned)生成的交互式世界模型。
主要功能
Vid2World 的主要功能包括:
- 视频预测:能够基于历史帧和动作序列生成未来的视频帧。
- 动作条件生成:支持根据不同的动作输入生成不同的未来状态,实现反事实推理(counterfactual reasoning)。
- 交互式模拟:支持实时用户交互,适用于游戏模拟和机器人控制等场景。
主要特点
- 视频扩散因果化(Causalization of Video Diffusion Models):通过架构调整和训练目标的修改,将非因果的视频扩散模型转化为因果模型,支持自回归生成。
- 因果动作引导(Causal Action Guidance):通过在模型输入中注入动作信号,并在训练中独立丢弃动作,实现分类器自由的动作引导(classifier-free action guidance),增强模型对动作的响应能力。
- 高保真生成:利用预训练的视频扩散模型的强大生成能力,生成高质量、高保真的视频序列。
工作原理
Vid2World 的工作原理基于以下几个关键步骤:
- 视频扩散模型的因果化:
- 架构调整:将双向时间模块(如时间注意力层和非因果卷积层)调整为因果模块,确保信息只能从过去流向未来。
- 训练目标调整:采用独立的噪声水平采样策略(Diffusion Forcing),使模型能够处理不同时间步的噪声水平组合,支持自回归生成。
- 因果动作引导:
- 动作注入:在每个时间步将动作信号通过轻量级嵌入层注入到模型中,使每个帧直接依赖于其前一个动作。
- 独立动作丢弃:在训练中独立丢弃动作,使模型能够学习在有无动作条件下的生成,支持分类器自由的动作引导。
测试结果
Vid2World 在多个领域进行了广泛的实验,包括机器人操作和游戏模拟,显示出显著的性能提升:
- 机器人操作(RT-1 数据集):
- Vid2World 在 Fréchet Video Distance (FVD)、Fréchet Image Distance (FID)、Structural Similarity Index Measure (SSIM)、Learned Perceptual Image Patch Similarity (LPIPS) 和 Peak Signal-to-Noise Ratio (PSNR) 等指标上均优于其他方法。
- Real2Sim Policy Evaluation:Vid2World 能够可靠地反映不同策略的成功率,与真实世界的结果高度一致。
- 游戏模拟(CS:GO 数据集):
- Vid2World 在所有评估指标上均优于 DIAMOND 方法,包括 FVD 和 FID,显示出更高的视觉保真度和语义一致性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











